Import existing blog posts
This commit is contained in:
@@ -7,7 +7,13 @@ import * as opml from 'opml';
|
|||||||
export default function (eleventyConfig) {
|
export default function (eleventyConfig) {
|
||||||
eleventyConfig.setInputDirectory("src")
|
eleventyConfig.setInputDirectory("src")
|
||||||
eleventyConfig.addPlugin(pugPlugin);
|
eleventyConfig.addPlugin(pugPlugin);
|
||||||
eleventyConfig.addPlugin(eleventyImageTransformPlugin);
|
eleventyConfig.addPlugin(eleventyImageTransformPlugin, {
|
||||||
|
htmlOptions: {
|
||||||
|
imgAttributes: {
|
||||||
|
alt: '',
|
||||||
|
},
|
||||||
|
},
|
||||||
|
});
|
||||||
eleventyConfig.addPlugin(EleventyRenderPlugin);
|
eleventyConfig.addPlugin(EleventyRenderPlugin);
|
||||||
eleventyConfig.addPassthroughCopy("src/assets/**")
|
eleventyConfig.addPassthroughCopy("src/assets/**")
|
||||||
|
|
||||||
@@ -18,7 +24,7 @@ export default function (eleventyConfig) {
|
|||||||
for ( const post of posts ) {
|
for ( const post of posts ) {
|
||||||
const year = post.date.getFullYear()
|
const year = post.date.getFullYear()
|
||||||
if ( !postsByYear[year] ) postsByYear[year] = []
|
if ( !postsByYear[year] ) postsByYear[year] = []
|
||||||
postsByYear[year].push(post)
|
postsByYear[year] = [post, ...postsByYear[year]]
|
||||||
if ( !years.includes(year) ) years.push(year)
|
if ( !years.includes(year) ) years.push(year)
|
||||||
}
|
}
|
||||||
|
|
||||||
|
|||||||
@@ -224,6 +224,7 @@ img {
|
|||||||
|
|
||||||
.blog.content-wrapper img {
|
.blog.content-wrapper img {
|
||||||
height: auto !important;
|
height: auto !important;
|
||||||
|
margin-top: 25px;
|
||||||
}
|
}
|
||||||
|
|
||||||
center {
|
center {
|
||||||
|
|||||||
@@ -7,7 +7,7 @@ block blog_content
|
|||||||
|
|
||||||
.recent-posts
|
.recent-posts
|
||||||
ul.plain
|
ul.plain
|
||||||
each post in collections.blog.slice(0, 10)
|
each post in collections.blog.reverse().slice(0, 5)
|
||||||
li
|
li
|
||||||
.secondary #{post.data.date.toISOString().split('T')[0]}
|
.secondary #{post.data.date.toISOString().split('T')[0]}
|
||||||
a.title(href=post.url) #{post.data.title}
|
a.title(href=post.url) #{post.data.title}
|
||||||
|
|||||||
174
src/blog/posts/2015-10-24-kali-usb.md
Normal file
174
src/blog/posts/2015-10-24-kali-usb.md
Normal file
@@ -0,0 +1,174 @@
|
|||||||
|
---
|
||||||
|
layout: blog_post
|
||||||
|
title: Installing Kali Linux from USB
|
||||||
|
slug: Installing-Kali-Linux-from-USB
|
||||||
|
date: 2015-10-24 00:01:00
|
||||||
|
tags: blog
|
||||||
|
permalink: /blog/2015/10/24/Installing-Kali-Linux-from-USB/
|
||||||
|
blogtags:
|
||||||
|
- kali
|
||||||
|
- linux
|
||||||
|
- tutorial
|
||||||
|
---
|
||||||
|
|
||||||
|
Linux. When most people think about Linux, they envision hackers and scrolling lines of code; however, today there are many modern Linux distributions (brands, if you will) that offer modern user interfaces and compatible software. These distributions are designed for the end-user; modern, daily driver operating systems. Kali Linux is not among these.
|
||||||
|
|
||||||
|
To quote the Kali Documentation, “**Kali Linux** is the new generation of the industry-leading BackTrack **Linux** penetration testing and security auditing **Linux** distribution. **Kali Linux** is a complete re-build of BackTrack from the ground up, adhering completely to Debian development standards.”
|
||||||
|
|
||||||
|
Basically, Kali is the ultimate OS for ethical hackers. It contains tools for secure penetration testing. Basically, it is used to test how secure “secure” systems really are. It is a good way to get into the more advanced functions of computers and networks. If this piques your interest, then stick around. In this tutorial I will be documenting how to write the installer to a USB drive and install Kali Linux to the hard drive or a partition (more on that later).
|
||||||
|
|
||||||
|
Side Note: For those of you using VirtualBox or similar, set the Type to Linux and the Version to Oracle (either 64 or 32 bit based on your operating system).
|
||||||
|
|
||||||
|
### Materials Needed:
|
||||||
|
|
||||||
|
* USB Flash Drive (4gb or greater)
|
||||||
|
|
||||||
|
* An Internet Connection
|
||||||
|
|
||||||
|
* Windows or Linux Computer
|
||||||
|
|
||||||
|
* A Bit of Patience
|
||||||
|
|
||||||
|
### Step 1: Downloading Kali
|
||||||
|
|
||||||
|
To install Kali, we will boot from an install disc turned USB drive. First, we need the installer ISO. Download this from:
|
||||||
|
[**Kali Linux Downloads**
|
||||||
|
*Download Kali Linux Images We generate fresh Kali Linux image files every few months, which we make available for…*www.kali.org](https://www.kali.org/downloads/)
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Be sure to select 64/32 bit based on your system.
|
||||||
|
|
||||||
|
### Step 2a: Formatting the USB Drive (Windows)
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
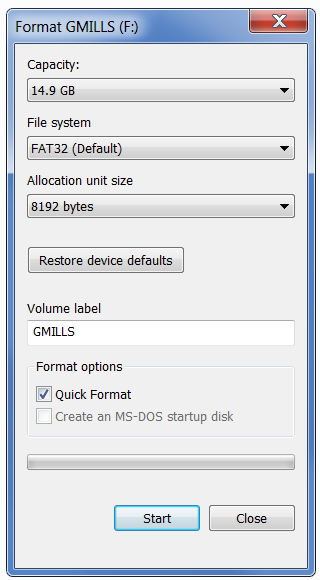
To format the USB drive on a Windows computer, insert the drive and remove any files you want to keep. Right click on the drive and click format. For the file system, select FAT32.
|
||||||
|
|
||||||
|
Quick format is fine, unless the drive was in a different format than FAT or NTFS. Then deselect this option.
|
||||||
|
|
||||||
|
### Step 2b: Formatting the USB Drive (Linux)
|
||||||
|
|
||||||
|
For this, we will be using gparted. If you don’t have it, it is available in the default repos on most distributions. Simply issue the installation command.
|
||||||
|
|
||||||
|
Ubuntu & Derivatives:
|
||||||
|
|
||||||
|
**sudo apt-get install gparted**
|
||||||
|
|
||||||
|
Fedora & Derivatives:
|
||||||
|
|
||||||
|
**sudo yum install gparted**
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
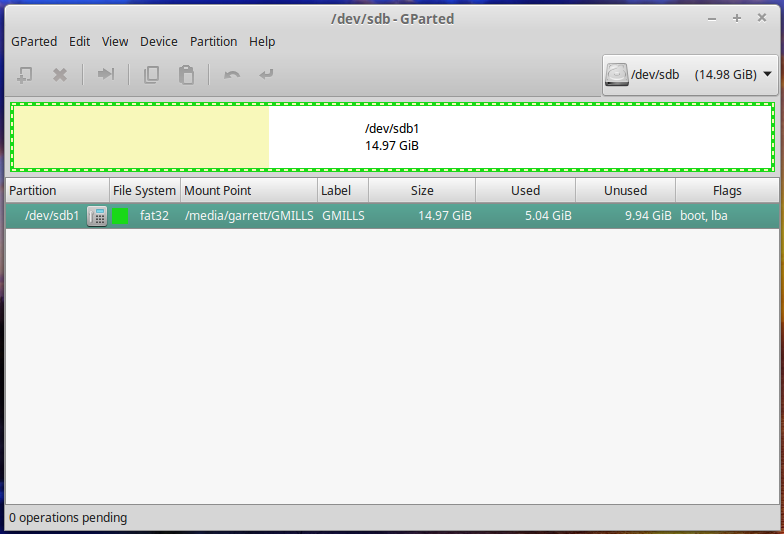
Plug in your drive and open gparted. In the top right corner, and select the /dev/sdb object. Right click the main partition and click unmount.
|
||||||
|
|
||||||
|
Under the device menu, select ‘Create Partition Table’ and approve it. You will then see that the drive has been converted to unallocated space. Right click the space, select new.
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
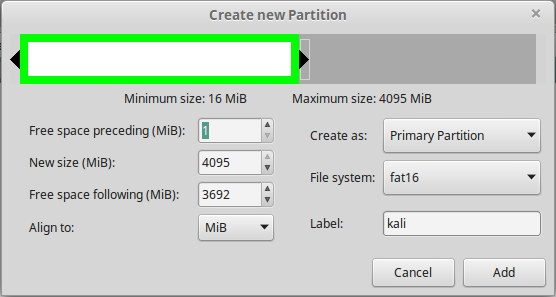
Change the file system type to FAT16. THIS IS IMPORTANT.
|
||||||
|
|
||||||
|
Pick a label and click add. Press Ctrl+Enter to apply the operation.
|
||||||
|
|
||||||
|
### Step 3: Writing the Installer to the USB
|
||||||
|
|
||||||
|
To write the Installation ISO to the USB drive, we will use a program called unetbootin.
|
||||||
|
|
||||||
|
Windows — Download from here:
|
||||||
|
[**UNetbootin**
|
||||||
|
*UNetbootin allows you to create bootable Live USB drives for Ubuntu and other Linux distributions without burning a CD…*unetbootin.github.io](http://unetbootin.github.io/)
|
||||||
|
|
||||||
|
Linux — Available in most repositories.
|
||||||
|
|
||||||
|
Ubuntu & co:
|
||||||
|
|
||||||
|
**sudo apt-get install unetbootin**
|
||||||
|
|
||||||
|
Fedora & co:
|
||||||
|
|
||||||
|
**sudo yum install unetbootin**
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
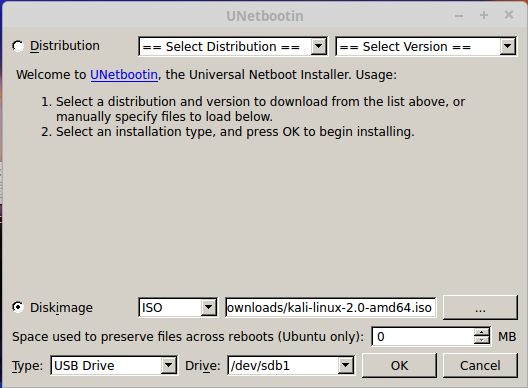
Open the program and select your newly formatted USB drive, as well as the downloaded ISO.
|
||||||
|
|
||||||
|
Click OK to begin the process. When it finishes, it will ask you to reboot your computer.
|
||||||
|
|
||||||
|
Now the fun starts.
|
||||||
|
|
||||||
|
### Step 5: Boot
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
Plug the USB installer into the computer you are installing Kali on. When booting the computer, repeatedly press the trigger key to enter the boot option menu (usually F12), and select the USB drive.
|
||||||
|
|
||||||
|
You will then see the Unetbootin bootloader menu. Select the Live Boot option for Kali Linux.
|
||||||
|
|
||||||
|
### Step 6: Partitioning
|
||||||
|
|
||||||
|
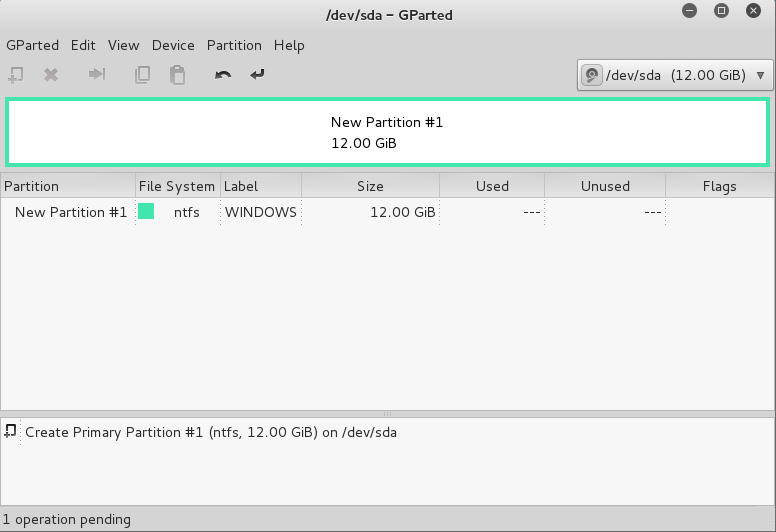
If you plan to dual-boot Kali with another OS, you will need to partition the drive to create space for both operating systems. If you are installing Kali by itself, skip this section. On the GNOME3 toolbar, click Show All Applications, and launch gparted.
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
You should get a window looking (more or less) like this (left).
|
||||||
|
|
||||||
|
Right click on the existing partition, and click Resize/Move.
|
||||||
|
|
||||||
|
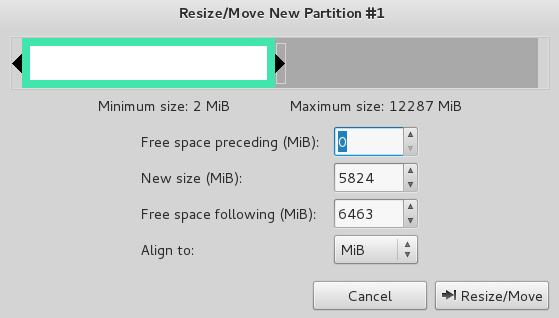
**NOTE: If you are dual booting Windows with Kali, it is important that you defragment all disks prior to re-sizing the partition, or some files may be lost.**
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
Adjust the partition size to create space for Kali. Kali needs about 10GB for a minimal install with some file storage. Obviously the sizes in this picture (left) are not accurate. Hit resize/move to apply.
|
||||||
|
|
||||||
|
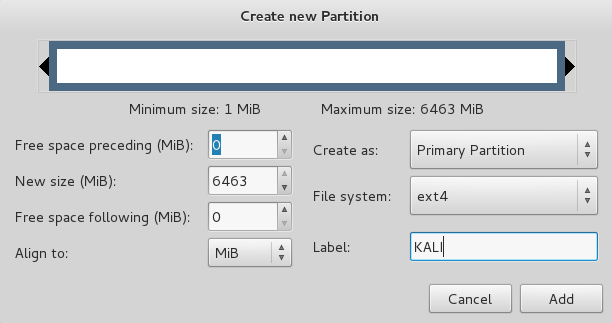
|
||||||
|
|
||||||
|
Right click on the new unallocated space, click NEW and create a partition, making sure the Type is ext4.
|
||||||
|
|
||||||
|
Next, press Ctrl+Enter to apply the changes.
|
||||||
|
|
||||||
|
### Step 7: Install
|
||||||
|
|
||||||
|
Next, click show applications in the GNOME3 toolbar, and search for install. Launch the application Install Kali. This will launch a graphical wizard installer.
|
||||||
|
|
||||||
|
Note: If your installer looks like this (left), and you cannot see all of it, do not fret. Simply press the Windows button to open the GNOME menu, then drag the installer from the current workspace to a new one.
|
||||||
|
|
||||||
|
**NOTE: If the Kali installer locks itself due to inactivity, the password is toor (root backwards).**
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
Basically, point and click your way through Location, Language, and Keyboard, and after a bit of loading, you will see a screen asking you to supply a domain name.
|
||||||
|
|
||||||
|
This is the domain name the system will use by default (akin to localhost). If you are confused, or don’t have one, just leave this blank.
|
||||||
|
|
||||||
|
Set a strong root password, and breeze through the time zone, and it is time to configure the disks.
|
||||||
|
|
||||||
|
### Step 4: Partitioning
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
At this point you will see a asking you to configure disks. Click manual and then continue and you will see this screen (left).
|
||||||
|
|
||||||
|
The middle section is a list of all recognized storage drives. If you have already configured your partition, skip this next part.
|
||||||
|
|
||||||
|
Click on the partition you created in step 6 and click continue.
|
||||||
|
|
||||||
|
If you reach a screen asking you to create a new partition table, click yes if you are using Kali by itself, no if you are dual-booting then click continue.
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
On the next screen, you will see a list of all devices and partitions, including your created partition, or FREE SPACE if you are installing on a single OS computer. Click on the desired partition and click continue.
|
||||||
|
|
||||||
|
If you are asked to create a new partition, simply point and click through the wizard until you see this next screen:
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
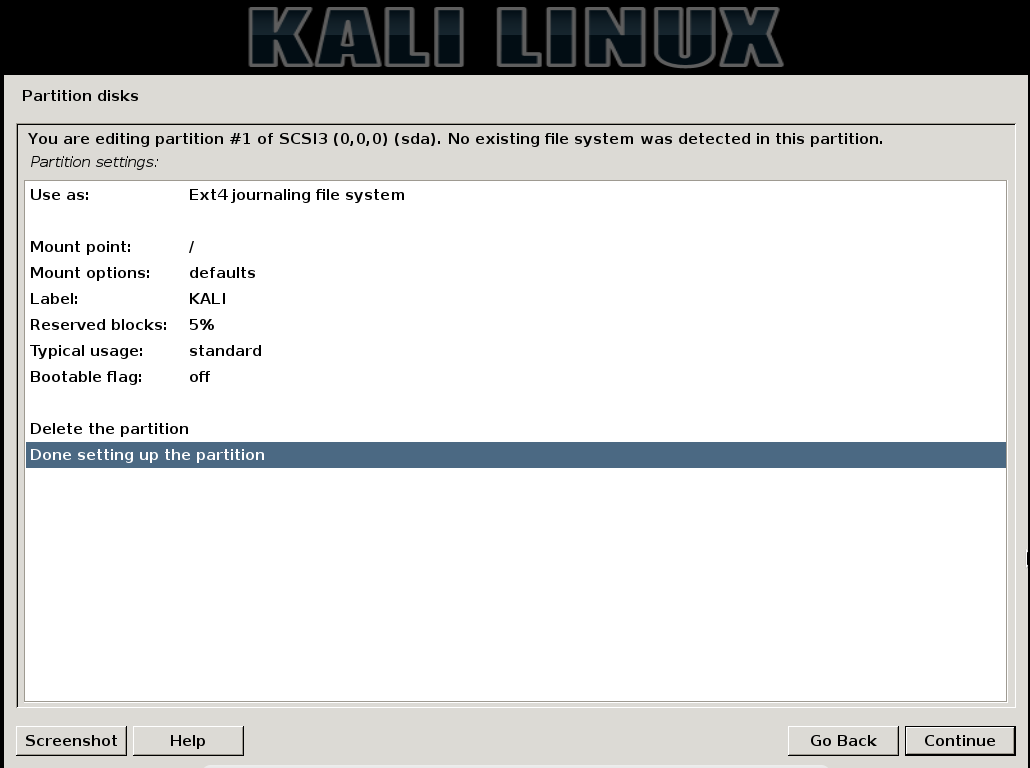
On this screen, make sure it is set to Ext4 journaling file system. Set the mount point to / and label it something. Click “Done setting up the partition” and Continue to move on to the next step.
|
||||||
|
|
||||||
|
This will take you to the previous screen, with your new partition. Verify it is correct, then select “Finish partitioning…” and click Continue.
|
||||||
|
|
||||||
|
You will be prompted with a screen requesting you to make a swap partition. Click NO and continue. On the next screen, it will confirm that the changes be written to the disk. Click YES and Continue. Shortly after this, it will install the system to the HDD. Simply point and click through the remainder of the wizard, and when it is installed, simply reboot. Take care to remove the USB drive first.
|
||||||
|
|
||||||
|
Note — After install, if Kali doesn’t appear in the GRUB bootloader for your current system, open your current Linux system and issue the following command:
|
||||||
|
|
||||||
|
**sudo update-grub**
|
||||||
91
src/blog/posts/2018-02-22-ubuntu-onedrive.md
Normal file
91
src/blog/posts/2018-02-22-ubuntu-onedrive.md
Normal file
@@ -0,0 +1,91 @@
|
|||||||
|
---
|
||||||
|
layout: blog_post
|
||||||
|
title: OneDrive Sync for Linux (Ubuntu)
|
||||||
|
slug: OneDrive-Sync-for-Linux-Ubuntu
|
||||||
|
date: 2018-02-22 00:01:00
|
||||||
|
tags: blog
|
||||||
|
permalink: /blog/2018/02/22/OneDrive-Sync-for-Linux-Ubuntu/
|
||||||
|
blogtags:
|
||||||
|
- onedrive
|
||||||
|
- linux
|
||||||
|
- tutorial
|
||||||
|
---
|
||||||
|
So, a while back I decided to make the switch back to the Dark Side and moved all of my computers back to Windows 10 Pro from Ubuntu. My primary motivation for this was because I needed to use the Adobe Creative suite for project. After the project was completed, I just sort of stuck with Windows, largely out of complacency, but also because the Anniversary Update introduced a few really awesome features. The most useful of these was replacing the default Desktop/Documents/Pictures folders with OneDrive folders.
|
||||||
|
|
||||||
|
So, when I switched back to Ubuntu recently (mostly so I could use KDE Connect), I tried to find a OneDrive client that would do the same things. Unsurprisingly, no first-party client exists from our Microsoft overlords, and there is a stunning lack of third-party clients. However, thanks to a project called onedrive-d, I got it working. Here’s how.
|
||||||
|
|
||||||
|
(For the lazy among you, [here’s an automatic script.](https://gist.github.com/glmdev/6ab5bbdfde5da3b065eba3fb38f91c24))
|
||||||
|
|
||||||
|
## Step 1: Install onedrived
|
||||||
|
|
||||||
|
onedrived is a third-party, CLI-based OneDrive client created by Xiangyu Bu. It provides basic OneDrive sync. Clean and simple.
|
||||||
|
|
||||||
|
Install git if you don’t have it:
|
||||||
|
```shell
|
||||||
|
sudo apt install git -y
|
||||||
|
```
|
||||||
|
Clone the onedrive-d files to a hidden folder:
|
||||||
|
|
||||||
|
```shell
|
||||||
|
git clone [https://github.com/xybu/onedrived-dev.git](https://github.com/xybu/onedrive-d-old.git) ~/.odd
|
||||||
|
cd ~/.odd
|
||||||
|
```
|
||||||
|
Run the Installer:
|
||||||
|
|
||||||
|
```shell
|
||||||
|
sudo python3 ./setup.py install
|
||||||
|
```
|
||||||
|
|
||||||
|
## Step 2: Install ngrok
|
||||||
|
|
||||||
|
ngrok is a 3rd-party platform for relaying webhook integration. onedrived uses ngrok to allow webhook requests from the OneDrive API to the onedrived client without requiring port-forwarding or similar.
|
||||||
|
|
||||||
|
Download ngrok from [here](https://ngrok.com/download) and extract the ngrok file. Then, copy it to a path directory using the following command:
|
||||||
|
|
||||||
|
`sudo mv ~/path/to/extracted/ngrok /usr/bin/ngrok`
|
||||||
|
|
||||||
|
## Step 3: Configure onedrived
|
||||||
|
|
||||||
|
After installing onedrived, you need to authorize it to access your Microsoft account. To do this, run the following command to configure onedrived interactively:
|
||||||
|
|
||||||
|
`onedrived-pref account add`
|
||||||
|
|
||||||
|
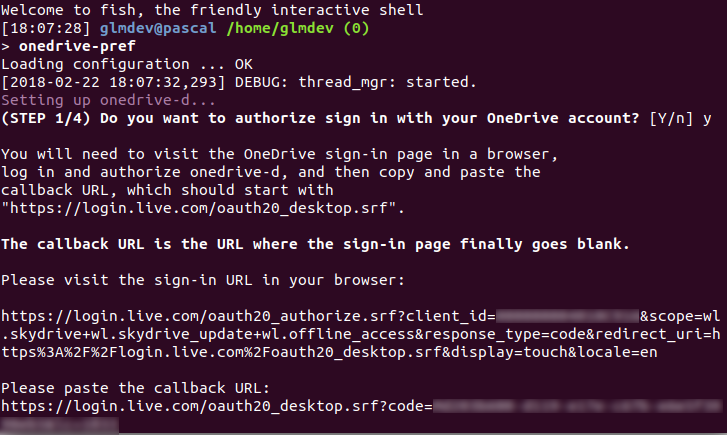
|
||||||
|
|
||||||
|
This command will launch an interactive wizard to help you configure onedrived. First, copy the given URL into your browser of choice and complete the Microsoft login and permissions. After you allow onedrived access, it will land you on a blank white page. Copy the URL of this page, paste it back into the interactive prompt.
|
||||||
|
|
||||||
|
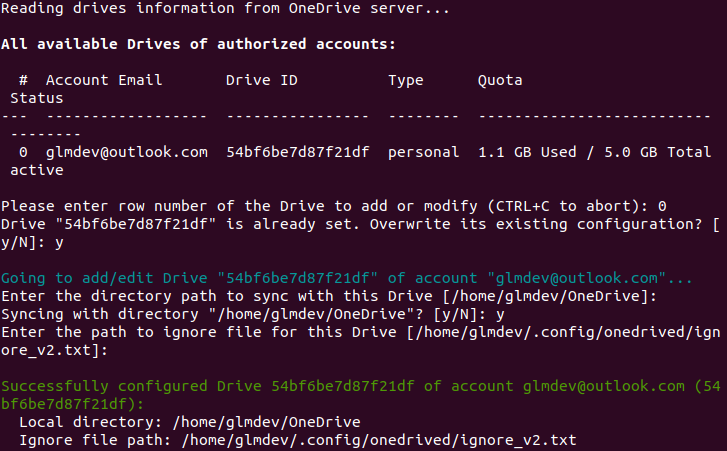
|
||||||
|
|
||||||
|
Now, you need to select which virtual drive to use with onedrived. Set the virtual drive by running the following command:
|
||||||
|
|
||||||
|
`onedrived-pref drive set`
|
||||||
|
|
||||||
|
It will run you through some interactive setup questions. Leave the default directory path the same, tell it y to sync that directory, and leave the default ignore file.
|
||||||
|
|
||||||
|
Lastly, you can start the OneDrive daemon by running:
|
||||||
|
|
||||||
|
`onedrived start`
|
||||||
|
|
||||||
|
At this point, onedrived will begin syncing your OneDrive files with the local computer. This may take some time if you have a particularly large OneDrive. You can access the files by navigating to Home > OneDrive.
|
||||||
|
|
||||||
|
This, however, isn’t as seamless as Microsoft’s implementation. For that, we need to change the default folders that Nautilus uses. To do this, open the user’s directory configuration file using the following command:
|
||||||
|
|
||||||
|
`gedit ~/.config/user-dirs.dirs`
|
||||||
|
|
||||||
|
The user-dirs.dirs file tells GNOME/Nautilus which folders to use for the default Desktop/Documents/Pictures/etc. folders. Change the default paths to their respective OneDrive folders (make sure you’ve created the folders on your OneDrive) like so:
|
||||||
|
|
||||||
|
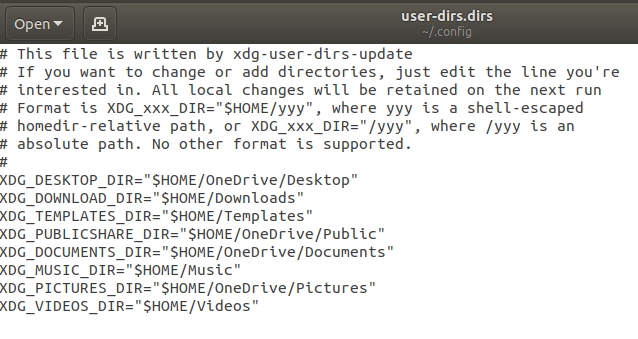*You can pick which folders you want to sync over OneDrive and which ones you want to use locally. In this case, I’ve chosen to sync my Desktop, Public, Documents, and Pictures folders.*
|
||||||
|
|
||||||
|
Finally, run the following command to ensure your changes are preserved:
|
||||||
|
|
||||||
|
`echo "enabled=false" > ~/.config/user-dirs.conf`
|
||||||
|
|
||||||
|
## Step 3: Enable the OneDrive Daemon on Login
|
||||||
|
|
||||||
|
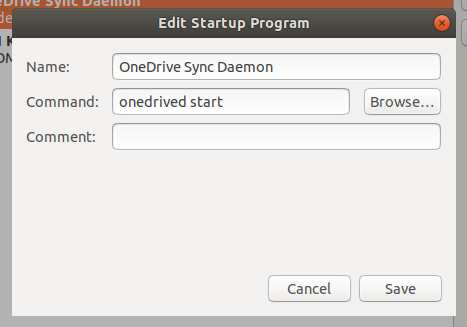
|
||||||
|
|
||||||
|
The onedrive-d daemon doesn’t automatically start by itself, so to ensure that OneDrive starts syncing automatically when you log in, we need to tell GNOME to start it on login. Run the gnome-session-properties command to open GNOME’s configuration. Then, add a startup program to run the onedrived start command.
|
||||||
|
|
||||||
|
Finally, log out and log back in to restart Nautilus and from now on, GNOME and Nautilus should seamlessly sync with your OneDrive.
|
||||||
|
|
||||||
|
|
||||||
196
src/blog/posts/2018-07-07-gluster-on-zfs.md
Normal file
196
src/blog/posts/2018-07-07-gluster-on-zfs.md
Normal file
@@ -0,0 +1,196 @@
|
|||||||
|
---
|
||||||
|
layout: blog_post
|
||||||
|
title: A Noob's Guide to Gluster on ZFS
|
||||||
|
slug: A-Noob-s-Guide-to-Gluster-on-ZFS
|
||||||
|
permalink: /blog/2018/07/07/A-Noob-s-Guide-to-Gluster-on-ZFS/
|
||||||
|
tags: blog
|
||||||
|
date: 2018-07-07 01:00:00
|
||||||
|
blogtags:
|
||||||
|
- gluster
|
||||||
|
- zfs
|
||||||
|
- linux
|
||||||
|
- tutorial
|
||||||
|
---
|
||||||
|
|
||||||
|
# A Noob’s Guide to Gluster on ZFS
|
||||||
|
|
||||||
|
I run a Dell PowerEdge R710 with effectively 680GB of RAID storage. However, over the years, I’ve added on to my network, and as a result have needed more storage. My haphazard solution for this was to just add additional storage machines I have lying around for things like the network backup server and media storage, but this isn’t very… elegant. Aside from the fact that my data are not centrally accessible, it also means that I have to have between 3 and 5 network shares mounted at any given point.
|
||||||
|
|
||||||
|
So, I embarked on a mission to combine my various network storage boxes into one big SAMBA share using GlusterFS. But, I found that the documentation for getting into this, especially for we beginners, is a bit sparse, so I decided to chronicle my journey here.
|
||||||
|
|
||||||
|
## Part 1: The Hardware
|
||||||
|
|
||||||
|
Before we can begin software-linking storage together, we need to have physical storage in the first place. Luckily, Gluster and ZFS are pretty flexible with the hardware they can utilize, so there’s *some *leniency in designing your system. Here’s mine:
|
||||||
|
|
||||||
|
### Server 1: Violet
|
||||||
|
|
||||||
|
Violet is the original NAS. It has 6x146GB SAS drives running in an actual, physical, yes-they-still-exist hardware RAID. I will be including this server by creating a folder in the RAID volume and adding that to the GlusterFS volume.
|
||||||
|
|
||||||
|
### Server 2: Archimedes
|
||||||
|
|
||||||
|
Archimedes is an old HP tower that I’d formerly re-purposed as a media server. Aside from its 80GB boot disk, it has 3x250GB hard drives running in it, which we will be using with ZFS.
|
||||||
|
|
||||||
|
### Server 3: Newton
|
||||||
|
|
||||||
|
Newton is also fashioned from an old HP tower I had lying around. The drive setup here is a bit interesting, though. It too has an 80GB boot drive, but instead of 3x250GB drives, it has 2x250GB drives and 1x320GB drive. This is mostly because I’m cheap and didn’t want to buy another 250GB drive. The beauty of ZFS, however, is that it can use mismatched drive sizes, but each drive behaves as though it were the capacity of the smallest drive. So, it will effectively become a 3x250GB setup, but more on that later.
|
||||||
|
|
||||||
|
## Part 2: The OS
|
||||||
|
|
||||||
|
There has been a lot of drama in the GNU/Linux community in the past over the state of ZFS. Operated by Oracle, for a period around the mid-2010s, ZFS only *really* ran well on Oracle’s server OS, Solaris. The Linux versions of ZFS were buggy, out-of-date, and generally not very reliable. However, in recent years, thanks to a community effort to further develop the software, ZFS support on traditional Linux platforms has become basically indistinguishable from Solaris.
|
||||||
|
|
||||||
|
Which is why, for this project, we’ll be installing Ubuntu Server 18.04 LTS on all the machines. It supports the latest versions of both Gluster and ZFS, and the long-term support ensures stability and updates for years to come.
|
||||||
|
|
||||||
|
So, do a fresh install of Ubuntu Server on each machine’s boot disk (*not* the ZFS storage disks), run updates, and let’s get to the fun stuff.
|
||||||
|
|
||||||
|
One thing to note is that, during the Ubuntu Server install, **I highly recommend setting *static *IP addresses for the different servers** so they don’t change between reboots. This can mess up Gluster’s ability to find the other servers.
|
||||||
|
|
||||||
|
## Part 3: ZFS!
|
||||||
|
|
||||||
|
Now for the fun part. I imagine if you made it this far, you probably have some idea of how ZFS works, but here’s a quick rundown. ZFS is a software RAID-style storage utility that makes use of physical drives to create cross-disk redundant storage pools.
|
||||||
|
|
||||||
|
First, we need to install ZFS. On Ubuntu, this is as simple as running:
|
||||||
|
|
||||||
|
`sudo apt install zfsutils-linux -y`
|
||||||
|
|
||||||
|
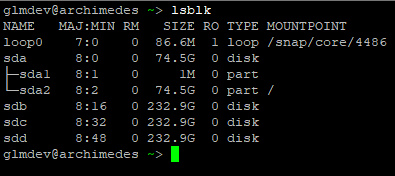
Now, we need to identify the drives we are going to use. To do this, log (or SSH) in to the first server and run lsblk to view the drives.
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
Using the output, identify the drive names for the ZFS storage drives. In my case, these are /dev/sdb, /dev/sdc, and /dev/sdd.
|
||||||
|
|
||||||
|
Next, we have to decide what sort of redundancy to use. In my case, I want to use a 1-drive redundancy on each individual server, then use Gluster to pool all the storage together. This means that, on any server, a single drive can fail, and the whole system will continue to run, but the Gluster pool has no server-by-server redundancy (meaning that a failed server will make at least some of the Gluster data inaccessible). This obviously isn’t the most data-secure system, but for my purposes, it’s “good enough” that I’m not concerned in the day-to-day.
|
||||||
|
|
||||||
|
### Creating the ZFS Pool
|
||||||
|
|
||||||
|
Now we can create the actual ZFS pool. We are going to be using ZFS’ RAID-Z format. This is a single-drive parity format that will give us 1 drive of redundancy. (for my 3x250GB machines, this amounts to about 465GB of usable space) To do this, run:
|
||||||
|
|
||||||
|
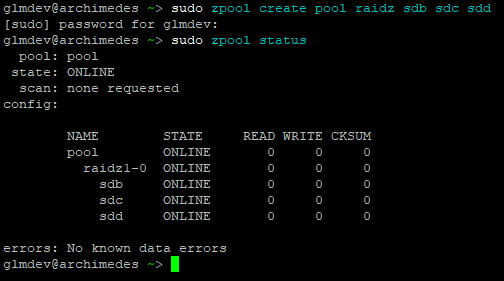
`sudo zpool create pool raidz sdb sdc sdd`
|
||||||
|
|
||||||
|
Where “pool” is the name of the pool (you can name it whatever you want), “raidz” is the format, and that is followed by our drives. The zpool command always has to be run as root.
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
After creating the pool, run sudo zpool status to view (*gasp*) the status. This is also how you can check if drives in the pool have failed.
|
||||||
|
|
||||||
|
By default, ZFS mounts the pool in the root directory. So, in my case, the ZFS pool is mounted at /pool.
|
||||||
|
|
||||||
|
Repeat this process, creating ZFS pools, for each of the servers you intend to use in the Gluster volume.
|
||||||
|
> Note: if you are using drives of different sizes, the zpool command will complain about it. To override this, pass it the -f argument like so:
|
||||||
|
> `sudo zpool create pool raidz sdb sdc sdd -f`
|
||||||
|
|
||||||
|
## Part 4: Gluster
|
||||||
|
|
||||||
|
Finally! We can install Gluster and get our monster network drive online! Well, almost. First we have to do some…
|
||||||
|
|
||||||
|
### Pre-configuration
|
||||||
|
|
||||||
|
Gluster relies on resolvable host-names to find the other servers it needs to talk to. This means that when you run ping server1 or whatever the name of your server is, it needs to actually resolve to that server’s IP address. This is why I suggested setting static IP addresses during the OS install.
|
||||||
|
|
||||||
|
There are a few ways of achieving this. For my network, I am using a local-network DNS server. I just manually assigned the host-names to the static IP addresses, and since all the servers use the local DNS server to resolve names, they can find each other. If you don’t have a local DNS server, don’t fret, there is another way.
|
||||||
|
|
||||||
|
We are going to edit the /etc/hosts files on each server to map the host names of the other servers to their IP addresses. On each server, open the hosts file in your favorite editor of choice, like so:
|
||||||
|
|
||||||
|
*Note: you don’t need to add the address of the server the /etc/hosts file resides on.*
|
||||||
|
|
||||||
|
`sudo nano /etc/hosts`
|
||||||
|
|
||||||
|
Add the storage server’s static IP addresses, as well as their host names to this file. Save it, close it, and repeat this process for each server you intend to put in the Gluster volume.
|
||||||
|
|
||||||
|
Now, we need to install the latest GlusterFS software.
|
||||||
|
|
||||||
|
I’ve found that the version of Gluster that is packages in the Ubuntu 18.04 LTS repositories is outdated (largely because the Canonical team refuses to consult the Gluster team on version choices, but whatever). To address this, we’re going to add the [Gluster PPA](https://launchpad.net/~gluster/+archive/ubuntu/glusterfs-4.1) before installing the GlusterFS software.
|
||||||
|
|
||||||
|
`sudo add-apt-repository ppa:gluster/glusterfs-4.1 && sudo apt update`
|
||||||
|
|
||||||
|
As of July 2018, GlusterFS 4.1 is the latest build for Ubuntu. Now, we can install the software:
|
||||||
|
|
||||||
|
`sudo apt install glusterfs-server -y`
|
||||||
|
> Note: if, like me, one of your servers is using hardware RAID, simply create a folder in the root drive of that server and mount the RAID drive to that folder. Gluster may complain about it, but it will work.
|
||||||
|
|
||||||
|
### Creating the Gluster Volume
|
||||||
|
|
||||||
|
GlusterFS relies on “peers” to access and store data across servers. To set this up, we need to connect the peers together.
|
||||||
|
> Note: Unless otherwise noted, the rest of the commands from here on only need to be run on one of the servers in the Gluster group, not all of them.
|
||||||
|
|
||||||
|
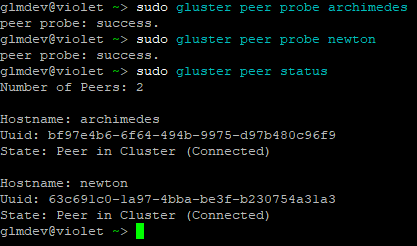
Add the peers by running this command once for each of the servers:
|
||||||
|
|
||||||
|
`sudo gluster peer probe <server hostname>`
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
Then, you can check to make sure the peers were added and joined the cluster by running:
|
||||||
|
> `sudo gluster peer status`
|
||||||
|
> Note: if you are having problems adding peers, try disabling the firewall: `sudo ufw disable`
|
||||||
|
|
||||||
|
Next, create and then start the actual GlusterFS Volume like so:
|
||||||
|
|
||||||
|
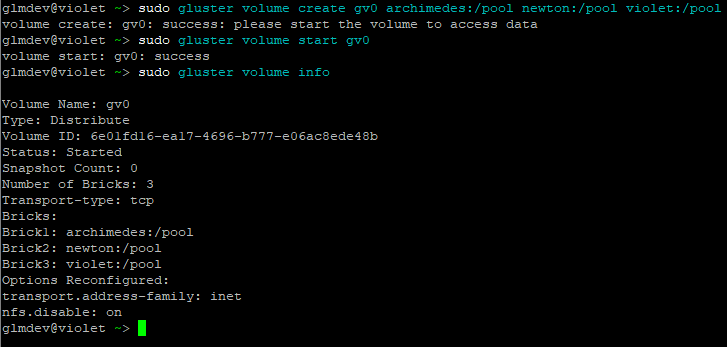
`sudo gluster volume create gv0 server1:/pool server2:/pool`
|
||||||
|
|
||||||
|
`sudo gluster volume start gv0`
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
After starting the volume, check its status by running:
|
||||||
|
|
||||||
|
`sudo gluster volume info`
|
||||||
|
|
||||||
|
And success! At last, we have our GlusterFS volume up and running.
|
||||||
|
|
||||||
|
## Step 5: Setting Up SAMBA Access
|
||||||
|
|
||||||
|
While we have our GlusterFS volume, we don’t have an easy way to access or use it. So, we’re going to set up a no-permissions SMB share for clients on the network.
|
||||||
|
> Note: I know this isn’t the most secure, but again, for my network it’s “good enough.” Feel free to customize your SMB permissions.
|
||||||
|
|
||||||
|
### Mounting the GlusterFS Volume
|
||||||
|
|
||||||
|
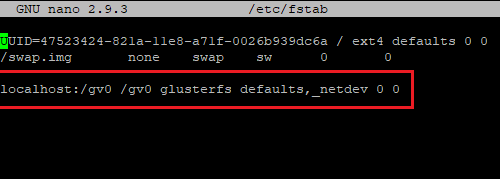
First, let’s mount the GlusterFS volume to a folder. To do this, we’re going to edit /etc/fstab to include the following line:
|
||||||
|
|
||||||
|
`localhost:/gv0 /gv0 glusterfs defaults,_netdev 0 0`
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
This will permanently mount the GlusterFS volume gv0 attached to localhost to the /gv0 folder. Now, refresh the mounts by running sudo mount -a.
|
||||||
|
> Note: you’ll need to create /gv0.
|
||||||
|
|
||||||
|
### SAMBA
|
||||||
|
|
||||||
|
Install SAMBA on the server with the mounted volume:
|
||||||
|
|
||||||
|
`sudo apt install samba -y`
|
||||||
|
|
||||||
|
Now we need to modify the permissions of the directory to allow guests write access:
|
||||||
|
|
||||||
|
`sudo chown nobody.nogroup -R /gv0`
|
||||||
|
|
||||||
|
`sudo chmod 777 -R /gv0`
|
||||||
|
|
||||||
|
Then create the share by adding this to the end of /etc/samba/smb.conf:
|
||||||
|
|
||||||
|
[gluster-drive]
|
||||||
|
browseable = yes
|
||||||
|
path = /gv0
|
||||||
|
guest ok = yes
|
||||||
|
read only = no
|
||||||
|
create mask = 777
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Test the syntax by running testparm, and provided everything passed the syntax check, restart SAMBA by running:
|
||||||
|
|
||||||
|
`sudo service smbd restart ; sudo service nmbd restart`
|
||||||
|
|
||||||
|
And that’s it!
|
||||||
|
|
||||||
|
## Success!
|
||||||
|
|
||||||
|
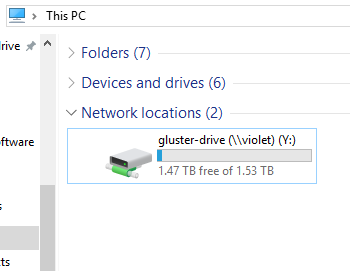
We have now successfully created a GlusterFS volume on ZFS nodes, and mounted it for the network to enjoy!
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
You should now be able to mount your new drive over the network and have read/write access to it.
|
||||||
|
|
||||||
|
To stop the Gluster volume, run sudo gluster volume stop gv0 on any of the nodes before shutting them down.
|
||||||
|
|
||||||
|
To restart the volume, start up all of the nodes, then run sudo gluster volume start gv0. Don’t forget to sudo mount -a and restart SAMBA.
|
||||||
|
|
||||||
|
This has been an incredibly fun project to undertake. If you have any comments, questions, or if you’re having problems getting it to work, leave a comment below!
|
||||||
143
src/blog/posts/2018-07-11-pfsense-on-esxi.md
Normal file
143
src/blog/posts/2018-07-11-pfsense-on-esxi.md
Normal file
@@ -0,0 +1,143 @@
|
|||||||
|
---
|
||||||
|
layout: blog_post
|
||||||
|
title: How to Set Up Virtualized pfSense on VMware ESXi 6.x
|
||||||
|
slug: Host-to-Set-Up-Virtualized-pfSense-on-VMware-ESXi-6-x
|
||||||
|
date: 2018-07-11 00:01:00
|
||||||
|
tags: blog
|
||||||
|
permalink: /blog/2018/07/11/Host-to-Set-Up-Virtualized-pfSense-on-VMware-ESXi-6-x/
|
||||||
|
blogtags:
|
||||||
|
- tutorial
|
||||||
|
- networking
|
||||||
|
- virtualization
|
||||||
|
---
|
||||||
|
|
||||||
|
For the longest time, my router/firewall solution has been a Raspberry Pi 3 with a USB network dongle running dnsmasq. While this worked well enough, it didn’t offer much by way of advanced configuration (at least not easily), and the lack of a GUI was often a pain. Plus, I wanted my Raspberry Pi back. So, in this saga, we’ll be taking a look at how to create a virtualized firewall by running pfSense on VMware ESXi.
|
||||||
|
|
||||||
|
## What We’ll Be Building
|
||||||
|
|
||||||
|
I like visual diagrams, so to kind of lay out what we’ll be doing, here’s a crudely MS Paint-ed diagram of how the virtual network will function:
|
||||||
|
|
||||||
|
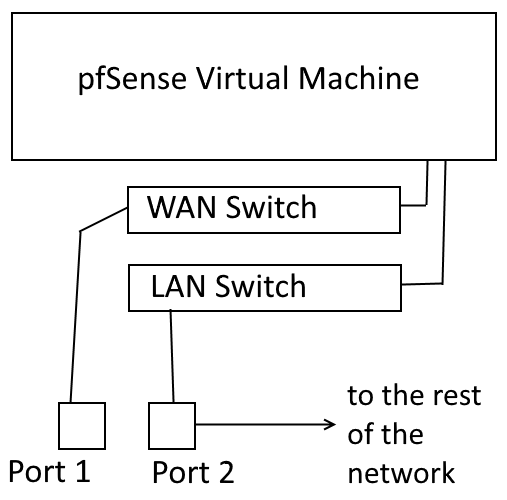*my 3rd grade computer teacher would be proud*
|
||||||
|
|
||||||
|
## Step 1: Requirements
|
||||||
|
|
||||||
|
So, for this project, you need a couple things. First, you need a server running VMware ESXi 6.x. Importantly, that server should have at least 2 network ports. That will enable us to have a WAN and a LAN port. For this, I’ll be using my Dell PowerEdge R710, which has 4x1GbE ports on the back, and it runs VMware ESXi 6.5.0.
|
||||||
|
> Note: With some finagling, the same result can be achieved with a single NIC using VLANs, as long as your switches/infrastructure support it. This, however, is beyond the scope of this tutorial.
|
||||||
|
|
||||||
|
Obviously, you will also need a WAN connection, as well as a switch or device to connect to the LAN port.
|
||||||
|
> Learn from my mistakes: Don’t forget to download pfSense *before* you start reconfiguring your internet connection…
|
||||||
|
|
||||||
|
## Step 2: Configuring ESXi & Management Connection
|
||||||
|
|
||||||
|
To achieve our virtual firewall, we’re going to create 2 virtual port-groups in ESXi: one for the WAN connection, and one for the LAN connection and add a physical port to each of those groups.
|
||||||
|
|
||||||
|
### Create The Virtual Switch(es)
|
||||||
|
|
||||||
|
We need to add the virtual switch for our LAN connection, then assign it to a physical port. Do this by logging into the ESXi interface and accessing Networking > Virtual Switches > Add standard virtual switch.
|
||||||
|
|
||||||
|
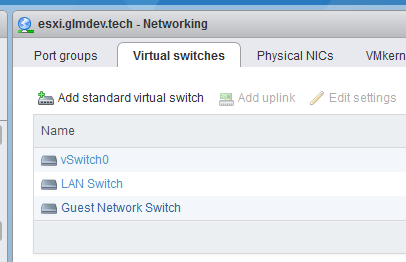*Additional interfaces for the firewall should be added here.*
|
||||||
|
|
||||||
|
Name the switch something meaningful and assign it a physical port.
|
||||||
|
|
||||||
|
For the WAN switch, we’re going to use the built-in “VM Network” switch. If you want any additional network ports for the firewall, add them now.
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
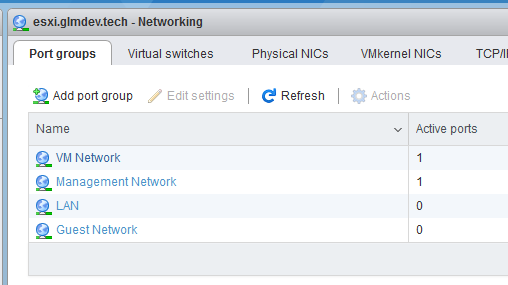
Now, we need to create “port groups” for the new switches. Open the Port Groups tab and create port groups for each of the new switches you added.
|
||||||
|
|
||||||
|
### The Management Connection
|
||||||
|
|
||||||
|
During most of this process, your computer will not have internet access, or DHCP service. This means that, in order to maintain access to the ESXi interface, we need to set static IP addresses on both the ESXi management interface and the computer we’re working from.
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
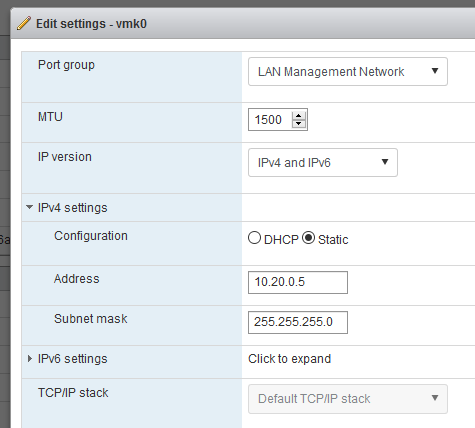
From the networking tab, access VMkernel NICs > vmk0 > Edit Settings > IPv4 settings
|
||||||
|
|
||||||
|
Set a static IP address that is within the address space of the new network. (i.e. if the new network is 10.20.0.1– 10.20.0.255, I picked 10.20.0.5)
|
||||||
|
|
||||||
|
Save and Apply the settings. Then, open your computer’s network settings and set its static IP to something in the same address space, and set the IP of the ESXi host as the gateway. **This will disrupt internet/intranet communications, but it will ensure continual access to the ESXi interface.**
|
||||||
|
|
||||||
|
## Step 3: Installing pfSense
|
||||||
|
> In point of fact, this can really be done with any firewall/router software you want to use (IPFire/OPNsense/routerOS/etc), I just chose pfSense.
|
||||||
|
|
||||||
|
Create a new virtual machine, and, for pfSense, select OS family: Other and set the OS to “FreeBSD (64-bit).”
|
||||||
|
|
||||||
|
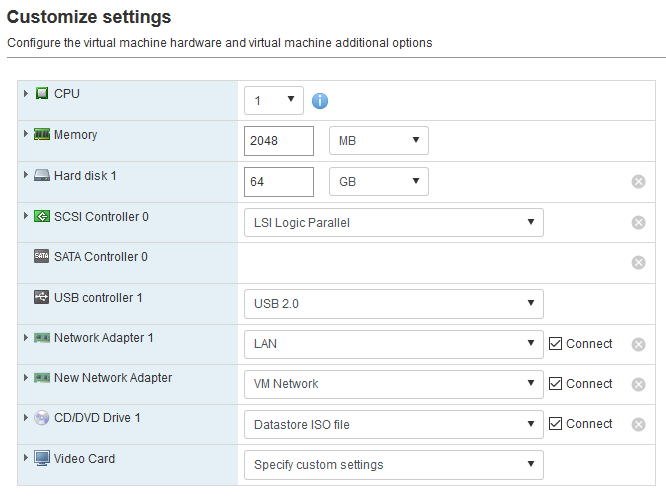
Tab through the wizard until you land on the VM’s configuration page. Here we need to modify a few things.
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
Add an additional Network adapter using the button at the top, and then select the LAN port-group we created earlier. You should have a network adapter with a WAN port-group by default.
|
||||||
|
|
||||||
|
Then, in the CD/DVD drive, select the pfSense installer ISO from the datastore. Now you can click create and start the VM.
|
||||||
|
|
||||||
|
### pfSense Install
|
||||||
|
|
||||||
|
The basic installation of the pfSense operating system is nearly identical to installing it on bare-metal. Just click through the installer until the system reboots and you land on the set-up page.
|
||||||
|
|
||||||
|
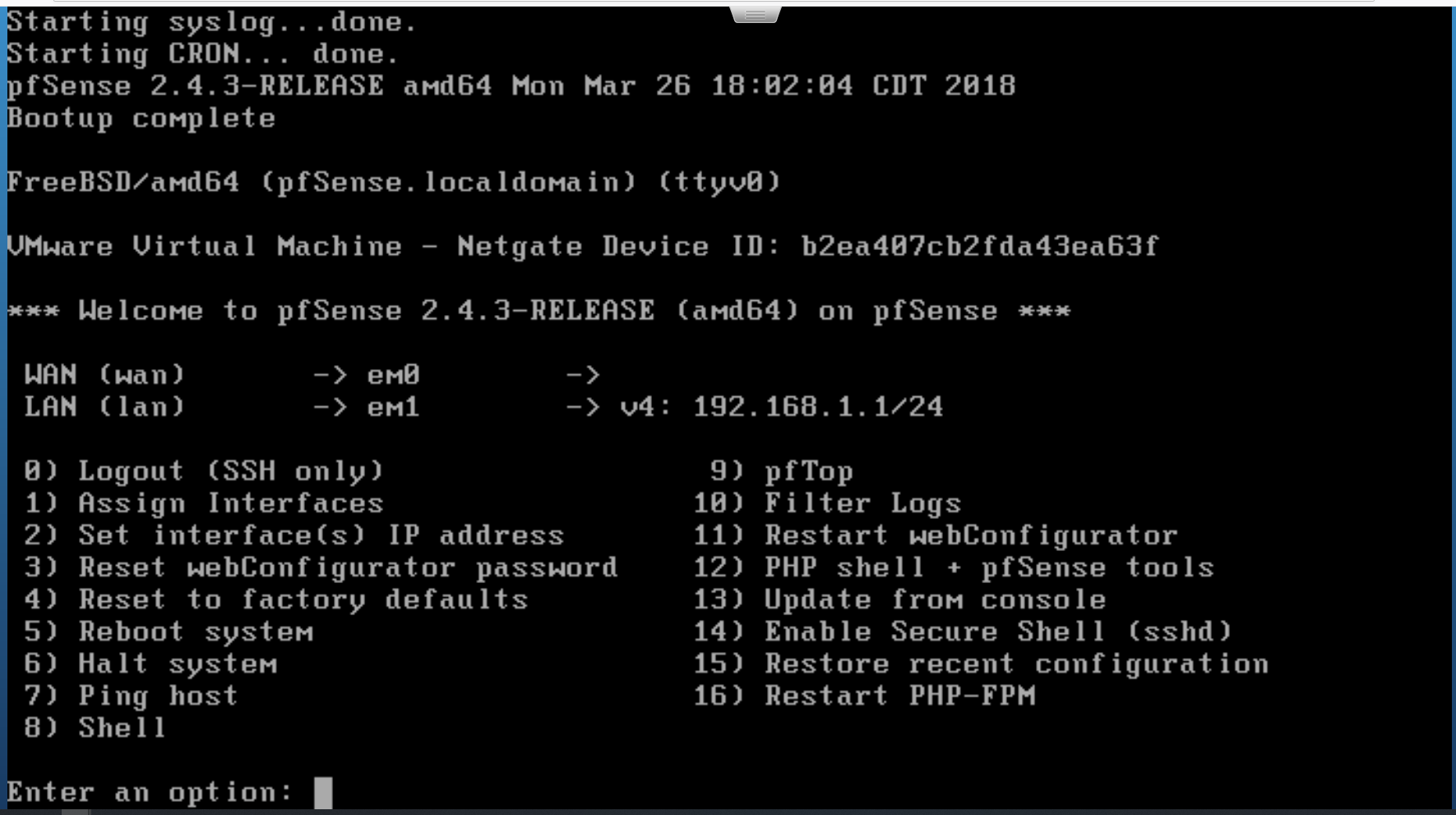*the pfSense setup page*
|
||||||
|
|
||||||
|
To make things easier on ourselves, we’re going to pre-configure a few things from here before opening the web interface. First, we need to set up the WAN interface. Even though my WAN doesn’t have DHCP, pfSense was able to automatically select which interfaces are supposed to be which.
|
||||||
|
|
||||||
|
Select option 2 to Set interface(s) IP address.
|
||||||
|
|
||||||
|
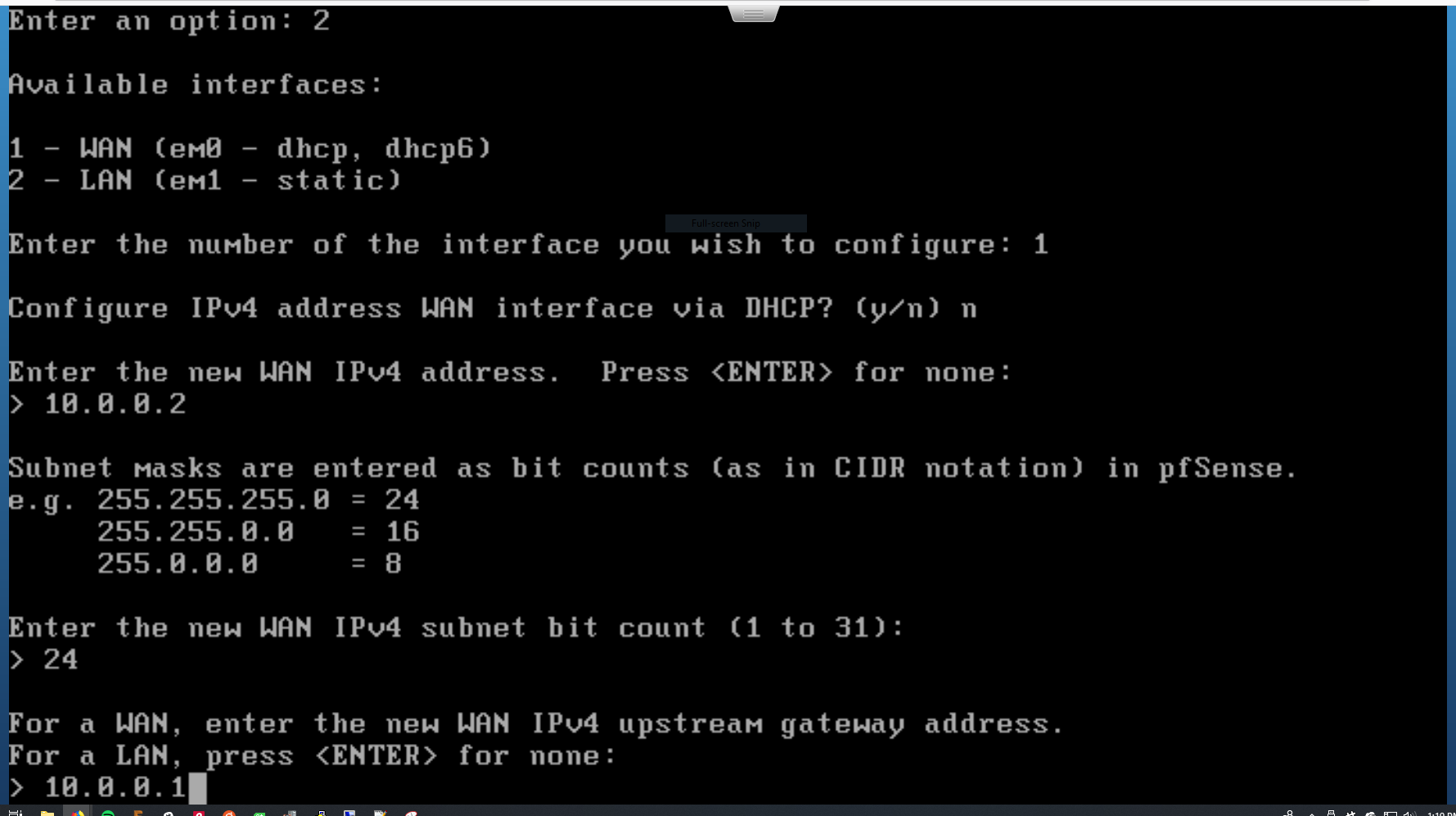*configuring the WAN interface*
|
||||||
|
|
||||||
|
This will launch an interactive wizard that will help you configure an interface. Select the WAN interface to configure, then just run through the wizard.
|
||||||
|
|
||||||
|
For me, this involved setting the static IP address of the port and pointing it toward my gateway.
|
||||||
|
|
||||||
|
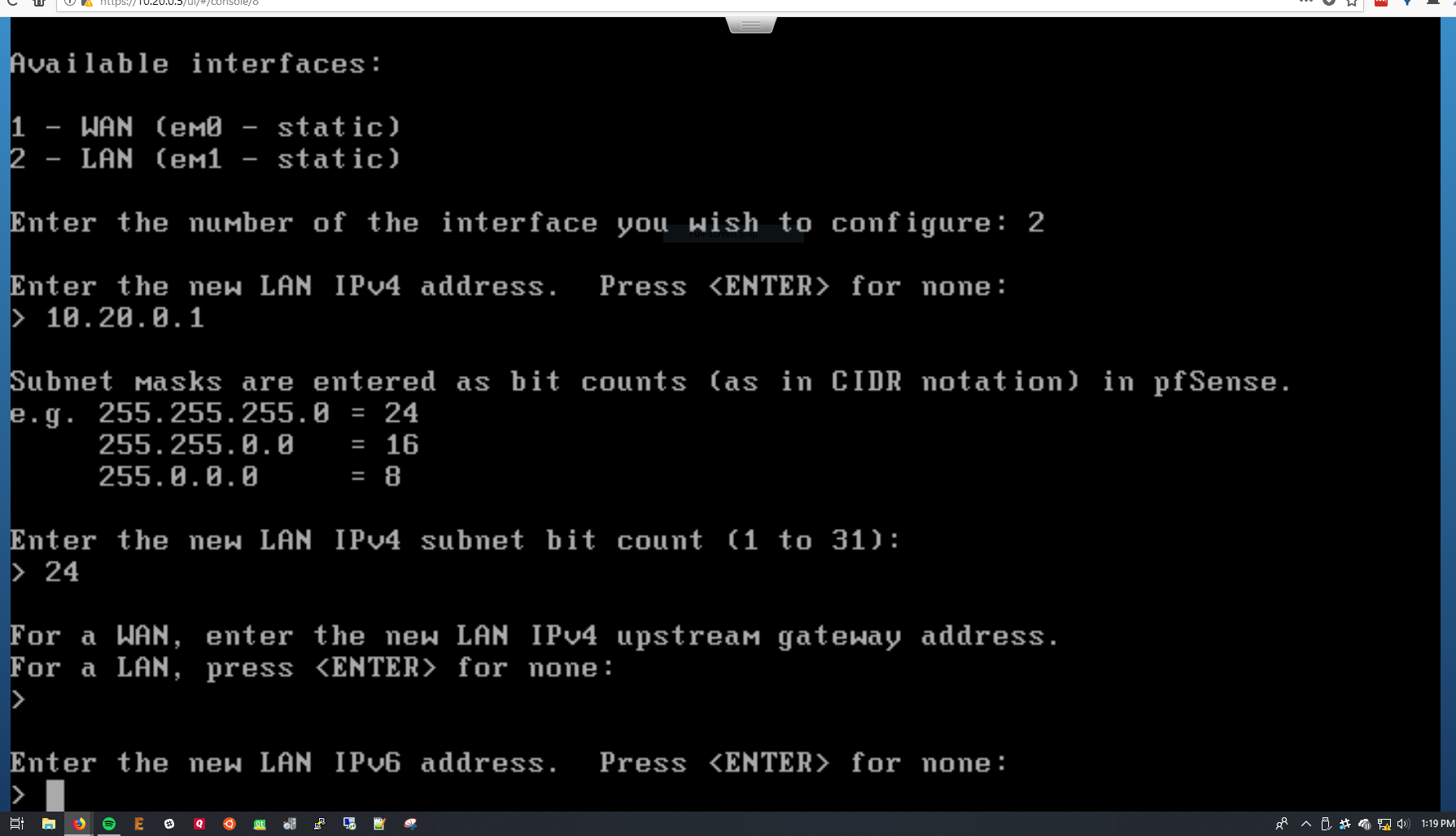*configuring the LAN interface*
|
||||||
|
|
||||||
|
Now, we repeat the process for the LAN interface. Here you’ll be prompted to set the static IP again, as well as selecting a DHCP range for pfSense’s LAN port. Make sure this is the same address space as you planned earlier (for me, 10.20.0.X).
|
||||||
|
|
||||||
|
Select y to enable the DHCP server, and press enter to save.
|
||||||
|
|
||||||
|
## Step 4: Moving to the New Network
|
||||||
|
|
||||||
|
We now officially have a virtual firewall running, but before we can start using the new network, there are a few configuration things to modify.
|
||||||
|
|
||||||
|
### The Management Network (reprise)
|
||||||
|
|
||||||
|
In order to access our ESXi host from the new network, we need to move the vmk0 management interface over to the LAN switch we created earlier. However, we can’t just add it to the existing LAN port group (ESXi hates that, for some reason), so we’ll create a new port group. Access Networking > Port Groups > New Port Group.
|
||||||
|
|
||||||
|
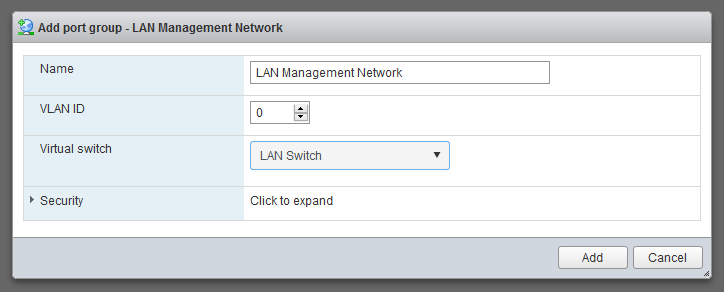
|
||||||
|
|
||||||
|
Create a new LAN Management Network port group on the same LAN switch we created earlier.
|
||||||
|
|
||||||
|
This will make sure it bridges with the LAN port on the new pfSense VM.
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
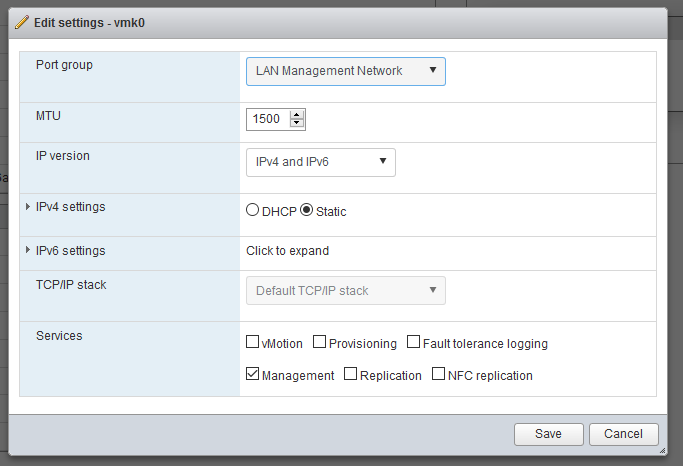
Now, go to Networking > VMkernel NICs > Edit Settings and change the port group to the new LAN Management Network port group we just created.
|
||||||
|
|
||||||
|
Note that after you save the settings, you’ll no longer be able to access the ESXi interface. This is normal.
|
||||||
|
|
||||||
|
### Move It Over!
|
||||||
|
|
||||||
|
Now, we can finally start using our new network! Move the connection to the switch (or the rest of your physical network) to the new port on the server that we added to the LAN switch we created at the beginning. This will connect your network to the pfSense LAN interface.
|
||||||
|
|
||||||
|
Finally, reset your computer’s IP address back to DHCP so it will pick up an address and DNS from pfSense.
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
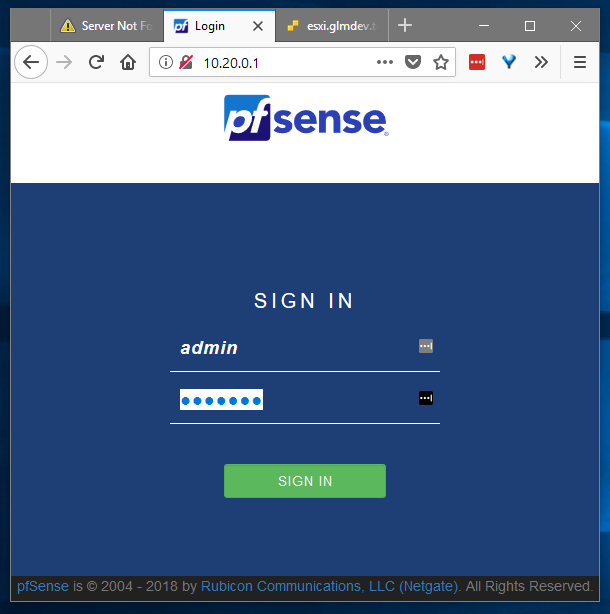
Open up your web browser of choice and navigate to the IP address you assigned to the pfSense LAN interface in Step 3, and **voila!** You should be presented with the pfSense web interface.
|
||||||
|
|
||||||
|
Log in using the default credentials:
|
||||||
|
|
||||||
|
admin
|
||||||
|
pfsense
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
Now it’s just a matter of running through the standard pfSense setup wizard and you’re off to the races!
|
||||||
|
|
||||||
|
pfSense will behave exactly like it would if it were installed on a physical box. This means that everything from DNS to VLANs to captive portal will behave normally.
|
||||||
|
|
||||||
|
Plus, you should still be able to access the ESXi host. :)
|
||||||
|
|
||||||
|
## Conclusion
|
||||||
|
|
||||||
|
Virtualized networking is a great way to experiment with different firewall software without having your network down for long periods of time. It also lends a lot of flexibility when it comes to customizing network segments.
|
||||||
|
|
||||||
|
I hope this guide has been helpful, and if you have any questions, comments, or if you run into any issues, leave a comment down below, and I’ll do my best to help!
|
||||||
|
|
||||||
122
src/blog/posts/2018-08-06-free-www.md
Normal file
122
src/blog/posts/2018-08-06-free-www.md
Normal file
@@ -0,0 +1,122 @@
|
|||||||
|
---
|
||||||
|
layout: blog_post
|
||||||
|
title: Creating the Ultimate (Free) Personal Website
|
||||||
|
slug: Creating-the-Ultimate-Free-Personal-Website
|
||||||
|
date: 2018-08-06 00:01:00
|
||||||
|
tags: blog
|
||||||
|
permalink: /blog/2018/08/06/Creating-the-Ultimate-Free-Personal-Website/
|
||||||
|
blogtags:
|
||||||
|
- tutorial
|
||||||
|
- webdev
|
||||||
|
- hosting
|
||||||
|
---
|
||||||
|
|
||||||
|
For years, I’ve been roaming the web trying to find a good, free way to host my personal website. I’m a cheapskate, so I really didn’t want to pay for it…
|
||||||
|
|
||||||
|
After trying numerous “free tiers,” sketchy shared-hosting services, and overly-complicated free cloud options, I finally settled on what I consider to be the ultimate, secure, and free (as in cookies, and as in Freedom) hosting solution: GitHub pages + CloudFlare. In this tutorial, we’ll take a look at how to set it up.
|
||||||
|
|
||||||
|
## Step 0: Prerequisites
|
||||||
|
|
||||||
|
### 0.1 — You need a website.
|
||||||
|
|
||||||
|
](https://cdn-images-1.medium.com/max/2224/1*OZfWkxG6qE3CSzCqwf9EiA.png)*[glmdev.tech](https://glmdev.tech/)*
|
||||||
|
|
||||||
|
The first step in all of this, of course, is to actually have a website to host. So, create your personal website using good ole-fashioned static web development (HTML/CSS/JS/etc).
|
||||||
|
|
||||||
|
My site is a simple, one page Bootstrap ordeal. Save for Bootstrap and jQuery, it has only 4 lines of JavaScript.
|
||||||
|
|
||||||
|
### 0.2 — Get a custom domain name (optional).
|
||||||
|
|
||||||
|
While it’s not *required*, having a custom domain name makes your online presence seem somehow more… official. You can get .com domain names for super cheap from sites like [Google Domains](https://domains.google/).
|
||||||
|
|
||||||
|
## Step 1: Setting Up GitHub Pages
|
||||||
|
|
||||||
|
GitHub has an *awesome* free static hosting service called GitHub Pages. Essentially, it allows you to push your static site to a repository and GitHub will automatically host that site for free. forever. The only potential downside is that the source-code for your website will be available for anyone to view.
|
||||||
|
|
||||||
|
### 1.1 — Sign-in to GitHub and create a repo.
|
||||||
|
|
||||||
|
For the purposes of this tutorial, I’m going to assume you know [how Git & GitHub work](https://www.youtube.com/watch?v=AGO9nQTKkfI&list=PLIaeD4fuWZJZ8Kb0wf_mWl52R8DjTA1og).
|
||||||
|
|
||||||
|
Sign in to GitHub, and create a new repository. **This repo must be named in a special way to enable GitHub Pages.** It must take the following form:
|
||||||
|
|
||||||
|
<your github username>.github.io
|
||||||
|
|
||||||
|
So mine, for example, is called glmdev.github.io. This tells GitHub to activate GitHub pages. Now, on your local machine, add the repository as a remote and push your code to the master branch.
|
||||||
|
|
||||||
|
### 1.2 — Force clients to use HTTPS. (optional, but not really…)
|
||||||
|
|
||||||
|
**If you’re using a custom domain, this is not for you.**
|
||||||
|
|
||||||
|
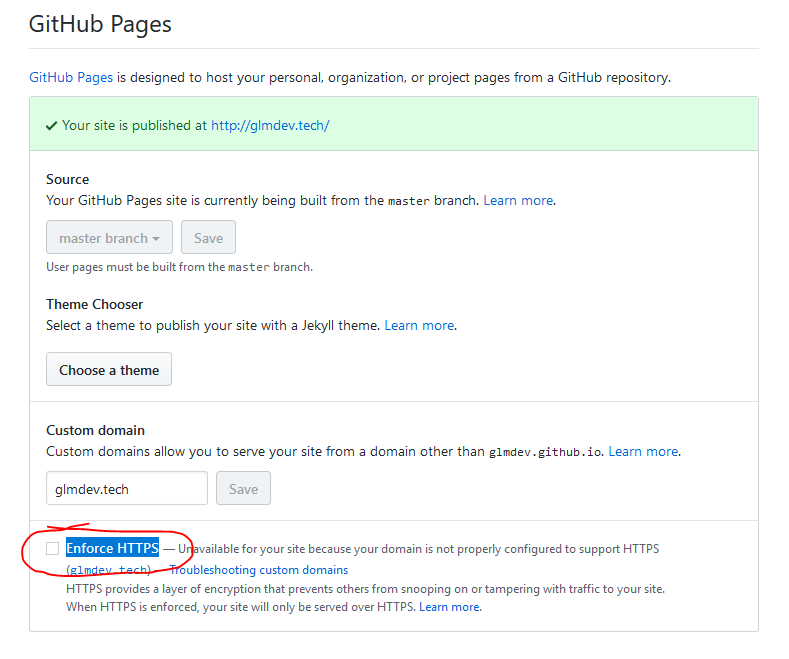
If you’re not using a custom domain, you’re technically done at this point. You have a working static website. But, in the name of best practice, we are going to redirect non-secure clients to the HTTPS protocol by default.
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
This can be done by going to the repository settings page, scrolling down to the GitHub pages section, and checking the “Enforce HTTPS” box.
|
||||||
|
|
||||||
|
By default, GitHub provides free SSL certificates for their *.github.io domains.
|
||||||
|
|
||||||
|
That’s it! If you don’t have a custom domain, you’re done. Congrats, and happy interneting!
|
||||||
|
|
||||||
|
## Step 2: Setting Up CloudFlare
|
||||||
|
|
||||||
|
CloudFlare is an amazing, free service that provides web caching, always-on, and SSL enforcement for websites. It also has a host of other features that you can tinker with. So, we’re going to be setting up CloudFlare to use with our custom domain.
|
||||||
|
|
||||||
|
### 2.1 — Create a CloudFlare account.
|
||||||
|
|
||||||
|
Head over to CloudFlare and sign up for an account, then click the add site button. Put in your custom domain name here.
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
CloudFlare will then probe your existing DNS settings to try to import them. It’s important that you sign-in to your registrar and add any other DNS records you have (like MX mail records and TXT records) because after the setup, all DNS queries to your domain will run through the CloudFlare servers, not your registrar.
|
||||||
|
|
||||||
|
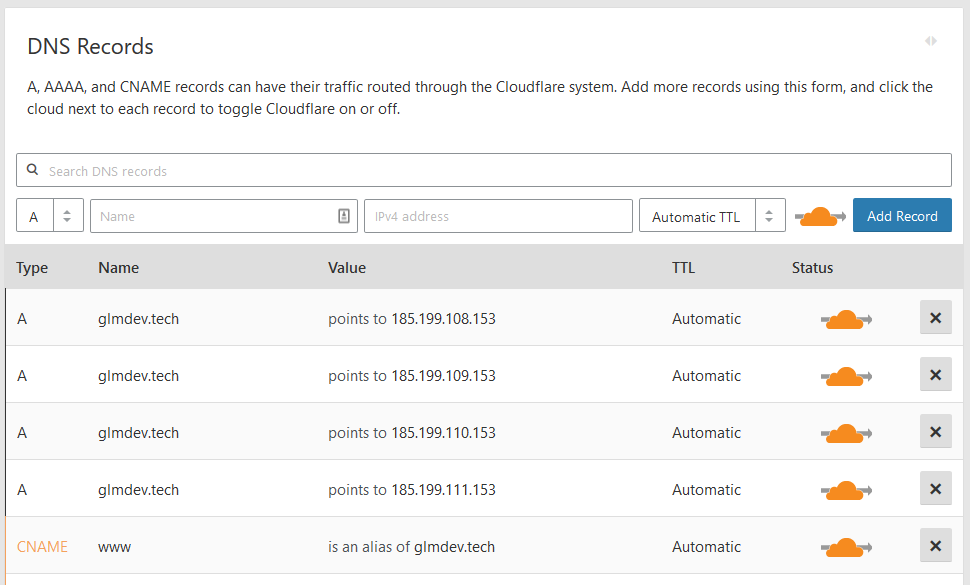
At this point, you should also add GitHub’s root IP addresses as A records to your domain. This will allow visitors to your domain to access the Pages site. I also added a simple CNAME record pointing the www. version of my site back to the root domain. The GitHub A records are:
|
||||||
|
|
||||||
|
185.199.108.153
|
||||||
|
185.199.109.153
|
||||||
|
185.199.110.153
|
||||||
|
185.199.111.153
|
||||||
|
|
||||||
|
### 2.2 — Configure your domain’s nameservers.
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
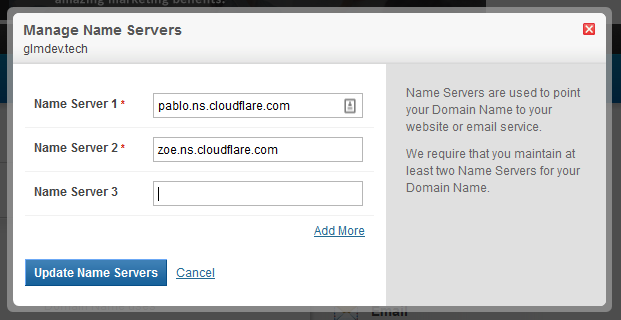
After you add the DNS records, you’ll be given the addresses of 2 CloudFlare nameservers to point your domain to. These will take the place of your registrar’s default servers.
|
||||||
|
|
||||||
|
Sign in to your registrar and click the settings for your domain’s nameservers. Then, replace the registrar’s default ones with the addresses CloudFlare gave you.
|
||||||
|
|
||||||
|
### 2.2 — Now the hardest part.
|
||||||
|
|
||||||
|
This part is the kicker. Because DNS is decentralized, you may have to wait up to 48 hours for the changes to propagate before you can finish setting up your domain. You can use a [DNS checker](https://dnschecker.org/) to see if your domain’s A records now point to a CloudFlare IP address, but even then it may take several more hours.
|
||||||
|
|
||||||
|
## Step 3: Add the Custom Domain to GitHub Pages
|
||||||
|
|
||||||
|
Once your DNS settings have propagated, you can tell GitHub to use the custom domain instead of the free .github.io one.
|
||||||
|
|
||||||
|
### 3.1 — Create the CNAME file.
|
||||||
|
|
||||||
|
To do this, create a file in the root of your repository called CNAME, then put the custom domain(s) in the file, one per line, like so:
|
||||||
|
|
||||||
|
glmdev.tech
|
||||||
|
www.glmdev.tech
|
||||||
|
|
||||||
|
Commit and push the file, then give GitHub a second to rebuild the site, and then you should be able to load your website at the custom domain.
|
||||||
|
|
||||||
|
### 3.2 — Enable SSL redirection. (optional, but again, not really…)
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
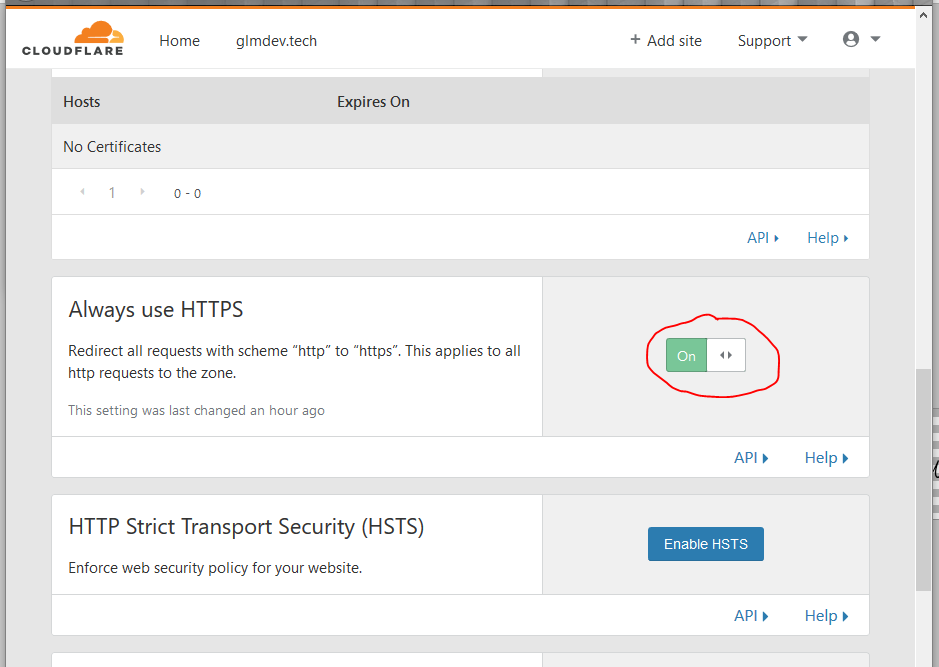
Lastly, we want non-secure HTTP clients to be automatically redirected to the HTTPS protocol whenever they can. To enable this, go to the CloudFlare dashboard, click the Crypto tab, and turn on “Always Use HTTPS.” While you’re at it, because GitHub also supports SSL, change the SSL mode at the top of the page from “Flexible” to “Full.”
|
||||||
|
|
||||||
|
## Conclusion
|
||||||
|
|
||||||
|
That’s it! Not terribly painful, actually, and we have a kick-ass free (and secure) website up and running.
|
||||||
|
|
||||||
|
A few things of note:
|
||||||
|
|
||||||
|
1. CloudFlare is really powerful. It can do a lot more than I covered in this tutorial, and I’d suggest tinkering around with it to really get the most out of the free service.
|
||||||
|
|
||||||
|
1. When you want to update/change your website, all you need to do is push the changes to the GitHub pages repository, and they’ll automatically be updated on the live site.
|
||||||
|
|
||||||
|
1. Any new DNS records you may add to your domain should be added from within the CloudFlare DNS panel, **not via your registrar.**
|
||||||
|
|
||||||
|
1. Lastly, if you don’t already make it a habit, I suggest going to your GitHub and CloudFlare account settings and enabling 2-Factor Authentication.
|
||||||
444
src/blog/posts/2018-11-15-rpi-part-1.md
Normal file
444
src/blog/posts/2018-11-15-rpi-part-1.md
Normal file
@@ -0,0 +1,444 @@
|
|||||||
|
---
|
||||||
|
layout: blog_post
|
||||||
|
title: Building a Raspberry Pi Cluster - Part I
|
||||||
|
slug: Building-a-Raspberry-Pi-Cluster-Part-I
|
||||||
|
date: 2018-11-15 01:00:00
|
||||||
|
tags: blog
|
||||||
|
permalink: /blog/2018/11/15/Building-a-Raspberry-Pi-Cluster-Part-I/
|
||||||
|
blogtags:
|
||||||
|
- tutorial
|
||||||
|
- raspberry pi
|
||||||
|
- hosting
|
||||||
|
---
|
||||||
|
|
||||||
|
Part I — The Basics
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
*This is Part 1 in my series on building an HPC-style Raspberry Pi cluster. Check out [Part 2](https://medium.com/@glmdev/building-a-raspberry-pi-cluster-aaa8d1f3d2ca?source=---------6------------------) and [Part 3](https://medium.com/@glmdev/building-a-raspberry-pi-cluster-f5f2446702e8?source=---------4------------------).*
|
||||||
|
|
||||||
|
As a new project of mine, I’ve decided to build a miniature community-style cluster using Raspberry Pi computers and HPC-grade software. When I set out to do this, I discovered that instructions on setting this up are actually surprisingly sparse. So, I decided to document my progress in a series of guides. In this Part I, we will look at the basics of setting up the hardware and getting a cluster scheduler running.
|
||||||
|
|
||||||
|
## Step 0: Get The Hardware
|
||||||
|
|
||||||
|
### Parts list
|
||||||
|
|
||||||
|
* 3x Raspberry Pi 3 Model B — for the compute nodes
|
||||||
|
|
||||||
|
* 1x Raspberry Pi 3 Model B — for the master/login node
|
||||||
|
|
||||||
|
* 4x MicroSD Cards
|
||||||
|
|
||||||
|
* 4x micro-USB power cables
|
||||||
|
|
||||||
|
* 1x 8-port 10/100/1000 network switch
|
||||||
|
|
||||||
|
* 1x 6-port USB power-supply
|
||||||
|
|
||||||
|
* 1x 64GB USB Drive (or NAS, see below)
|
||||||
|
|
||||||
|
This project is scalable to as many RPis (and even non-RPi computers) of different kinds as you want, but for my cluster, I used 3 Pis with MicroSD cards of varying capacities connected to my network through an 8-port gigabit switch.
|
||||||
|
|
||||||
|
Let’s talk storage. Cluster computing requires a storage location that is shared across all of the different nodes so they can work on the same files as the jobs are farmed out. For a basic setup, you can use a 64GB USB drive plugged in to one of the Pis as shared storage (or a larger Micro SD card in one of them). However, as an alternative, if you have some kind of network-attached storage that you can export as an NFS share, this can also be used as the shared drive.
|
||||||
|
|
||||||
|
For example, I have about 750GB of btrfs RAID storage on a Linux box on my network. Instead of using a 64GB flash drive, I just exported an NFS share from this and mounted it on all the nodes. (Don’t worry, we’ll cover both.)
|
||||||
|
|
||||||
|
## Step 1: Flash the Raspberry Pis
|
||||||
|
|
||||||
|
The first step is to get our Pis up and running. Start by downloading the latest version of Raspbian, the Debian distribution that runs on the Pis. Download the command-line only “lite” version to save space: [Download Here](https://www.raspberrypi.org/downloads/raspbian/).
|
||||||
|
|
||||||
|
Now, download and install Etcher. Etcher is a simple program that we will use to write the downloaded Raspbian image to our SD cards. [Get Etcher here.](https://etcher.io/)
|
||||||
|
|
||||||
|
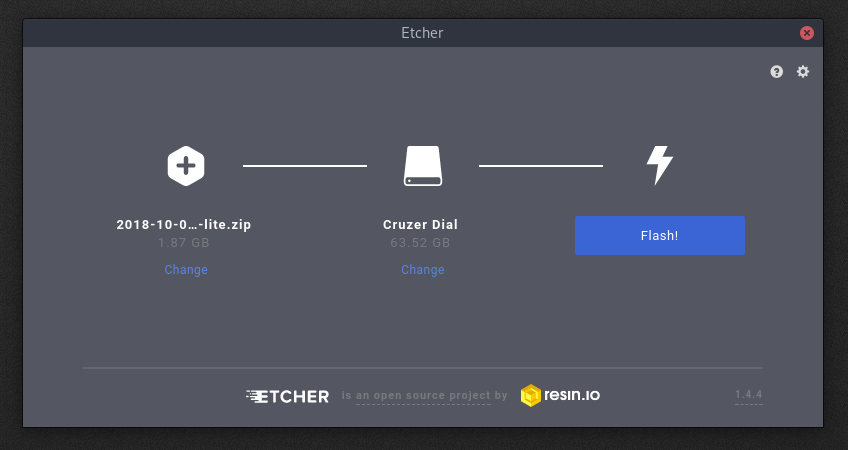
|
||||||
|
|
||||||
|
Fire up Etcher and plug in your MicroSD card (use an adapter).
|
||||||
|
|
||||||
|
Select the Raspbian ZIP file and hit flash.
|
||||||
|
|
||||||
|
Before we finish with the SD card, we want to enable SSH remote access from our Pi. To do this, open the “boot” drive on the SD card and create an empty file named ssh with no extension. On Windows, you can do this by opening Notepad and saving the blank file with no extension. On macOS and Linux, open the folder in a shell and run:
|
||||||
|
|
||||||
|
glmdev@polaris ~> touch ssh
|
||||||
|
|
||||||
|
Wash, rinse, and repeat this for the other 3 MicroSD cards. Once you’ve done this, plug the SD cards into the 4 nodes.
|
||||||
|
|
||||||
|
## Step 2: Network Setup
|
||||||
|
|
||||||
|
We want to make sure that our nodes have IP addresses that never change. This way, we can be sure that they can always talk to each other, which is critical for the cluster jobs.
|
||||||
|
|
||||||
|
I recommend setting the Pis up one at a time so you can keep track of which physical node is has what IP. This makes maintenance easier.
|
||||||
|
|
||||||
|
Start by plugging the switch into your network. Then, connect one Pi to the switch and plug it in. Wait a second for it to boot up.
|
||||||
|
|
||||||
|
Once the Pi has booted, we can SSH into it to finish setting it up. To find the IP address of the Pi, either use your router’s interface to view attached devices. If you can’t do this, use a program like nmap to scan IP addresses on your network. Either way, look for a device named RASPBERRYPI and make a note of its IP address.
|
||||||
|
|
||||||
|
*Find the RASPBERRYPI device’s IP address.*
|
||||||
|
|
||||||
|
SSH into the Pi using:
|
||||||
|
|
||||||
|
ssh pi@ip.addr.goes.here
|
||||||
|
|
||||||
|
(default password: raspberry)
|
||||||
|
|
||||||
|
## Step 3: Set Up the Raspberry Pis
|
||||||
|
|
||||||
|
### 3.1: raspi-config
|
||||||
|
|
||||||
|
Now we can start setting up the Pi. First, get some basic config out of the way:
|
||||||
|
|
||||||
|
pi@raspberrypi~$ sudo raspi-config
|
||||||
|
|
||||||
|
This will open the config utility. Change the default password, set the locale and timezone, and expand the filesystem. Then, exit the utility.
|
||||||
|
|
||||||
|
### 3.2: setting the hostname
|
||||||
|
> **A word about hostnames:**
|
||||||
|
> SLURM, the cluster scheduler we will be using, expects hosts to be named following a specific pattern: *<whatever text here><a predictable number>*. So, when choosing hostnames for your RPis, it’s helpful to pick a system and number them in order (eg node01, node02, node03, node04, etc…).
|
||||||
|
|
||||||
|
Now, set the hostname:
|
||||||
|
|
||||||
|
sudo hostname node01 # whatever name you chose
|
||||||
|
sudo nano /etc/hostname # change the hostname here too
|
||||||
|
sudo nano /etc/hosts # change "raspberrypi" to "node01"
|
||||||
|
|
||||||
|
We use the systemd hostname command, edit the hostname file, and update the hosts file so local resolution works.
|
||||||
|
|
||||||
|
### 3.3: make sure the system time is right
|
||||||
|
|
||||||
|
The SLURM scheduler and the Munge authentication that it uses requires accurate system time. We’ll install the ntpdate package to periodically sync the system time in the background.
|
||||||
|
|
||||||
|
sudo apt install ntpdate -y
|
||||||
|
|
||||||
|
### 3.4: reboot
|
||||||
|
|
||||||
|
sudo reboot
|
||||||
|
|
||||||
|
***Repeat this process on all of the RPis.***
|
||||||
|
|
||||||
|
## Step 4: Shared Storage
|
||||||
|
> **A word on shared storage:**
|
||||||
|
> In order for a cluster to work well, a job should be able to be run on any of the nodes in the cluster. This means that each node needs to be able to access the same files. We will accomplish this by connecting a 64GB USB drive connected to the master node (more on that below) and exporting that drive as a network file system (NFS). Then, we can mount that NFS share on all the nodes so they can all share access to it.
|
||||||
|
> **Side note:**
|
||||||
|
> If, like me, you have a separate NAS box on your network that you would rather use as shared storage, you can export an NFS share from that box. Then, just mount that share on the nodes using the instructions below.
|
||||||
|
|
||||||
|
### 4.0: Login to the Master Node
|
||||||
|
|
||||||
|
We will discuss the master node more later, but one of our nodes will be the controller. Just pick one. :) In my cluster, the master is node01.
|
||||||
|
|
||||||
|
ssh pi@<ip addr of node01>
|
||||||
|
|
||||||
|
### 4.1: Connect & Mount Flash Drive
|
||||||
|
|
||||||
|
**4.1.1: Find the drive identifier.
|
||||||
|
**Plug the flash drive into one of the USB ports on the master node. Then, figure out its dev location by examining the output of lsblk:
|
||||||
|
|
||||||
|
glmdev@node01 ~> lsblk
|
||||||
|
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
|
||||||
|
mmcblk0 179:0 0 7.4G 0 disk
|
||||||
|
├─mmcblk0p1 179:1 0 43.8M 0 part /boot
|
||||||
|
└─mmcblk0p2 179:2 0 7.4G 0 part /
|
||||||
|
sda 8:16 0 59.2G 0 disk
|
||||||
|
└─sda1 8:17 0 59.2G 0 part
|
||||||
|
|
||||||
|
In this case, the main partition of the flash drive is at /dev/sda1.
|
||||||
|
|
||||||
|
**4.1.2: Format the drive.
|
||||||
|
**We’re first going to format the flash drive to use the ext4 filesystem:
|
||||||
|
|
||||||
|
sudo mkfs.ext4 /dev/sda1
|
||||||
|
> **A word of warning: **double check to be sure you’re not about to overwrite your root */* directory on accident.
|
||||||
|
|
||||||
|
**4.1.3: Create the mount directory.**
|
||||||
|
(Note that this should be the same across all the nodes.) In my cluster, I used /clusterfs:
|
||||||
|
|
||||||
|
sudo mkdir /clusterfs
|
||||||
|
sudo chown nobody.nogroup -R /clusterfs
|
||||||
|
sudo chmod 777 -R /clusterfs
|
||||||
|
|
||||||
|
**4.1.4: Setup automatic mounting.
|
||||||
|
**To mount our flash drive on boot, we need to find the UUID. To do this, run blkid and make note of the UUID from /dev/sda1 like so:
|
||||||
|
|
||||||
|
UUID="65077e7a-4bd6-47ea-8014-01e06655cc31"
|
||||||
|
|
||||||
|
Now, edit fstab to mount the drive on boot.
|
||||||
|
|
||||||
|
sudo nano /etc/fstab
|
||||||
|
|
||||||
|
Add the following line:
|
||||||
|
|
||||||
|
UUID=65077e7a-4bd6-47ea-8014-01e06655cc31 /clusterfs ext4 defaults 0 2
|
||||||
|
|
||||||
|
Finally, mount the drive with sudo mount -a.
|
||||||
|
|
||||||
|
**4.1.5: Set loose permissions.
|
||||||
|
**Because use of our cluster will be pretty supervised, we can set loose permissions on the mounted drive:
|
||||||
|
|
||||||
|
sudo chown nobody.nogroup -R /clusterfs
|
||||||
|
sudo chmod -R 766 /clusterfs
|
||||||
|
|
||||||
|
### 4.2: Export the NFS Share
|
||||||
|
|
||||||
|
Now, we need to export the mounted drive as a network file system share so the other nodes can access it. *Do this process on the master node.*
|
||||||
|
|
||||||
|
**4.2.1: Install the NFS server.**
|
||||||
|
|
||||||
|
sudo apt install nfs-kernel-server -y
|
||||||
|
|
||||||
|
**4.2.2: Export the NFS share.**
|
||||||
|
|
||||||
|
Edit /etc/exports and add the following line:
|
||||||
|
|
||||||
|
/clusterfs <ip addr>(rw,sync,no_root_squash,no_subtree_check)
|
||||||
|
|
||||||
|
Replace <ip addr> with the IP address schema used on your local network. This will allow any LAN client to mount the share. For example, if your LAN addresses were 192.168.1.X, you would have:
|
||||||
|
|
||||||
|
/clusterfs 192.168.1.0/24(rw,sync,no_root_squash,no_subtree_check)
|
||||||
|
|
||||||
|
rw gives the client Read-Write access, sync forces changes to be written on each transaction, no_root_squash enables the root users of clients to write files as root permissions, and no_subtree_check prevents errors caused by a file being changed while another system is using it.
|
||||||
|
|
||||||
|
Lastly, run the following command to update the NFS kernel server:
|
||||||
|
|
||||||
|
sudo exportfs -a
|
||||||
|
|
||||||
|
### 4.3: Mount the NFS Share on the Clients
|
||||||
|
|
||||||
|
Now that we’ve got the NFS share exported from the master node, we want to mount it on all of the other nodes so they can access it. *Repeat this process for all of the other nodes.*
|
||||||
|
|
||||||
|
**4.3.1: Install the NFS client.**
|
||||||
|
|
||||||
|
sudo apt install nfs-common -y
|
||||||
|
|
||||||
|
**4.3.2: Create the mount folder.**
|
||||||
|
This should be the same directory that you mounted the flash drive to on the master node. In my case, this is /clusterfs:
|
||||||
|
|
||||||
|
sudo mkdir /clusterfs
|
||||||
|
sudo chown nobody.nogroup /clusterfs
|
||||||
|
sudo chmod -R 777 /clusterfs
|
||||||
|
|
||||||
|
**4.3.3: Setup automatic mounting.**
|
||||||
|
We want the NFS share to mount automatically when the nodes boot. Edit /etc/fstab to accomplish this by adding the following line:
|
||||||
|
|
||||||
|
<master node ip>:/clusterfs /clusterfs nfs defaults 0 0
|
||||||
|
|
||||||
|
Now mount it with sudo mount -a and you should be able to create a file in /clusterfs and have it show up at the same path across all the nodes.
|
||||||
|
|
||||||
|
## Step 5: Configure the Master Node
|
||||||
|
> **A word on schedulers and SLURM:**
|
||||||
|
> It may be overkill for a personal cluster, but most Linux clusters use a piece of software called a scheduler. A scheduler accepts jobs and, when nodes become available, it runs them on the next available set of nodes. This allows us to keep submitting jobs and they will be processed as resources become available.
|
||||||
|
> We will be using a scheduler called [SLURM](https://slurm.schedmd.com/) on our cluster. SLURM runs a control daemon on one or more master nodes, then farms out jobs to other nodes. One of our RPis will be a dedicated login & master node, and will not process jobs.
|
||||||
|
> What’s a login node? It’s the RPi you ssh into to use the cluster.
|
||||||
|
|
||||||
|
### 5.0: Login to the Master Node
|
||||||
|
|
||||||
|
Pick one of your nodes to be the dedicated master, and ssh into it. In my cluster, this is node01.
|
||||||
|
|
||||||
|
ssh pi@<ip addr of node01>
|
||||||
|
|
||||||
|
### 5.1: /etc/hosts
|
||||||
|
|
||||||
|
To make resolution easier, we’re going to add hostnames of the nodes and their IP addresses to the /etc/hosts file. Edit /etc/hosts and add the following lines:
|
||||||
|
|
||||||
|
<ip addr of node02> node02
|
||||||
|
<ip addr of node03> node03
|
||||||
|
<ip addr of node04> node04
|
||||||
|
|
||||||
|
### 5.2: Install the SLURM Controller Packages
|
||||||
|
|
||||||
|
sudo apt install slurm-wlm -y
|
||||||
|
|
||||||
|
### 5.3: SLURM Configuration
|
||||||
|
|
||||||
|
We’ll use the default SLURM configuration file as a base. Copy it over:
|
||||||
|
|
||||||
|
cd /etc/slurm-llnl
|
||||||
|
cp /usr/share/doc/slurm-client/examples/slurm.conf.simple.gz .
|
||||||
|
gzip -d slurm.conf.simple.gz
|
||||||
|
mv slurm.conf.simple slurm.conf
|
||||||
|
|
||||||
|
Then edit /etc/slurm-llnl/slurm.conf.
|
||||||
|
|
||||||
|
**5.3.1: Set the control machine info.**
|
||||||
|
Modify the first configuration line to include the hostname of the master node, and its IP address:
|
||||||
|
|
||||||
|
SlurmctldHost=node01(<ip addr of node01>)
|
||||||
|
# e.g.: node01(192.168.1.14)
|
||||||
|
|
||||||
|
**5.3.2: Customize the scheduler algorithm.**
|
||||||
|
SLURM can allocate resources to jobs in a number of different ways, but for our cluster we’ll use the “consumable resources” method. This basically means that each node has a consumable resource (in this case, CPU cores), and it allocates resources to jobs based on these resources. So, edit the SelectType field and provide parameters, like so:
|
||||||
|
|
||||||
|
SelectType=select/cons_res
|
||||||
|
SelectTypeParameters=CR_Core
|
||||||
|
|
||||||
|
**5.3.3: Set the cluster name.
|
||||||
|
**This is somewhat superficial, but you can customize the cluster name in the “LOGGING AND ACCOUNTING” section:
|
||||||
|
|
||||||
|
ClusterName=glmdev
|
||||||
|
|
||||||
|
**5.3.4: Add the nodes.**
|
||||||
|
Now we need to tell SLURM about the compute nodes. Near the end of the file, there should be an example entry for the compute node. Delete it, and add the following configurations for the cluster nodes:
|
||||||
|
|
||||||
|
NodeName=node01 NodeAddr=<ip addr node01> CPUs=4 State=UNKNOWN
|
||||||
|
NodeName=node02 NodeAddr=<ip addr node02> CPUs=4 State=UNKNOWN
|
||||||
|
NodeName=node03 NodeAddr=<ip addr node03> CPUs=4 State=UNKNOWN
|
||||||
|
NodeName=node04 NodeAddr=<ip addr node04> CPUs=4 State=UNKNOWN
|
||||||
|
|
||||||
|
**5.3.5: Create a partition.**
|
||||||
|
SLURM runs jobs on ‘partitions,’ or groups of nodes. We’ll create a default partition and add our 3 compute nodes to it. Be sure to delete the example partition in the file, then add the following on one line:
|
||||||
|
|
||||||
|
PartitionName=mycluster Nodes=node[02-04] Default=YES MaxTime=INFINITE State=UP
|
||||||
|
|
||||||
|
5.3.6: Configure cgroups Support
|
||||||
|
The latest update of SLURM brought integrated support for [cgroups](https://en.wikipedia.org/wiki/Cgroups) kernel isolation, which restricts access to system resources. We need to tell SLURM what resources to allow jobs to access. To do this, create the file /etc/slurm-llnl/cgroup.conf:
|
||||||
|
|
||||||
|
CgroupMountpoint="/sys/fs/cgroup"
|
||||||
|
CgroupAutomount=yes
|
||||||
|
CgroupReleaseAgentDir="/etc/slurm-llnl/cgroup"
|
||||||
|
AllowedDevicesFile="/etc/slurm-llnl/cgroup_allowed_devices_file.conf"
|
||||||
|
ConstrainCores=no
|
||||||
|
TaskAffinity=no
|
||||||
|
ConstrainRAMSpace=yes
|
||||||
|
ConstrainSwapSpace=no
|
||||||
|
ConstrainDevices=no
|
||||||
|
AllowedRamSpace=100
|
||||||
|
AllowedSwapSpace=0
|
||||||
|
MaxRAMPercent=100
|
||||||
|
MaxSwapPercent=100
|
||||||
|
MinRAMSpace=30
|
||||||
|
|
||||||
|
Now, whitelist system devices by creating the file /etc/slurm-llnl/cgroup_allowed_devices_file.conf:
|
||||||
|
|
||||||
|
/dev/null
|
||||||
|
/dev/urandom
|
||||||
|
/dev/zero
|
||||||
|
/dev/sda*
|
||||||
|
/dev/cpu/*/*
|
||||||
|
/dev/pts/*
|
||||||
|
/clusterfs*
|
||||||
|
|
||||||
|
Note that this configuration is pretty permissive, but for our purposes, this is okay. You could always tighten it up to suit your needs.
|
||||||
|
|
||||||
|
### 5.4: Copy the Configuration Files to Shared Storage
|
||||||
|
|
||||||
|
In order for the other nodes to be controlled by SLURM, they need to have the same configuration file, as well as the Munge key file. Copy those to shared storage to make them easier to access, like so:
|
||||||
|
|
||||||
|
sudo cp slurm.conf cgroup.conf cgroup_allowed_devices_file.conf /clusterfs
|
||||||
|
sudo cp /etc/munge/munge.key /clusterfs
|
||||||
|
> A word about Munge:
|
||||||
|
> Munge is the access system that SLURM uses to run commands and processes on the other nodes. Similar to key-based SSH, it uses a private key on all the nodes, then requests are timestamp-encrypted and sent to the node, which decrypts them using the identical key. This is why it is so important that the system times be in sync, and that they all have the *munge.key* file.
|
||||||
|
|
||||||
|
### 5.5: Enable and Start SLURM Control Services
|
||||||
|
|
||||||
|
Munge:
|
||||||
|
|
||||||
|
sudo systemctl enable munge
|
||||||
|
sudo systemctl start munge
|
||||||
|
|
||||||
|
The SLURM daemon:
|
||||||
|
|
||||||
|
sudo systemctl enable slurmd
|
||||||
|
sudo systemctl start slurmd
|
||||||
|
|
||||||
|
And the control daemon:
|
||||||
|
|
||||||
|
sudo systemctl enable slurmctld
|
||||||
|
sudo systemctl start slurmctld
|
||||||
|
|
||||||
|
### 5.6: Reboot. (optional)
|
||||||
|
|
||||||
|
This step is optional, but if you are having problems with Munge authentication, or your nodes can’t communicate with the SLURM controller, try rebooting it.
|
||||||
|
|
||||||
|
## Step 6: Configure the Compute Nodes
|
||||||
|
|
||||||
|
### 6.1: Install the SLURM Client
|
||||||
|
|
||||||
|
sudo apt install slurmd slurm-client -y
|
||||||
|
|
||||||
|
### 6.2: /etc/hosts
|
||||||
|
|
||||||
|
Update the /etc/hosts file like we did on the master node. Add all of the nodes and their IP addresses to the /etc/hosts file of each node, excluding that node. Something like this:
|
||||||
|
|
||||||
|
node02:/etc/hosts
|
||||||
|
|
||||||
|
<ip addr> node01
|
||||||
|
<ip addr> node03
|
||||||
|
<ip addr> node04
|
||||||
|
|
||||||
|
### 6.3: Copy the Configuration Files
|
||||||
|
|
||||||
|
We need to make sure that the configuration on the compute nodes matches the configuration on the master node exactly. So, copy it over from shared storage:
|
||||||
|
|
||||||
|
sudo cp /clusterfs/munge.key /etc/munge/munge.key
|
||||||
|
sudo cp /clusterfs/slurm.conf /etc/slurm-llnl/slurm.conf
|
||||||
|
sudo cp /clusterfs/cgroup* /etc/slurm-llnl
|
||||||
|
|
||||||
|
### 6.4: Munge!
|
||||||
|
|
||||||
|
We will test that the Munge key copied correctly and that the SLURM controller can successfully authenticate with the client nodes.
|
||||||
|
|
||||||
|
**6.4.1: Enable and start Munge.**
|
||||||
|
|
||||||
|
sudo systemctl enable munge
|
||||||
|
sudo systemctl start munge
|
||||||
|
|
||||||
|
**6.4.2: Test Munge.
|
||||||
|
**We can manually test Munge to see if it is communicating. Run the following to generate a key on the master node and try to have the client node decrypt it. (Run this on the client.)
|
||||||
|
|
||||||
|
ssh pi@node01 munge -n | unmunge
|
||||||
|
|
||||||
|
If it works, you should see something like this:
|
||||||
|
|
||||||
|
pi@node02 ~> ssh node01 munge -n | unmunge
|
||||||
|
pi@node01's password:
|
||||||
|
STATUS: Success (0)
|
||||||
|
ENCODE_HOST: node01
|
||||||
|
ENCODE_TIME: 2018-11-15 15:48:56 -0600 (1542318536)
|
||||||
|
DECODE_TIME: 2018-11-15 15:48:56 -0600 (1542318536)
|
||||||
|
TTL: 300
|
||||||
|
CIPHER: aes128 (4)
|
||||||
|
MAC: sha1 (3)
|
||||||
|
ZIP: none (0)
|
||||||
|
UID: pi
|
||||||
|
GID: pi
|
||||||
|
LENGTH: 0
|
||||||
|
|
||||||
|
If you get an error, make sure that the /etc/munge/munge.key file is the same across all the different nodes, then reboot them all and try again.
|
||||||
|
|
||||||
|
### 6.5: Start the SLURM Daemon
|
||||||
|
|
||||||
|
sudo systemctl enable slurmd
|
||||||
|
sudo systemctl start slurmd
|
||||||
|
|
||||||
|
*Complete this configuration on each of the compute nodes.*
|
||||||
|
|
||||||
|
## Step 7: Test SLURM
|
||||||
|
|
||||||
|
Now that we’ve configured the SLURM controller and each of the nodes, we can check to make sure that SLURM can see all of the nodes by running sinfo on the master node (a.k.a. “the login node”):
|
||||||
|
|
||||||
|
PARTITION AVAIL TIMELIMIT NODES STATE NODELIST
|
||||||
|
mycluster* up infinite 3 idle node[02-04]
|
||||||
|
|
||||||
|
Now we can run a test job by telling SLURM to give us 3 nodes, and run the hostname command on each of them:
|
||||||
|
|
||||||
|
srun --nodes=3 hostname
|
||||||
|
|
||||||
|
If all goes well, we should see something like:
|
||||||
|
|
||||||
|
node02
|
||||||
|
node03
|
||||||
|
node04
|
||||||
|
|
||||||
|
## Going Forward
|
||||||
|
|
||||||
|
We now have a functional compute cluster using Raspberry Pis! You can now start submitting jobs to SLURM to be run on however many nodes you want. I’ll have a crash-course on SLURM in the future, but for now you can find a good overview in the documentation [here.](https://slurm.schedmd.com/overview.html)
|
||||||
|
|
||||||
|
You may notice that the cluster can’t really *do* much yet. In Part II of this guide, we’ll take a look at setting up some software and parallel computing on our mini-cluster.
|
||||||
|
|
||||||
|
[*Part II is available here.](https://medium.com/@glmdev/building-a-raspberry-pi-cluster-aaa8d1f3d2ca)*
|
||||||
|
|
||||||
|
[*So is Part III.](https://medium.com/@glmdev/building-a-raspberry-pi-cluster-f5f2446702e8?source=---------4------------------)*
|
||||||
|
|
||||||
|
— Garrett
|
||||||
|
|
||||||
|
### A Word on Troubleshooting
|
||||||
|
|
||||||
|
These guides are designed to be followed in a top-down sequential order. If you’re having problems with a command, feel free to leave a comment below with the exact number of the step you are stuck on, and I’ll try to answer if I can.
|
||||||
|
|
||||||
|
*Note: This guide was updated on July 22nd, 2019 to reflect changes to Raspbian Buster and SLURM config options.*
|
||||||
97
src/blog/posts/2019-02-15-spacewalk-part-1.md
Normal file
97
src/blog/posts/2019-02-15-spacewalk-part-1.md
Normal file
@@ -0,0 +1,97 @@
|
|||||||
|
---
|
||||||
|
layout: blog_post
|
||||||
|
title: Spacewalk for Linux Management - Part I
|
||||||
|
slug: Spacewalk-for-Linux-Management-Part-I
|
||||||
|
date: 2019-02-15 00:01:00
|
||||||
|
tags: blog
|
||||||
|
permalink: /blog/2019/02/15/Spacewalk-for-Linux-Management-Part-I/
|
||||||
|
blogtags:
|
||||||
|
- spacewalk
|
||||||
|
- linux
|
||||||
|
- tutorial
|
||||||
|
---
|
||||||
|
|
||||||
|
A Guide for the Uninitiated
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
I have recently switched over to using RPM based [Linux](https://www.youtube.com/watch?v=QlD9UBTcSW4) distributions on all of my machines as an exercise in learning to manage them. One tool that I really enjoyed on the Ubuntu/Debian side is Canonical’s [Landscape](https://landscape.canonical.com/) software. It’s free for a limited number of personal machines and it allows me to manage them centrally. When I switched over to CentOS VMs in my lab, I found the central space somewhat… lacking.
|
||||||
|
|
||||||
|
Enter: Spacewalk
|
||||||
|
|
||||||
|
Spacewalk is an open-source management platform for RHEL-derivative systems. It does a lot of the same things as Landscape, and even more. Unlike Landscape, though, the technical know-how bar-for-entry is a fair bit higher, and the documentation is a bit less beginner-friendly. So, I rolled up my sleeves, waded knee-deep into forum posts, the wiki, and StackOverflow questions to learn how to setup my own Spacewalk server and manage my lab VMs with it. So, I thought I would share my discoveries for those who, like me, want to learn to use Spacewalk, but find it daunting.
|
||||||
|
|
||||||
|
## Part I: Installing Spacewalk Server
|
||||||
|
|
||||||
|
This is my method for installing Spacewalk server on RHEL7 — this works for CentOS7 and Scientific7. Spacewalk is a system management and automation server for RHEL based systems.
|
||||||
|
> **Learn from my mistakes:**
|
||||||
|
> *If you’re installing Spacewalk in a VM, make sure you give it at least 25GB of space to be safe. I left it on the default 10GB, and the 6GB left-over after installing Scientific Linux 7 wasn’t enough space to initialize the Postgres database.*
|
||||||
|
|
||||||
|
### Install Spacewalk
|
||||||
|
|
||||||
|
Spacewalk depends on several [EPEL](https://fedoraproject.org/wiki/About_EPEL) (Extra-Packages for Enterprise Linux) packages, including OpenJDK, so we’ll make sure the EPEL repository is installed:
|
||||||
|
|
||||||
|
`# yum install epel-release`
|
||||||
|
|
||||||
|
Now, we’ll install the Spacewalk repository:
|
||||||
|
|
||||||
|
`# rpm -Uvh https://copr-be.cloud.fedoraproject.org/results/@spacewalkproject/spacewalk-2.9/epel-7-x86_64/00830557-spacewalk-repo/spacewalk-repo-2.9-4.el7.noarch.rpm`
|
||||||
|
|
||||||
|
It’s also a good idea to make sure that your system is up to date before making any big changes:
|
||||||
|
|
||||||
|
`# yum clean metadata && yum update`
|
||||||
|
|
||||||
|
Spacewalk requires a database back-end to store information about packages/systems/etc. By default, it can configure and install PostgreSQL:
|
||||||
|
|
||||||
|
`# yum install spacewalk-setup-postgresql`
|
||||||
|
|
||||||
|
Finally, install Spacewalk and tell it to auto-configure the Postgres back-end:
|
||||||
|
|
||||||
|
`# yum install spacewalk-postgresql`
|
||||||
|
|
||||||
|
(This installs several hundred packages, so it will take a while.)
|
||||||
|
|
||||||
|
### Configure the Firewall
|
||||||
|
|
||||||
|
Spacewalk uses HTTP/S to communicate with the client machines. Port 5222 is also opened, which allows the Spacewalk server to push instant (or near-instant) commands to the client machines over a tunnel. The following commands configure the default firewall on CentOS 7.
|
||||||
|
|
||||||
|
**Enable HTTPS:**
|
||||||
|
`# firewall-cmd --add-service=https --permanent`
|
||||||
|
|
||||||
|
**Enable HTTP:**
|
||||||
|
`# firewall-cmd --add-service=http --permanent`
|
||||||
|
|
||||||
|
**Enable Port 5222:**
|
||||||
|
`# firewall-cmd --add-port=5222/tcp --permanent`
|
||||||
|
`# firewall-cmd --add-port=5222/udp --permanent`
|
||||||
|
|
||||||
|
**Reload the Firewall:**
|
||||||
|
`# firewall-cmd --reload`
|
||||||
|
|
||||||
|
### Configure Spacewalk
|
||||||
|
|
||||||
|
Spacewalk requires a [FQDN](https://www.godaddy.com/garage/whats-a-fully-qualified-domain-name-fqdn-and-whats-it-good-for/) (fully-qualified domain name) for the server to function properly. If you’re working in an environment with a local DNS server, set it up that way. If you’re not (most aren’t), modify the /etc/hosts file to include the following, or similar to your environment. The /etc/hosts file contains a series of aliases between IP addresses and domain names that are local to the machine the file is hosted on. Modify it by editing the /etc/hosts file in your favorite text editor. Add the following line:
|
||||||
|
|
||||||
|
###.###.###.### {hostname}.{yourdomain}.local {hostname}
|
||||||
|
|
||||||
|
Replace ###.###.###.### with the local IP of the Spacewalk server machine.
|
||||||
|
Replace {hostname} with the host-name of the machine.
|
||||||
|
Replace {yourdomain} with some local domain. Usually, it’s a good idea to suffix it with .local to make sure that it doesn’t overlap with actual domain space.
|
||||||
|
|
||||||
|
Now, run the following command to start the Spacewalk configuration wizard:
|
||||||
|
|
||||||
|
`# spacewalk-setup`
|
||||||
|
|
||||||
|
You’ll need to provide the following:
|
||||||
|
|
||||||
|
* An administrator’s e-mail address
|
||||||
|
|
||||||
|
* Confirmation to configure Apache2 with default SSL settings
|
||||||
|
|
||||||
|
* A CA certificate password for the Spacewalk self-signed certificate
|
||||||
|
|
||||||
|
* Organization and location information for said certificate
|
||||||
|
|
||||||
|
* Confirmation to enable tftp and xinetd
|
||||||
|
|
||||||
|
After the wizard completes, we can open the web portal by visiting the FQDN of the host. You’ll receive a certificate error because the certificate is self-signed by the Spacewalk server machine. This means that the certificate authority (which we created during the Spacewalk setup wizard) isn’t registered with your web browser. Add an exception and continue. You’ll then be prompted to create an administrative user for your organization. After creating the user, you’ll be dropped at the Spacewalk portal!
|
||||||
101
src/blog/posts/2019-03-04-spacewalk-part-2.md
Normal file
101
src/blog/posts/2019-03-04-spacewalk-part-2.md
Normal file
@@ -0,0 +1,101 @@
|
|||||||
|
---
|
||||||
|
layout: blog_post
|
||||||
|
title: Spacewalk for Linux Management - Part II
|
||||||
|
slug: Spacewalk-for-Linux-Management-Part-II
|
||||||
|
date: 2019-03-04 00:01:00
|
||||||
|
tags: blog
|
||||||
|
permalink: /blog/2019/03/04/Spacewalk-for-Linux-Management-Part-II/
|
||||||
|
blogtags:
|
||||||
|
- spacewalk
|
||||||
|
- linux
|
||||||
|
- tutorial
|
||||||
|
---
|
||||||
|
## Setting Up Spacewalk Channels - Part II
|
||||||
|
|
||||||
|
*This is part 2 in my series of articles on how to use Spacewalk to manage Linux clients.*
|
||||||
|
|
||||||
|
RedHat Satellite, and by extension Spacewalk, uses a system of channels to organize the software and configuration available to registered systems. In fact, those are the two main types of channels: software and configuration. Software channels contain a collection of repositories and packages that are made available to systems subscribed to that channel. Configuration channels contain a number of centrally-managed configuration files that can be deployed to systems registered in that channel.
|
||||||
|
|
||||||
|
In this guide, we’ll look at basic setup of each type.
|
||||||
|
|
||||||
|
Software channels are particularly useful for managing groups of similar computers for a number of reasons. First, it allows you to dynamically control what repositories the machines pull software from, without having to configure the individual machines. Second, because Spacewalk caches a local copy of the repositories in each channel (and can sync it regularly), it can greatly reduce bandwidth usage. Instead of 100 machines each downloading the same updates directly, Spacewalk downloads them once and each of the 100 machines just retrieves them from Spacewalk.
|
||||||
|
|
||||||
|
Configuration channels are similarly useful for groups of similar machines. Configuration files can be added and versioned in the Spacewalk interface, then deployed to registered machines. This guarantees that all the machines in a given group have the same configuration for things like SSH, Apache2, SSSD, PAM, bashrc, profile.d, cron.daily, and whatever else.
|
||||||
|
|
||||||
|
In this guide, we’ll look at setting up software channels to manage a group of CentOS 7 machines, but this can be adapted to work for any RPM or DEB distribution.
|
||||||
|
|
||||||
|
## Creating Software Channels
|
||||||
|
|
||||||
|
### Create a Base Channel
|
||||||
|
|
||||||
|
Sign in to the Spacewalk web portal. Then, navigate to **Channels > Manage Software Channels > Create Channel**. Fill in the channel name and label (these are usually the same) and the summary. Then, click **Create Channel**.
|
||||||
|
|
||||||
|
We’re going to start off by creating a base channel for CentOS 7 machines.
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
### Add the Repositories
|
||||||
|
|
||||||
|
Next, we’ll add the CentOS7 base repositories to our channel. Navigate to **Manage Repositories > Create Repository**. Fill in the repository label, repository URL, and select the repository type. For example, for the CentOS7 os repository:
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
*Note: The repository URL should be the location that contains the *repodata* directory.*
|
||||||
|
|
||||||
|
In this example, I repeated this process to add the CentOS7 extras and updates repositories, which have similar repository URLs.
|
||||||
|
|
||||||
|
### Assign Repositories to the Channel
|
||||||
|
|
||||||
|
We need to tell the base channel we created to use the repositories we just added. To do this, navigate to **Channels > Manage Software Channels > *channel name* > Repositories**. Here, select the repositories we just added and click **Update Repositories**.
|
||||||
|
|
||||||
|
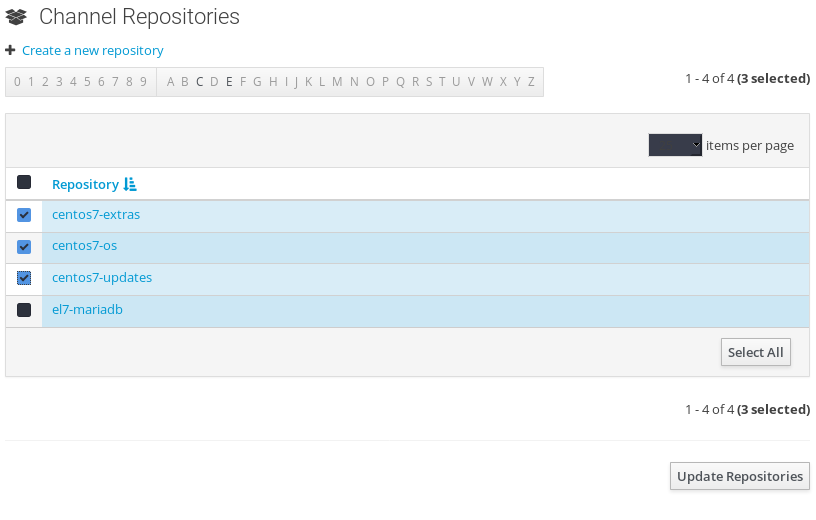
|
||||||
|
|
||||||
|
### Create a Child Channel
|
||||||
|
|
||||||
|
We’re also going to create a child channel. This channel will fall under the base CentOS 7 channel we created, but it will provide additional repositories and software. Which is to say, machines registered to our child channel will have access to the software provided by both the parent and child channels’ repositories. As an example, we’re going to create a channel that provides the MariaDB repositories for CentOS 7. To do this, basically repeat the same process.
|
||||||
|
|
||||||
|
Navigate to **Channels > Manage Software Channels > Create Channel**. Provide a channel name, label, and summary. This time, in the **Parent Channel** drop-down, select the centos7-base channel we created earlier. This will establish the new channel as a child of that channel.
|
||||||
|
|
||||||
|
### Add the Repository
|
||||||
|
|
||||||
|
Navigate to **Channels > Manage Software Channels > Manage Repositories > Create Repository**. Provide the name, URL, and type of the MariaDB repository.
|
||||||
|
|
||||||
|
In our example, we used the following:
|
||||||
|
|
||||||
|
**Repository name:** el7-mariadb
|
||||||
|
**Repository URL:** [http://yum.mariadb.org/10.3/centos7-amd64/](http://yum.mariadb.org/10.3/centos7-amd64/)
|
||||||
|
**Repository type:** yum
|
||||||
|
|
||||||
|
### Assign the Repository to the Channel
|
||||||
|
|
||||||
|
Navigate to **Channels > Manage Software Channels > *child channel name* > Repositories**. Select the MariaDB repository we just added, and click Update Repositories.
|
||||||
|
|
||||||
|
### Syncing Repository Packages
|
||||||
|
|
||||||
|
Spacewalk caches local copies of all the packages for the repositories we add. This allows it to offer those packages to registered clients with lower internet bandwidth costs, especially across larger deployments. Since all of our CentOS 7 clients will already have access to the main repositories, we won’t bother caching the entirety of the CentOS mirror for this example (though if you wish to do so, the process below is the same). We will, however, sync the much smaller MariaDB repository so our clients can access its packages.
|
||||||
|
|
||||||
|
To do this, navigate to **Channels > Manage Software Channels > *MariaDB channel* > Repositories > Sync > Sync Now**. This will manually start downloading and indexing the packages from the repositories. On the same page, you can create a schedule to automatically sync the repositories.
|
||||||
|
> **Note:* **
|
||||||
|
This will take a while, even if the repository is relatively small. One way to view the progress of the sync process is by navigating to /var/sattelite/redhat/1/stage on the Spacewalk host. The stage folder is where Spacewalk downloads the packages to before it sorts them to other folders in the 1 directory (where 1 is the ID of the Spacewalk group in question). You can roughly gauge the sync process by seeing how many packages are in this folder.*
|
||||||
|
|
||||||
|
When the sync process finishes, you should be able to view all the repository’s packages by navigating to **Channels > Manage Software Channels > *MariaDB channel* > Packages > List / Remove Packages**.
|
||||||
|
> **Note:**
|
||||||
|
*One thing to consider when syncing repositories is how much space they will require. By default, CentOS 7, which is the OS we set up Spacewalk on, provides a much smaller root directory partition than /home partition. Make sure the repositories you are syncing can fit in the allotted partition, or use custom partitioning in the CentOS install.*
|
||||||
|
|
||||||
|
## Creating Configuration Channels
|
||||||
|
|
||||||
|
Similar to software channels, Spacewalk uses configuration channels to make custom configuration files available to clients subscribed to that channel. These configuration files can be pushed to the clients from the Spacewalk control panel. In this example, we’ll create a configuration channel with a fake configuration file, /root/test.conf.
|
||||||
|
|
||||||
|
### Create the Configuration Channel
|
||||||
|
|
||||||
|
Navigate to **Configuration > Configuration Channels > Create Config Channel**. Give the channel a name, label, and brief description.
|
||||||
|
|
||||||
|
### Add the Configuration File
|
||||||
|
|
||||||
|
To add the test configuration file, navigate to **Configuration > Configuration Channels > *test channel* > Add Files > Create File**. Give the file a fully-qualified filename. That is, /root/test.conf. You can change the file owner and permissions, then fill in the contents in the text field below.
|
||||||
|
|
||||||
|
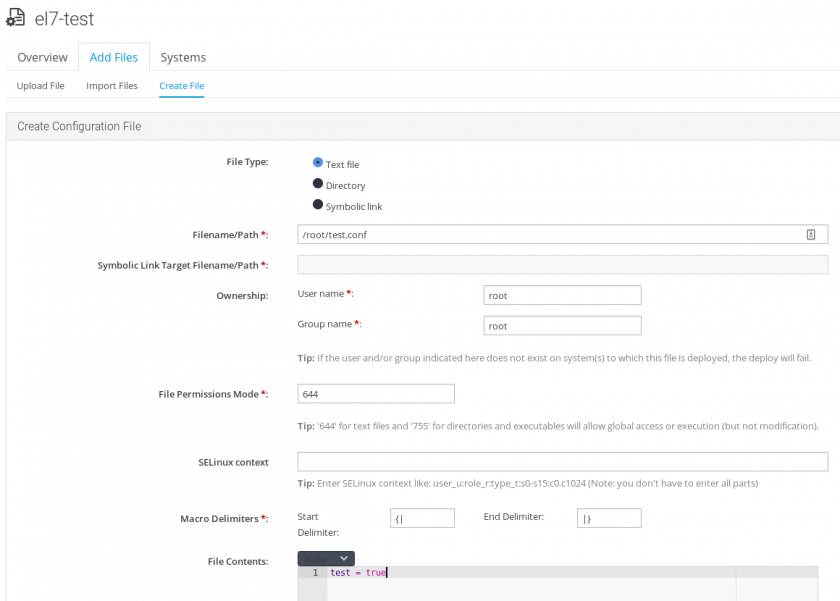
|
||||||
|
|
||||||
|
Then click **Create Configuration File**. Spacewalk will save the configuration file. You’ll notice that it drops you on a page called “Revision 1 of /root/test.conf.” This is because Spacewalk will allow you to revise your configuration files and it will track the changes. You can deploy different revisions to different hosts.
|
||||||
|
> **Learn from my mistakes:***
|
||||||
|
By default, adding an external repository to a channel (like the MariaDB repository) doesn’t add its GPG key to the registered hosts. This means that, without providing the GPG key to the clients, they will be unable to install the software. We’ll cover this in the Registering Clients section, but this can be done by pushing the GPG key via a configuration channel to /etc/pki/rpm-gpg and importing it via rpm. Alternatively, add the GPG key in the child channel’s settings when it is created.*
|
||||||
110
src/blog/posts/2019-03-13-spacewalk-part-3.md
Normal file
110
src/blog/posts/2019-03-13-spacewalk-part-3.md
Normal file
@@ -0,0 +1,110 @@
|
|||||||
|
---
|
||||||
|
layout: blog_post
|
||||||
|
title: Spacewalk for Linux Management - Part III
|
||||||
|
slug: Spacewalk-for-Linux-Management-Part-III
|
||||||
|
date: 2019-03-13 00:01:00
|
||||||
|
tags: blog
|
||||||
|
permalink: /blog/2019/03/13/Spacewalk-for-Linux-Management-Part-III/
|
||||||
|
blogtags:
|
||||||
|
- spacewalk
|
||||||
|
- linux
|
||||||
|
- tutorial
|
||||||
|
---
|
||||||
|
|
||||||
|
## Registering Spacewalk Clients - Part III
|
||||||
|
|
||||||
|
*This series is based on a collection of articles on my personal knowledge-base about how to use Spacewalk to manage Linux systems.*
|
||||||
|
|
||||||
|
Now that we’ve set up Spacewalk server and created some software and configuration channels, we can register clients against the server and set them up to be managed by Spacewalk. This is done by creating an activation key in the Spacewalk server, installing the client services on the remote machines, then using the activation key to register them.
|
||||||
|
|
||||||
|
## Create an Activation Key
|
||||||
|
|
||||||
|
Log in to the Spacewalk administration panel and navigate to **Systems > Activation Keys > Create Key**. Give your key a description, key-code for remote systems (this will be used to register them), select the base channel for systems registered with the key, and (optionally) limit the number of times the key can be used. If you leave the “Usage” box blank, the key can be used to register an unlimited number of systems.
|
||||||
|
|
||||||
|
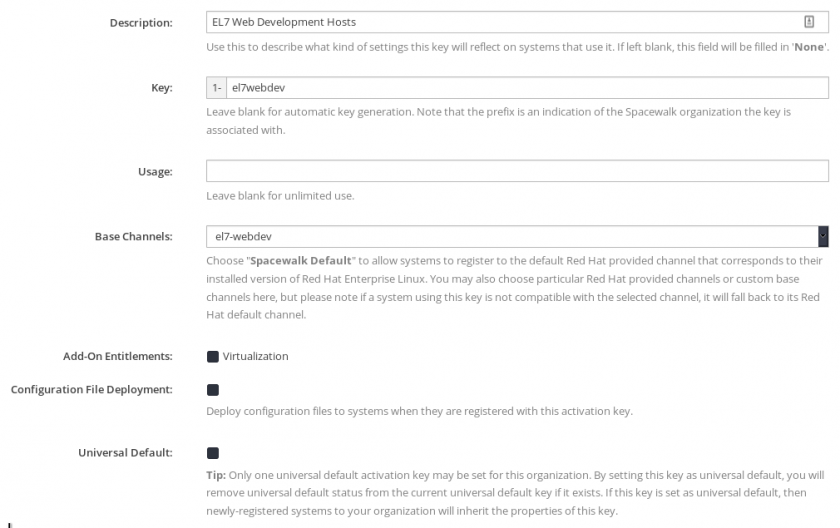
|
||||||
|
|
||||||
|
### Customize Activation Key Packages
|
||||||
|
|
||||||
|
You can configure Spacewalk to automatically install a list of packages on clients when they are registered with a given activation code. You can configure this by navigating to **Systems > Activation Keys > *key name* > Packages **and entering a list of package names with one package per line. These packages should be available in the channels with which the activation key is associated.
|
||||||
|
|
||||||
|
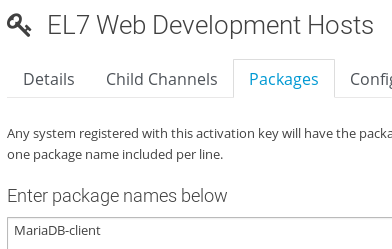
|
||||||
|
|
||||||
|
You can also customize the child channel that the systems will join by navigating to **Systems > Activation Keys > *key name* > Child Channels** and selecting it there.
|
||||||
|
|
||||||
|
## Register Client Systems
|
||||||
|
|
||||||
|
Now that we have software and configuration channels created and registered with an activation key, we can register client systems to be managed by the Spacewalk server.
|
||||||
|
|
||||||
|
### Prerequisites (EL7)
|
||||||
|
|
||||||
|
The Spacewalk client packages have dependencies in the [EPEL repositories](https://fedoraproject.org/wiki/About_EPEL). Install those:
|
||||||
|
|
||||||
|
`# yum install epel-release -y`
|
||||||
|
|
||||||
|
Next, install the EL7 Spacewalk client repository:
|
||||||
|
|
||||||
|
`# rpm -Uvh https://copr-be.cloud.fedoraproject.org/results/@spacewalkproject/spacewalk-2.9/epel-7-x86_64/00830557-spacewalk-repo/spacewalk-client-repo-2.9-4.el7.noarch.rpm`
|
||||||
|
|
||||||
|
Finally, install the required client packages:
|
||||||
|
|
||||||
|
`# yum install -y rhn-client-tools rhn-check rhn-setup rhnsd m2crypto yum-rhn-plugin osad rhncfg-actions rhncfg-management`
|
||||||
|
|
||||||
|
### Prerequisites (Fedora)
|
||||||
|
|
||||||
|
Install the Fedora Spacewalk client repository:
|
||||||
|
|
||||||
|
`# dnf copr enable @spacewalkproject/spacewalk-2.9-client`
|
||||||
|
|
||||||
|
Install the required client packages:
|
||||||
|
|
||||||
|
`# dnf -y install rhn-client-tools rhn-check rhn-setup rhnsd m2crypto dnf-plugin-spacewalk osad rhncfg-actions rhncfg-management`
|
||||||
|
> **For the interested:**
|
||||||
|
> *rhncfg-actions and rhncfg-management are daemons that allow Spacewalk to manage configuration files*
|
||||||
|
> *osad is a real-time messaging daemon that Spacewalk uses to communicate with the host*
|
||||||
|
> *yum-rhn-plugin is a plugin for YUM that allows Spacewalk to dynamically manage the repositories it has access to*
|
||||||
|
> *m2crypto is a Python wrapper for OpenSSL that secures communications between Spacewalk clients and the server*
|
||||||
|
> *rhnsd and rhn-check are tools and background services that polls the Spacewalk server to check for new actions*
|
||||||
|
> *rhn-client-tools and rhn-setup provide the core functionality of Spacewalk management and setup processes*
|
||||||
|
|
||||||
|
### Install the Spacewalk Server CA Certificate
|
||||||
|
|
||||||
|
Spacewalk uses a self-signed SSL certificate to communicate with the registered clients. This prevents 3rd-parties from intercepting and modifying Spacewalk communications. To allow Spacewalk to manage the clients, we need to install the Spacewalk server’s certificate authority. This can be done two ways.
|
||||||
|
|
||||||
|
Copy the CA file manually (not recommended):
|
||||||
|
|
||||||
|
`# scp root@*spacewalk.server.url*:/root/ssl-build/RHN-ORG-TRUSTED-SSL-CERT /usr/share/rhn/RHN-ORG-TRUSTED-SSL-CERT`
|
||||||
|
|
||||||
|
Install the generated CA package (recommended):
|
||||||
|
|
||||||
|
`# rpm -Uvh http://*spacewalk.server.url*/pub/rhn-org-trusted-ssl-cert-1.0-1.noarch.rpm`
|
||||||
|
|
||||||
|
### Register the Spacewalk Clients
|
||||||
|
|
||||||
|
We can now register the client against Spacewalk server. Depending on how many packages your activation key specifies to install, this may take a while.
|
||||||
|
|
||||||
|
`# rhnreg_ks --activationkey="1-*yourkeyhere*" --serverUrl=http://*spacewalk.server.url*/XMLRPC --sslCACert=/usr/share/rhn/RHN-ORG-TRUSTED-SSL-CERT`
|
||||||
|
> **Learn from my mistakes:**
|
||||||
|
> *Spacewalk server supports multiple organizations per server. As such, it prefixes each activation key with the ID number of the organization. In most cases (i.e. if you’re only using Spacewalk with one organization), this ID number is “1”. Hence, you need to prefix the activation code you created with 1- to specify the organization.*
|
||||||
|
|
||||||
|
Now, do an initial sync with the Spacewalk server:
|
||||||
|
|
||||||
|
`# rhn-profile-sync`
|
||||||
|
|
||||||
|
### Enable Required Background Services
|
||||||
|
|
||||||
|
Spacewalk relies on either a real-time messaging daemon or periodic check-ins from registered systems to push management actions. As such, we need to enable the OSA Daemon service and enable all RHN control actions (which Spacewalk uses to push centrally-managed configuration files).
|
||||||
|
```
|
||||||
|
# systemctl enable osad
|
||||||
|
# systemctl restart osad
|
||||||
|
# rhn-actions-control --enable-all
|
||||||
|
```
|
||||||
|
|
||||||
|
Finally, it’s a good idea to do one last profile sync to make sure Spacewalk sees that the required daemons are running:
|
||||||
|
|
||||||
|
`# rhn-profile-sync`
|
||||||
|
|
||||||
|
### Success!
|
||||||
|
|
||||||
|
At this point, you should be able to navigate to **Spacewalk > Systems** and see the newly registered systems.
|
||||||
|
|
||||||
|
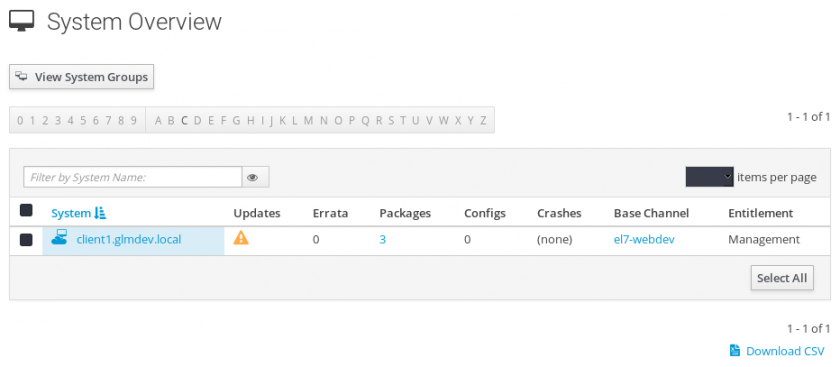
|
||||||
47
src/blog/posts/2019-03-19-flitter-overview.md
Normal file
47
src/blog/posts/2019-03-19-flitter-overview.md
Normal file
@@ -0,0 +1,47 @@
|
|||||||
|
---
|
||||||
|
layout: blog_post
|
||||||
|
title: 'Flitter Framework: Cohesive Express.js'
|
||||||
|
slug: Flitter-Framework-Cohesive-Express-js
|
||||||
|
date: 2019-03-19 00:01:00
|
||||||
|
tags: blog
|
||||||
|
permalink: /blog/2019/03/19/Flitter-Framework-Cohesive-Express-js/
|
||||||
|
blogtags:
|
||||||
|
- flitter
|
||||||
|
- webdev
|
||||||
|
---
|
||||||
|
|
||||||
|
My take on a Node.js framework, based on Express.
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
*This is the first part in my series on Flitter, my Express-based web app framework. This first post is an introduction to Flitter and the motivation behind it. There will be more parts to come, but for a crash-course, [check out the documentation.](https://flitter.garrettmills.dev/tutorial-getting-started-0.html)*
|
||||||
|
|
||||||
|
**I love Express.** I think it’s wonderfully extensible, modular, and dynamic. However, when building Express-based apps, I’ve noticed that there are quite a few things that I find myself repeating. Enough, that I decided to standardize the steps into my own framework: *Flitter*.
|
||||||
|
|
||||||
|
*The Bigger Flitter*
|
||||||
|
|
||||||
|
Flitter is a full-stack model-view-controller framework built using various Express packages. It is designed to provide a more cohesive environment for developing with Express. However, unlike some other frameworks, Flitter isn’t supposed to *replace *Express in your app, but rather complement it.
|
||||||
|
|
||||||
|
Flitter includes a Unit-based startup system so various underlying functionality in Flitter is broken into manageable, extensible chunks. These chunks provide commonly used things like sessions, MongoDB access, database models, controllers, the Pug view engine, middleware, and an interactive shell.
|
||||||
|
|
||||||
|
This means that Flitter does a lot of the initial hard work for you — it provides a simple way to define structures like models, routes, controllers, middleware, etc. These structures are imported by Flitter and are passed to their respective sub-components (Mongoose, Express, Pug).
|
||||||
|
|
||||||
|
### All you have to do is write the logic for your app.
|
||||||
|
|
||||||
|
Flitter also provides a coherent system for add-on packages. These packages can be created by 3rd parties (or myself) to enable additional functionality in Flitter. Because Flitter’s functionality is already broken up into chunks, creating these packages is trivial — simply add their units.
|
||||||
|
|
||||||
|
### I developed Flitter for a number of reasons:
|
||||||
|
|
||||||
|
First, I didn’t like how hard to understand other frameworks like AdonisJS and Sails are. Not necessarily their functionality, but how they work under the hood. Flitter is broken up into parts so it can be easily understood and modified.
|
||||||
|
|
||||||
|
Second, I use the functionality provided by Flitter a *lot. *So, Flitter is a generic implementation of how I would start every Node.js application I write. This is useful for me. I decided to spin if off as a framework so it will hopefully be useful for you, too.
|
||||||
|
|
||||||
|
Third, let’s be honest — I wanted to learn how to build a framework. I think it has been a good opportunity to expand my ES6 skills, and it has taught me how Express and Node.js work at a much deeper level. Plus, it’s just fun.
|
||||||
|
|
||||||
|
### Flitter is free as in freedom.
|
||||||
|
|
||||||
|
It’s also open-source and developed [over on my Git server.](https://code.garrettmills.dev/flitter) Contributions/suggestions/bug reports are welcome! I also dog-food Flitter — it runs [my website](https://glmdev.tech/) and several other projects I use.
|
||||||
|
|
||||||
|
### How do I get started?
|
||||||
|
|
||||||
|
Interested? Great! In the subsequent parts in this series, I’ll walk through creating a sample app using Flitter. But, Flitter is fully-documented, so you can check out the [documentation here to get started.](https://flitter.garrettmills.dev/)
|
||||||
243
src/blog/posts/2019-04-01-rpi-part-2.md
Normal file
243
src/blog/posts/2019-04-01-rpi-part-2.md
Normal file
@@ -0,0 +1,243 @@
|
|||||||
|
---
|
||||||
|
layout: blog_post
|
||||||
|
title: Building a Raspberry Pi Cluster - Part II
|
||||||
|
slug: Building-a-Raspberry-Pi-Cluster-Part-II
|
||||||
|
date: 2019-04-01 01:00:00
|
||||||
|
tags: blog
|
||||||
|
permalink: /blog/2019/04/01/Building-a-Raspberry-Pi-Cluster-Part-II/
|
||||||
|
blogtags:
|
||||||
|
- tutorial
|
||||||
|
- raspberry pi
|
||||||
|
- hosting
|
||||||
|
---
|
||||||
|
|
||||||
|
Part II — Some Simple Jobs
|
||||||
|
|
||||||
|
*This is Part II in my series on building a small-scale HPC cluster. [Check out Part I](https://medium.com/@glmdev/building-a-raspberry-pi-cluster-784f0df9afbd?source=---------8------------------) and [Part III](https://medium.com/@glmdev/building-a-raspberry-pi-cluster-f5f2446702e8?source=---------4------------------).*
|
||||||
|
|
||||||
|
Now that we have our cluster up and running, we can start running jobs on it. While the specific applications of your cluster are up to you, in the rest of this series I will be looking at how to set up a few different pieces of software, as well as how to use the actual cluster scheduler, Slurm.
|
||||||
|
|
||||||
|
In this part, we will dive into some Slurm basics, set up some software on our cluster the easy way, and create some example jobs that run many, many individual tasks making use of the scheduler.
|
||||||
|
|
||||||
|
In the next part, we’ll look closer at how to install software the harder (better) way, how to set up Open MPI, and create some sample jobs that run just a few tasks across several nodes on the cluster.
|
||||||
|
|
||||||
|
## 1. Slurm Basics
|
||||||
|
|
||||||
|
As discussed before, Slurm is a piece of software called a scheduler. This allows you to submit jobs that request a specific amount of resources like CPU cores, memory, or whole compute nodes. The scheduler will run each job as the resources become available. This means that we can chuck as many jobs as we want at it, and it’ll figure it out for us. But, enough theory, let’s get our hands dirty.
|
||||||
|
|
||||||
|
### 1.a. Basic Slurm Commands
|
||||||
|
|
||||||
|
Slurm provides several useful command line tools that we’ll use to interface with the cluster. Log into your master/login node that we set up last time:
|
||||||
|
|
||||||
|
ssh pi@node01
|
||||||
|
|
||||||
|
The first command we’ll look at is sinfo. This is pretty straight forward, it just provides information about the cluster:
|
||||||
|
|
||||||
|
$ sinfo
|
||||||
|
|
||||||
|
PARTITION AVAIL TIMELIMIT NODES STATE NODELIST
|
||||||
|
glmdev* up infinite 3 mix node[1–3]
|
||||||
|
|
||||||
|
Here, we have the name of the partition, whether it can be used, the default time limit, the number of nodes and their states. The state “mix” occurs when a node has a job running on it, but it still has some available resources. (Such as when only 1 core is used.)
|
||||||
|
|
||||||
|
### srun — schedule commands
|
||||||
|
|
||||||
|
The srun command is awesome. It is used to directly run a command on however many nodes/cores you want. Let’s test it out:
|
||||||
|
|
||||||
|
$ srun --nodes=3 hostname
|
||||||
|
node1
|
||||||
|
node2
|
||||||
|
node3
|
||||||
|
|
||||||
|
Here, we ran the hostname command on 3 nodes. This is different than running it on 3 cores, which may all be on the same node:
|
||||||
|
|
||||||
|
$ srun --ntasks=3 hostname
|
||||||
|
node1
|
||||||
|
node1
|
||||||
|
node1
|
||||||
|
|
||||||
|
Here, ntasks refers to the number of processes. This is effectively the number of cores on which the command should be run. These are not necessarily on different machines. Slurm just grabs the next available cores.
|
||||||
|
|
||||||
|
We can also combine the two:
|
||||||
|
|
||||||
|
$ srun --nodes=2 --ntasks-per-node=3 hostname
|
||||||
|
node1
|
||||||
|
node2
|
||||||
|
node2
|
||||||
|
node1
|
||||||
|
node2
|
||||||
|
node1
|
||||||
|
|
||||||
|
This runs the command on 2 nodes and launches 3 tasks per node, effectively 6 tasks.
|
||||||
|
|
||||||
|
### squeue — view scheduled jobs
|
||||||
|
|
||||||
|
When you start running longer and longer jobs, it is useful to check their status. To do this, run the squeue command. By default, it displays all jobs submitted by all users, and their states:
|
||||||
|
|
||||||
|
$ squeue
|
||||||
|
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
|
||||||
|
609 glmdev 24.sub.s pi R 10:16 1 node2
|
||||||
|
|
||||||
|
Most of this info is pretty self-explanatory. The only thing I’ll note is the ST column, which is the state of the job. R means that the job is running. Here’s the [full list of state codes](https://slurm.schedmd.com/squeue.html#lbAG).
|
||||||
|
|
||||||
|
### scancel — cancel a scheduled job
|
||||||
|
|
||||||
|
Once a job has been scheduled, it can be cancelled using the scancel command:
|
||||||
|
|
||||||
|
$ scancel 609
|
||||||
|
|
||||||
|
(where 609 is the JOBID that you want to cancel) Note that you can only cancel jobs started by your user.
|
||||||
|
|
||||||
|
### sbatch — schedule a batch script
|
||||||
|
|
||||||
|
sbatch is really the meat & potatoes of the Slurm scheduler. It’s what we use most often when we want to schedule a job to run on the cluster. This command takes a number of flags and configuration, as well as a shell file. That shell file is then executed once and whatever requested resources (nodes/cores/etc) are made available to it. Let’s create a basic job as an example.
|
||||||
|
|
||||||
|
***The Batch File
|
||||||
|
***Our job begins with the definition of a batch file. This batch file is usually a bash script that runs our job, however it looks a bit different. We’ll create the file /clusterfs/helloworld.sh:
|
||||||
|
|
||||||
|
#!/bin/bash
|
||||||
|
#SBATCH --nodes=1
|
||||||
|
#SBATCH --ntasks-per-node=1
|
||||||
|
#SBATCH --partition=<partition name>
|
||||||
|
|
||||||
|
cd $SLURM_SUBMIT_DIR
|
||||||
|
|
||||||
|
echo "Hello, World!" > helloworld.txt
|
||||||
|
|
||||||
|
The file begins with a [shebang](https://en.wikipedia.org/wiki/Shebang_(Unix)). This is required, as it tells Slurm how to execute your job. This is followed by a number of flags that take the following form:
|
||||||
|
|
||||||
|
#SBATCH <flag>
|
||||||
|
|
||||||
|
These flags simply any [parameters](https://slurm.schedmd.com/sbatch.html) that can be passed to the sbatch command. These nearly identical to those used by the srun command, but with one main difference: jobs aren’t automatically re-launched on each specified node/core.
|
||||||
|
|
||||||
|
Rather, each job is run on the first core of the first node allocated it, but the job is given access to the other nodes it has requested. More on that later.
|
||||||
|
|
||||||
|
The cd $SLURM_SUBMIT_DIR guarantees that our job is running in whatever directory it was submitted from. In our case, this is /clusterfs.
|
||||||
|
|
||||||
|
Now, we can tell Slurm to schedule and run our job:
|
||||||
|
|
||||||
|
$ sbatch ./helloworld.sh
|
||||||
|
Submitted batch job 639
|
||||||
|
|
||||||
|
Since our job is very simple, it should be done basically immediately. If everything has gone according to plan, we should see the /clusterfs/helloworld.txt file that we created.
|
||||||
|
|
||||||
|
**Output
|
||||||
|
**You’ll notice that the job doesn’t output anything to the shell, which makes sense. If you had a job running for 4 hours, it’s not very useful to have to have a terminal open the whole time to get output. Instead, Slurm outputs standard error and standard out to a file in the format slurm-XXX.out where XXX is the Job’s ID number.
|
||||||
|
|
||||||
|
## 2. Our First Project
|
||||||
|
|
||||||
|
For our first project on the cluster, we’re going to do some statistics! Data processing is a big part of what HPC clusters are used for. So, we’re going to build a simple R program that generates some random values following a normal distribution, then creates a histogram and graph of those values and outputs them to an image file. Then, we’re going to create a script to generate 50 of them using the scheduler.
|
||||||
|
|
||||||
|
**Goal:** Output 50 randomly-generated normal distribution graphs & histograms to a folder, as images using R.
|
||||||
|
|
||||||
|
### 2.a. Set-Up
|
||||||
|
|
||||||
|
Before we can start building our project, we need to install R. For those unfamiliar, [R is a programming language](https://www.r-project.org/) for statistical programming. This makes it very well-suited for our task.
|
||||||
|
|
||||||
|
Now, there are several ways to install software on a cluster. Chiefly, the good way and the lazy way. We’ll cover a better way in the next part, so for now, we’ll use the lazy way. That is, we’ll install R from the repos on each node.
|
||||||
|
|
||||||
|
However, we are *not* going to do them one-by-one. We have a shiny new scheduler, remember? So, we’re going to cheat and use srun:
|
||||||
|
|
||||||
|
$ sudo su -
|
||||||
|
# srun --nodes=3 apt install r-base -y
|
||||||
|
|
||||||
|
This will run the apt install r-base -y command on all of the nodes in the cluster (change the 3 to match your setup). This will probably take a while, but when it completes, you should be able to use R on any of the nodes:
|
||||||
|
|
||||||
|
pi@node2 ~$ R --version
|
||||||
|
R version 3.3.3 (2017-03-06) -- "Another Canoe"
|
||||||
|
Copyright (C) 2017 The R Foundation for Statistical Computing
|
||||||
|
Platform: arm-unknown-linux-gnueabihf (32-bit)
|
||||||
|
|
||||||
|
R is free software and comes with ABSOLUTELY NO WARRANTY.
|
||||||
|
You are welcome to redistribute it under the terms of the
|
||||||
|
GNU General Public License versions 2 or 3.
|
||||||
|
For more information about these matters see
|
||||||
|
[http://www.gnu.org/licenses/](http://www.gnu.org/licenses/).
|
||||||
|
|
||||||
|
### 2.b. The Theory
|
||||||
|
|
||||||
|
We need to run a large number of relatively small jobs. So, what we will do is create a script that, when executed, runs the sbatch command to schedule the same job over and over again.
|
||||||
|
|
||||||
|
We will use a Slurm job array to do this. Basically, we give the scheduler a script to run, and tell it an array of numbers to run said script, it will run the script once for each number in the array, and the script can access its index during each job. This is how we will generate 50 random normal curves.
|
||||||
|
|
||||||
|
### 2.c. The R Program
|
||||||
|
|
||||||
|
Before we can schedule our program, we need to write a quick R script to generate the normal data-sets. So, we’ll create the file /clusterfs/normal/generate.R:
|
||||||
|
|
||||||
|
arg = commandArgs(TRUE)
|
||||||
|
|
||||||
|
samples = rep(NA, 100000)
|
||||||
|
for ( i in 1:100000 ){ samples[i] = mean(rexp(40, 0.2)) }
|
||||||
|
|
||||||
|
jpeg(paste('plots/', arg, '.jpg', sep=""))
|
||||||
|
hist(samples, main="", prob=T, color="darkred")
|
||||||
|
lines(density(samples), col="darkblue", lwd=3)
|
||||||
|
dev.off()
|
||||||
|
|
||||||
|
Okay, a lot to unpack here:
|
||||||
|
|
||||||
|
* arg = commandArgs(TRUE) grabs the command line arguments passed to R when this script is run. This will be the job ID number.
|
||||||
|
|
||||||
|
* samples = rep(NA,100000) replicates NA 100000 times. This effectively creates an empty array with 100000 slots.
|
||||||
|
|
||||||
|
* for( i in 1:100000 ){...} iterate over the numbers 1–100000. This will be used to generate our random values.
|
||||||
|
|
||||||
|
* samples[i] = mean(rexp(40, 0.2)) randomly generates 40 values following an exponential distribution with a range of 0.2. Then, find the mean of those values and store that mean in the samples array. This is our random dataset.
|
||||||
|
|
||||||
|
* jpeg(paste('plots/', arg, '.jpg', sep="")) open a new JPEG image to hold our graph. The name will be plots/XX.jpg where XX is the Job’s ID number.
|
||||||
|
|
||||||
|
* hist(samples, main="", prob=T, color="darkred") display a histogram of our randomly generated data
|
||||||
|
|
||||||
|
* lines(density(samples), col="darkblue", lwd=3) plot the line of the value densities over the histogram.
|
||||||
|
|
||||||
|
* dev.off() close the JPEG file
|
||||||
|
|
||||||
|
As a test, you can run this program once as a test:
|
||||||
|
|
||||||
|
$ mkdir plots
|
||||||
|
$ R --vanilla -f generate.R --args "plot1"
|
||||||
|
...R output...
|
||||||
|
|
||||||
|
Now, in the plots folder, we should have the file plot1.jpg that looks something like so:
|
||||||
|
|
||||||
|
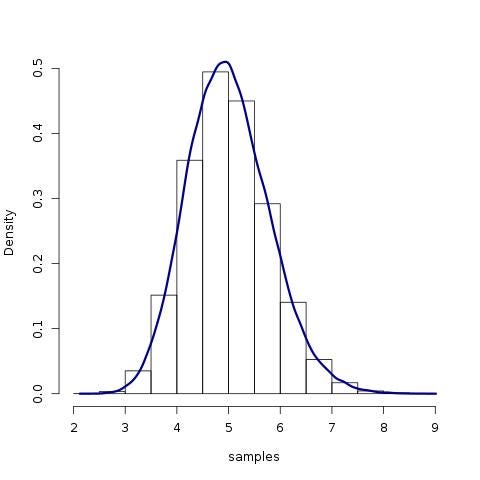
|
||||||
|
|
||||||
|
### 2.d. The Submission Script
|
||||||
|
|
||||||
|
Now that we have our R program, we will create a submission script to run our jobs. Create the file /clusterfs/normal/submit.sh:
|
||||||
|
|
||||||
|
#!/bin/bash
|
||||||
|
#SBATCH --nodes=1
|
||||||
|
#SBATCH --ntasks-per-node=1
|
||||||
|
#SBATCH --partition=<partition name>
|
||||||
|
|
||||||
|
cd $SLURM_SUBMIT_DIR
|
||||||
|
mkdir plots
|
||||||
|
|
||||||
|
R --vanilla -f generate.R --args "plot$SLURM_ARRAY_TASK_ID"
|
||||||
|
|
||||||
|
Here, we tell Slurm to run the job on 1 node, with 1 core on whatever partition you specified. Then, we change directories to the /clusterfs/normal folder where we will submit the job from.
|
||||||
|
|
||||||
|
Then we run the R program. This command looks very similar to the command we used to test the program but with one change. The name of the plot file is set to plot$SLURM_ARRAY_TASK_ID. This will name the image file after whatever index of the array we tell Slurm to run our job against. For example, when this job is run for the 23rd time, it will output the file: plots/plot23.jpg.
|
||||||
|
|
||||||
|
### 2.e. Run the Job!
|
||||||
|
|
||||||
|
We now have everything we need to run our job. From the login node, you can run the job like so:
|
||||||
|
|
||||||
|
$ cd /clusterfs/normal
|
||||||
|
$ sbatch --array=[1-50] submit.sh
|
||||||
|
Submitted batch job 910
|
||||||
|
|
||||||
|
Now, if we run squeue, we should see something like so:
|
||||||
|
|
||||||
|
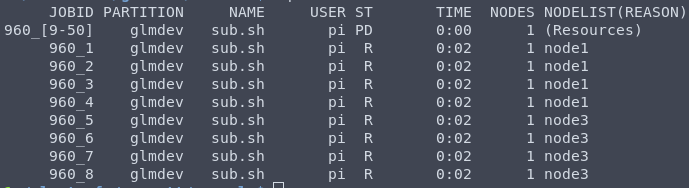
|
||||||
|
|
||||||
|
When the jobs complete, the /clusterfs/normal/plots folder should have 50 of our randomly generated histograms.
|
||||||
|
|
||||||
|
## Going Forward
|
||||||
|
|
||||||
|
In the next part in this series, we will look at installing software the better way, as well as setting up a message-passing-interface for multi-node programs.
|
||||||
|
|
||||||
|
[*Part III is available here.](https://medium.com/@glmdev/building-a-raspberry-pi-cluster-f5f2446702e8?source=---------4------------------)*
|
||||||
|
|
||||||
|
— Garrett
|
||||||
264
src/blog/posts/2019-04-19-flitter-getting-started.md
Normal file
264
src/blog/posts/2019-04-19-flitter-getting-started.md
Normal file
@@ -0,0 +1,264 @@
|
|||||||
|
---
|
||||||
|
layout: blog_post
|
||||||
|
title: Developing an App With Flitter - Getting Started
|
||||||
|
slug: Developing-an-App-With-Flitter-Getting-Started
|
||||||
|
date: 2019-04-19 00:01:00
|
||||||
|
tags: blog
|
||||||
|
permalink: /blog/2019/04/19/Developing-an-App-With-Flitter-Getting-Started/
|
||||||
|
blogtags:
|
||||||
|
- flitter
|
||||||
|
- webdev
|
||||||
|
- tutorial
|
||||||
|
---
|
||||||
|
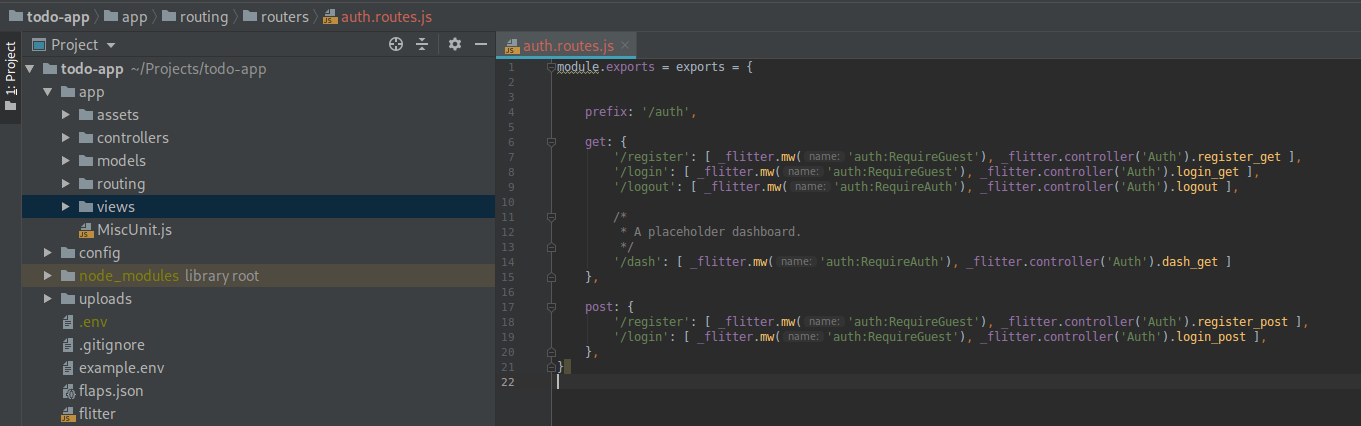
|
||||||
|
|
||||||
|
Flitter is my take on a Javascript web-app framework based on Express. If you haven’t read it, I recommend perusing my introduction [here](https://medium.com/@glmdev/flitter-framework-cohesive-express-js-36776766ad37) to see what it’s all about. This series of posts will look at creating a basic to-do web-app using Flitter. We’ll cover everything from getting set up to using Flitter, to debugging and running your app in production.
|
||||||
|
|
||||||
|
## What are we building?
|
||||||
|
|
||||||
|
The meat-and-potatoes of our app isn’t *that* important to the purpose of this tutorial, so we’re going to do something simple. We’re going to build a simple to-do application that allows users to sign in to a web panel, create and store tasks with notes and file attachments. We’ll also allow them to generate public links to share their tasks.
|
||||||
|
|
||||||
|
We’ll use [Bootstrap](https://getbootstrap.com/) for our front-end framework. Any custom styles we need to add will be written in [Less](http://lesscss.org/). Of course, since Flitter uses the Pug view engine, we’ll be using that too.
|
||||||
|
|
||||||
|
Let’s dive in.
|
||||||
|
|
||||||
|
## 1. Getting Set Up
|
||||||
|
|
||||||
|
### 1.1 — Prerequisites
|
||||||
|
|
||||||
|
Flitter has a few fairly straightforward system requirements. The installation of each of these on your particular system is beyond the scope of this document, but I’ll link to the install pages for them here:
|
||||||
|
|
||||||
|
* Node.js 10.x or higher — [https://nodejs.org/en/](https://nodejs.org/en/)
|
||||||
|
|
||||||
|
* Yarn package manager — [https://yarnpkg.com/en/docs/install](https://yarnpkg.com/en/docs/install)
|
||||||
|
|
||||||
|
* MongoDB server (community edition) — [https://www.mongodb.com/download-center/community](https://www.mongodb.com/download-center/community)
|
||||||
|
|
||||||
|
Although it’s not required, it’s also very helpful to have [Git](https://git-scm.com/downloads) installed.
|
||||||
|
|
||||||
|
### 1.2 — Grab a copy of Flitter.
|
||||||
|
|
||||||
|
I try my best to keep the master branch of the [main Flitter repo](https://code.garrettmills.dev/flitter/flitter) with the current, working version of Flitter. You can download a ZIP-file of the framework from the main repo link, or you can grab a copy using Git:
|
||||||
|
|
||||||
|
$ git clone [https://git.glmdev.tech/flitter/flitter](https://git.glmdev.tech/flitter/flitter) todo-app
|
||||||
|
|
||||||
|
This will copy the base framework files to a directory called todo-app/. Now, we need to install the Node.js packages required to run Flitter:
|
||||||
|
|
||||||
|
$ cd todo-app/
|
||||||
|
$ yarn install
|
||||||
|
|
||||||
|
Yarn will then install the packages required by Flitter. Because I use Yarn when I develop Flitter, it includes a yarn.lock file that is known good. This means that Yarn will install the exact versions I was using when Flitter worked.
|
||||||
|
|
||||||
|
### 1.3 — Configure the Environment
|
||||||
|
|
||||||
|
Flitter uses environment-specific configuration files for things like database credentials and app secrets. We’ll create a .env file with the configuration for our development environment:
|
||||||
|
|
||||||
|
SERVER_PORT=8000
|
||||||
|
LOGGING_LEVEL=1
|
||||||
|
|
||||||
|
DATABASE_HOST=127.0.0.1
|
||||||
|
DATABASE_PORT=27017
|
||||||
|
DATABASE_NAME=flitter
|
||||||
|
DATABASE_AUTH=true
|
||||||
|
DATABASE_USER=flitter
|
||||||
|
DATABASE_PASS=flitter
|
||||||
|
|
||||||
|
SECRET=changemetosomethingrandom
|
||||||
|
ENVIRONMENT=development
|
||||||
|
|
||||||
|
Be sure to edit the database credentials to match your setup. If your development server doesn’t require a login, you can set DATABASE_AUTH=false to disable authentication. Once you modify the configuration values, we’ll check if Flitter can start successfully:
|
||||||
|
|
||||||
|
$ ./flitter test
|
||||||
|
Flitter launched successfully. That doesn't mean that all of your app logic works, just that the framework backend initialized properly.
|
||||||
|
|
||||||
|
## 2. Create the User Auth
|
||||||
|
|
||||||
|
We want users to be able to register with/sign-in to our application, so we need to create a basic user-authentication portal. Sounds daunting, right? Well, Flitter makes it easy. Flitter has a built in package called [flitter-auth](https://flitter.garrettmills.dev/tutorial-flitter-auth.html) that provides a complete user-portal system out of the box. All we need to do is deploy the files:
|
||||||
|
|
||||||
|
$ ./flitter deploy auth
|
||||||
|
> A deployment in Flitter is a non-reversible setup script provided by a package. Various Flitter packages use the deploy command to set up functionality for the first time.
|
||||||
|
|
||||||
|
If you look in the app/ directory and its sub-directories, you’ll notice several new files related to user authentication. These were created by flitter-auth when you ran the deploy command.
|
||||||
|
|
||||||
|
### 2.1 — Test it out!
|
||||||
|
|
||||||
|
We can now try out the auth portal by launching Flitter and using it. To start Flitter’s HTTP server, run the following command:
|
||||||
|
|
||||||
|
$ ./flitter up
|
||||||
|
Flitter running on port 8000! Press ^C to exit cleanly.
|
||||||
|
|
||||||
|
*The default Flitter registration page.*
|
||||||
|
|
||||||
|
Now, you can navigate to localhost:8000/auth/register and you should be greeted with the default Flitter registration page.
|
||||||
|
|
||||||
|
To test it out, create a user. You should be redirected to a very simple dashboard. Then, you can log out using the provided button.
|
||||||
|
|
||||||
|
To test the sign-in functionality, navigate to: localhost:8000/auth/login and you should be able to get back to the dash with the user credentials you just created.
|
||||||
|
|
||||||
|
Et voilà! We have a fully functional user portal. Flitter makes the code for this portal available in the app-space, so we can (and will) modify it later to suit our app better.
|
||||||
|
|
||||||
|
## 3. First Looks
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Now that we have a very basic app up and running, let’s take a moment to explore the code we just deployed. We’re going to look at the code provided by the flitter-auth package and use it to get an idea of how Flitter works.
|
||||||
|
|
||||||
|
### 3.1 — Routing
|
||||||
|
|
||||||
|
Flitter is an [MVC framework](https://www.tutorialspoint.com/mvc_framework/mvc_framework_introduction.htm). This means that routes are defined in their own separate files. For example, let’s open app/routing/routers/auth.routes.js. There are a lot of comments in there, but if we condense it down to just the code, it looks something like this:
|
||||||
|
|
||||||
|
module.exports = exports = {
|
||||||
|
prefix: '/auth',
|
||||||
|
|
||||||
|
get: {
|
||||||
|
'/register': [ _flitter.mw('auth:RequireGuest'),
|
||||||
|
_flitter.controller('Auth').register_get ],
|
||||||
|
'/login': [ _flitter.mw('auth:RequireGuest'),
|
||||||
|
_flitter.controller('Auth').login_get ],
|
||||||
|
'/logout': [ _flitter.mw('auth:RequireAuth'),
|
||||||
|
_flitter.controller('Auth').logout ],
|
||||||
|
|
||||||
|
'/dash': [ _flitter.mw('auth:RequireAuth'),
|
||||||
|
_flitter.controller('Auth').dash_get ]
|
||||||
|
},
|
||||||
|
|
||||||
|
post: {
|
||||||
|
'/register': [ _flitter.mw('auth:RequireGuest'),
|
||||||
|
_flitter.controller('Auth').register_post ],
|
||||||
|
'/login': [ _flitter.mw('auth:RequireGuest'),
|
||||||
|
_flitter.controller('Auth').login_post ],
|
||||||
|
},
|
||||||
|
}
|
||||||
|
|
||||||
|
In Flitter, there is no code for grouping routes. Rather, routes that should be grouped together are placed in the same file. So, this file is used for all the routes relevant to user authentication. This file exports an object describing a set of routes.
|
||||||
|
|
||||||
|
First, we have the prefix. This is pretty straightforward; it’s a prefix applied to all routes in the file. Here, it’s /auth, so the /register route would be accessed at /auth/register.
|
||||||
|
|
||||||
|
Next we have the get object. This contains all routes for requests with the GET method. Likewise, there is a corresponding post object.
|
||||||
|
|
||||||
|
Both of these two objects contain a number of route definitions. Let’s look at the /register route in the post object. The key is /register which is what Flitter uses as the route — so this route would be accessed by sending a POST request to /auth/register. What follows is an array of functions.
|
||||||
|
|
||||||
|
The functions in this array are applied one at a time — in order — as handlers for the route. For the /register POST route, there are two handlers specified. The first is _flitter.mw('auth:RequireGuest'). This applies the auth:RequireGuest middleware to the route (more on that later). _flitter.mw() is a global function for retrieving middleware handlers by name.
|
||||||
|
|
||||||
|
The second handler is _flitter.controller('Auth').register_post. This applies the register_post method on the Auth controller (more on that later as well). Again, _flitter.controller() is a global function for retrieving controllers by name.
|
||||||
|
|
||||||
|
### 3.2 — Middleware
|
||||||
|
|
||||||
|
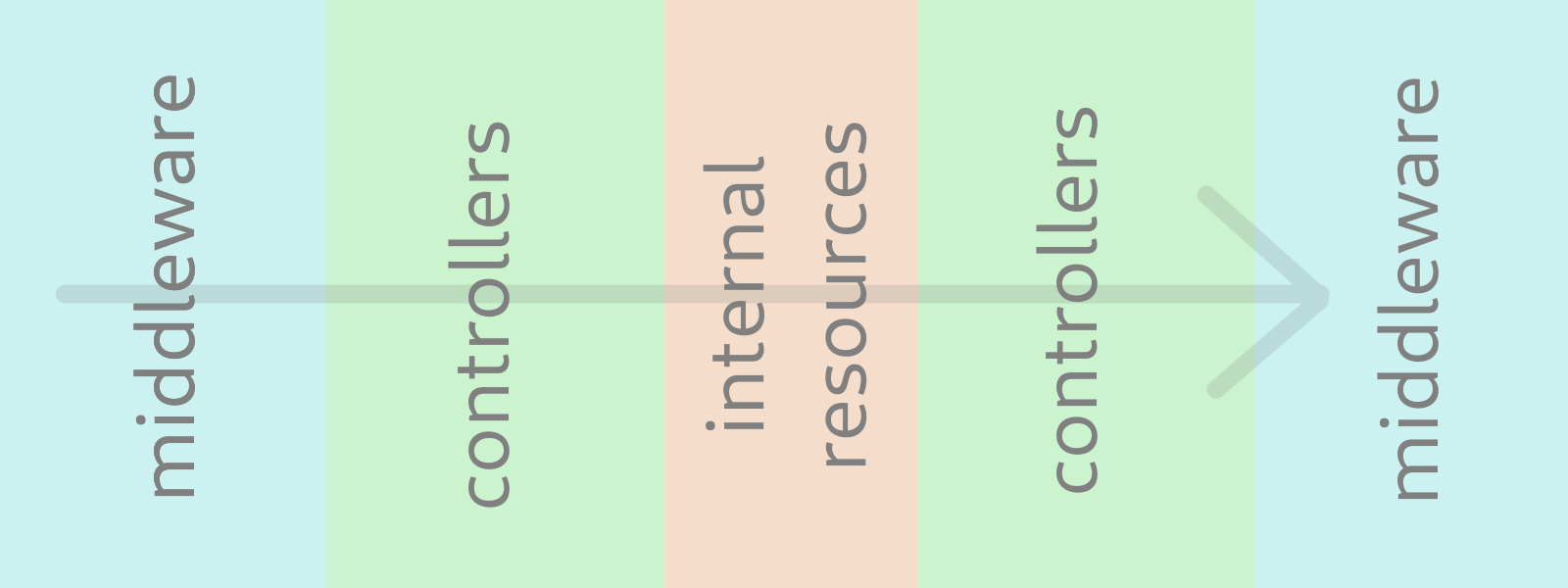****figure 3.2a:*** A simplified diagram of an MVC request/response flow.*
|
||||||
|
|
||||||
|
In an MVC framework, middleware is any code that runs between the application logic and the user. That means that, when a request comes in, the middleware is applied, then the request is handled by the controllers, and a response is sent. Before it reaches the user, more middleware may be applied.
|
||||||
|
|
||||||
|
In Flitter, each middleware resides in its own file in the app/routing/middleware/ directory. Let’s look at an example. Open the file app/routing/middleware/auth/RequireGuest.middleware.js. If we strip away the comments, we should see something like this:
|
||||||
|
|
||||||
|
class RequireGuest {*
|
||||||
|
*test(req, res, next){
|
||||||
|
if ( req.session && req.session.auth &&
|
||||||
|
(req.session.auth.authenticated === true ||
|
||||||
|
req.session.auth.user) ){
|
||||||
|
|
||||||
|
return _flitter.view(res, 'errors/requires_guest')
|
||||||
|
}
|
||||||
|
|
||||||
|
next()
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
module.exports = RequireGuest
|
||||||
|
|
||||||
|
This is a middleware provided by flitter-auth that checks if a user is logged in. If there is an authenticated user, stop the request and display an error page. Otherwise, let it continue through. This middleware is applied to routes like the login and registration pages — pages you don’t want users to be able to access if they have already signed in.
|
||||||
|
|
||||||
|
Flitter middleware definitions are pretty straight-forward. Each file contains and exports a class. This class has a function, test() that is called when the middleware is applied. It is passed the request, response, and next() function.
|
||||||
|
|
||||||
|
Here, if an authenticated user exists in the session, the middleware calls _flitter.view() to display the errors/requires_guest view (more on that later). This tells the user they’ve tried to access something they’re not allowed to. However, if there *isn’t* an authenticated user, it calls the next() function, which allows Express to continue processing the request normally.
|
||||||
|
|
||||||
|
In Flitter, middleware are assigned names based on their file name. For example, the middleware above exists in the file app/routing/middleware/auth/RequireGuest.middleware.js. When it is loaded by Flitter, it is assigned the name auth:RequireGuest.
|
||||||
|
|
||||||
|
You can use these names to apply middleware to routes. This is done via the global _flitter.mw() function. Simply pass the function the name of the middleware you want to apply (see *3.1* for example): _flitter.mw('auth:RequireGuest').
|
||||||
|
|
||||||
|
### 3.3 — Controllers
|
||||||
|
|
||||||
|
Controllers are the core of your application. They contain the majority of the logic your application provides, and they are the ultimate handlers of most routes.
|
||||||
|
|
||||||
|
In Flitter, controllers are located in the app/controllers/ directory. Let’s look at app/controllers/Auth.controller.js as an example. I’m going to strip out the comments and just focus on one method in the controller, dash_get():
|
||||||
|
|
||||||
|
const validator = require('validator')
|
||||||
|
const bcrypt = require('bcrypt')
|
||||||
|
const uuid = require('uuid/v4')
|
||||||
|
*
|
||||||
|
*class Auth {
|
||||||
|
|
||||||
|
// ... other methods omitted ...
|
||||||
|
|
||||||
|
dash_get(req, res, handle_error){
|
||||||
|
return _flitter.view(res, 'auth/dash',
|
||||||
|
{ user: req.session.auth.user })
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
module.exports = Auth
|
||||||
|
|
||||||
|
Each controller is defined in a file. The file exports a class. The methods on this class should define the logic for how to handle various routes. It’s okay to have methods on a controller that *don’t* handle routes — that is, they are helper functions for other controller methods — but the primary function of a controller is to handle requests.
|
||||||
|
|
||||||
|
Let’s look at the dash_get() method. This method is passed 3 arguments: the Express request, the Express response, and an error handler. It’s not used here, but when you are writing logic in Flitter controllers, you can gracefully handle errors by passing instances of the JavaScript Error class to the handle_error method.
|
||||||
|
|
||||||
|
dash_get() is the method responsible for serving the dashboard to authenticated users. It is called if an authenticated user navigates to the /dash route. The actual logic is pretty simple. dash_get() displays the auth/dash view and passes it the user from the session. (More on views later.)
|
||||||
|
|
||||||
|
Controller methods should be used in route definitions as the main handlers for our app’s routes. Each controller is assigned a name based on its file name. So, app/controllers/Auth.controller.js is called Auth. Instances of these controllers can be accessed with the global _flitter.controller() helper function.
|
||||||
|
|
||||||
|
See *3.1* for examples of how to reference controller methods in route definitions, but for dash_get() it’s as easy as _flitter.controller('Auth').dash_get.
|
||||||
|
|
||||||
|
### 3.4 — Database Models
|
||||||
|
|
||||||
|
Data in MVC frameworks are stored in models. A model is simply a defined structure for some type of record that is kept in a database. In Flitter, models are stored in the app/models/ directory. Let’s look at the app/models/User.model.js model provided by flitter-auth:
|
||||||
|
|
||||||
|
module.exports = exports = {
|
||||||
|
username: String,
|
||||||
|
password: String,
|
||||||
|
data: String,
|
||||||
|
uuid: String,
|
||||||
|
}
|
||||||
|
|
||||||
|
Model files in Flitter export an object that describes the structure of the model. The keys of the object are the names of the fields in the model, and the values are the data type of that field. Flitter uses Mongoose to provide ORM, so you can find more info [here at the Mongoose docs.](https://mongoosejs.com/docs/guide.html) The User model above has 4 fields, each of which contains a string.
|
||||||
|
|
||||||
|
Models in Flitter can be accessed using the global _flitter.model() helper function. Models in Flitter are assigned names based on their file name. For example, the model app/models/upload/File.model.js can be accessed with _flitter.model('upload:File'). The _flitter.model() method returns an instance of [Mongoose/Model](https://mongoosejs.com/docs/models.html).
|
||||||
|
|
||||||
|
### 3.5 — Static Assets & Views
|
||||||
|
|
||||||
|
***3.5.1 — Static Assets
|
||||||
|
***Flitter makes files placed in the app/assets/ directory directly available as static files on the assets/ route. For example, the file app/assets/flitter.png can be accessed by navigating to [http://flitter.url/assets/flitter.png.](http://flitter.url/assets/flitter.png.)
|
||||||
|
|
||||||
|
Flitter also serves a favicon by default using the [express-favicon](https://www.npmjs.com/package/express-favicon) package. The location of the favicon file is app/assets/favicon.ico. Flitter *requires* that you provide a favicon file at this path. We provide a default one for you.
|
||||||
|
|
||||||
|
***3.5.2 — Views***
|
||||||
|
A view is just some page that is served to the client. Flitter uses the [Pug view engine](https://pugjs.org/api/getting-started.html). Views in Flitter are placed in the app/views/ directory. Again, views are assigned names based on their file name. So, the file app/views/auth/dash.pug can be referenced with the name auth:dash.
|
||||||
|
|
||||||
|
To serve a view in Flitter, you can use the [global helper method](https://flitter.garrettmills.dev/module-libflitter_views_ViewEngineUnit-ViewEngineUnit.html#view): _flitter.view(). For example, let’s go back to the controller method referenced above:
|
||||||
|
|
||||||
|
const validator = require('validator')
|
||||||
|
const bcrypt = require('bcrypt')
|
||||||
|
const uuid = require('uuid/v4')
|
||||||
|
*
|
||||||
|
*class Auth {
|
||||||
|
|
||||||
|
// ... other methods omitted ...
|
||||||
|
|
||||||
|
dash_get(req, res, handle_error){
|
||||||
|
return _flitter.view(res, 'auth/dash',
|
||||||
|
{ user: req.session.auth.user })
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
module.exports = Auth
|
||||||
|
|
||||||
|
The call to _flitter.view() here serves the view file app/views/auth/dash.pug. The object passed to the helper method is bound to the view such that its keys can be accessed directly as variables in the view. That is, within the view, the variable user would be defined.
|
||||||
|
|
||||||
|
## Part I Conclusion
|
||||||
|
|
||||||
|
Hopefully this has been a helpful introduction to my Flitter framework. We have a functional app with user authentication abilities, and we didn’t have to write a single line of code. In Part II of this series, we’ll start writing the code specific to our to-do app, and we’ll dive deeper into the practical use of Flitter.
|
||||||
|
|
||||||
|
If you’re impatient and want to get started right away, you can find more information about how to use Flitter in [the documentation.](https://flitter.garrettmills.dev/)
|
||||||
|
|
||||||
|
As always, let me know if you have questions about any part of this article, and I’ll try my best to help! Be sure to reference the header number of the part you have questions about.
|
||||||
|
|
||||||
|
This is the first part in a multi-part series that explores how to develop for Flitter, my Express-based Javascript web app framework. You can find more information about Flitter [here.](https://flitter.garrettmills.dev/)
|
||||||
|
|
||||||
310
src/blog/posts/2019-04-29-rpi-part-3.md
Normal file
310
src/blog/posts/2019-04-29-rpi-part-3.md
Normal file
@@ -0,0 +1,310 @@
|
|||||||
|
---
|
||||||
|
layout: blog_post
|
||||||
|
title: Building a Raspberry Pi Cluster - Part III
|
||||||
|
slug: Building-a-Raspberry-Pi-Cluster-Part-III
|
||||||
|
date: 2019-04-29 01:00:00
|
||||||
|
tags: blog
|
||||||
|
permalink: /blog/2019/04/29/Building-a-Raspberry-Pi-Cluster-Part-III/
|
||||||
|
blogtags:
|
||||||
|
- raspberry pi
|
||||||
|
- tutorial
|
||||||
|
- hosting
|
||||||
|
---
|
||||||
|
|
||||||
|
# Part III —OpenMPI, Python, and Parallel Jobs
|
||||||
|
|
||||||
|
*This is Part III in my series on building a small-scale HPC cluster. Be sure to check out [Part I](https://medium.com/@glmdev/building-a-raspberry-pi-cluster-784f0df9afbd) and [Part II](https://medium.com/@glmdev/building-a-raspberry-pi-cluster-aaa8d1f3d2ca).*
|
||||||
|
|
||||||
|
In the first two parts, we set up our Pi cluster with the SLURM scheduler and ran some test jobs using R. We also looked at how to schedule many small jobs using SLURM. We also installed software the easy way by running the package manager install command on all of the nodes simultaneously.
|
||||||
|
|
||||||
|
In this part, we’re going to set up OpenMPI, install Python the “better” way, and take a look at running some jobs in parallel to make use of the multiple cluster nodes.
|
||||||
|
|
||||||
|
## Part 1: Installing OpenMPI
|
||||||
|
|
||||||
|
](https://cdn-images-1.medium.com/max/2000/0*jOJ8c4u_V4hsQpaV.png)*[https://www.open-mpi.org/](https://www.open-mpi.org/)*
|
||||||
|
|
||||||
|
OpenMPI is an open-source implementation of the Message Passing Interface concept. An MPI is a software that connects processes running across multiple computers and allows them to communicate as they run. This is what allows a single script to run a job spread across multiple cluster nodes.
|
||||||
|
|
||||||
|
We’re going to install OpenMPI the easy way, as we did with R. While it is possible to install it using the “better” way (spoiler alert: compile from source), it’s more difficult to get it to play nicely with SLURM.
|
||||||
|
|
||||||
|
We want it to play nicely because SLURM will auto-configure the environment when a job is running so that OpenMPI has access to all the resources SLURM has allocated the job. This saves us a *lot *of headache and setup for each job.
|
||||||
|
|
||||||
|
### 1.1 — Install OpenMPI
|
||||||
|
|
||||||
|
To install OpenMPI, SSH into the head node of the cluster, and use srun to install OpenMPI on each of the nodes:
|
||||||
|
|
||||||
|
$ sudo su -
|
||||||
|
# srun --nodes=3 apt install openmpi-bin openmpi-common libopenmpi3 libopenmpi-dev -y
|
||||||
|
|
||||||
|
(Obviously, replace --nodes=3 with however many nodes are in your cluster.)
|
||||||
|
|
||||||
|
### 1.2 — Test it out!
|
||||||
|
|
||||||
|
Believe it or not, that’s all it took to get OpenMPI up and running on our cluster. Now, we’re going to create a very basic hello-world program to test it out.
|
||||||
|
|
||||||
|
***1.2.1 — Create a program.
|
||||||
|
***We’re going to create a C program that creates an MPI cluster with the resources SLURM allocates to our job. Then, it’s going to call a simple print command on each process.
|
||||||
|
|
||||||
|
Create the file /clusterfs/hello_mpi.c with the following contents:
|
||||||
|
|
||||||
|
#include <stdio.h>
|
||||||
|
#include <mpi.h>
|
||||||
|
|
||||||
|
int main(int argc, char** argv){
|
||||||
|
int node;
|
||||||
|
MPI_Init(&argc, &argv);
|
||||||
|
MPI_Comm_rank(MPI_COMM_WORLD, &node);
|
||||||
|
|
||||||
|
printf("Hello World from Node %d!\n", node);
|
||||||
|
|
||||||
|
MPI_Finalize();
|
||||||
|
}
|
||||||
|
|
||||||
|
Here, we include the mpi.h library provided by OpenMPI. Then, in the main function, we initialize the MPI cluster, get the number of the node that the current process will be running on, print a message, and close the MPI cluster.
|
||||||
|
|
||||||
|
***1.2.2 — Compile the program.***
|
||||||
|
We need to compile our C program to run it on the cluster. However, unlike with a normal C program, we won’t just use gcc like you might expect. Instead, OpenMPI provides a compiler that will automatically link the MPI libraries.
|
||||||
|
|
||||||
|
Because we need to use the compiler provided by OpenMPI, we’re going to grab a shell instance from one of the nodes:
|
||||||
|
|
||||||
|
**login1$** srun --pty bash
|
||||||
|
**node1$** cd /clusterfs
|
||||||
|
**node1$** mpicc hello_mpi.c
|
||||||
|
**node1$** ls
|
||||||
|
**a.out*** hello_mpi.c
|
||||||
|
**node1$** exit
|
||||||
|
|
||||||
|
The a.out file is the compiled program that will be run by the cluster.
|
||||||
|
|
||||||
|
***1.2.3 — Create a submission script.
|
||||||
|
***Now, we will create the submission script that runs our program on the cluster. Create the file /clusterfs/sub_mpi.sh:
|
||||||
|
|
||||||
|
#!/bin/bash
|
||||||
|
|
||||||
|
cd $SLURM_SUBMIT_DIR
|
||||||
|
|
||||||
|
# Print the node that starts the process
|
||||||
|
echo "Master node: $(hostname)"
|
||||||
|
|
||||||
|
# Run our program using OpenMPI.
|
||||||
|
# OpenMPI will automatically discover resources from SLURM.
|
||||||
|
mpirun a.out
|
||||||
|
|
||||||
|
***1.2.4 — Run the job.***
|
||||||
|
Run the job by submitting it to SLURM and requesting a couple of nodes and processes:
|
||||||
|
|
||||||
|
$ cd /clusterfs
|
||||||
|
$ sbatch --nodes=3 --ntasks-per-node=2 sub_mpi.sh
|
||||||
|
Submitted batch job 1211
|
||||||
|
|
||||||
|
This tells SLURM to get 3 nodes and 2 cores on each of those nodes. If we have everything working properly, this should create an MPI cluster with 6 nodes. Assuming this works, we should see some output in our slurm-XXX.out file:
|
||||||
|
|
||||||
|
Master node: node1
|
||||||
|
Hello World from Node 0!
|
||||||
|
Hello World from Node 1!
|
||||||
|
Hello World from Node 2!
|
||||||
|
Hello World from Node 3!
|
||||||
|
Hello World from Node 4!
|
||||||
|
Hello World from Node 5!
|
||||||
|
|
||||||
|
## Part 2: Installing Python (the “better” way)
|
||||||
|
|
||||||
|
Okay, so for a while now, I’ve been alluding to a “better” way to install cluster software. Let’s talk about that. Up until now, when we’ve installed software on the cluster, we’ve essentially did it individually on each node. While this works, it quickly becomes inefficient. Instead of duplicating effort trying to make sure the same software versions and environment is available on every single node, wouldn’t it be great if we could install software centrally for all nodes?
|
||||||
|
|
||||||
|
Well, luckily a new feature in the modern Linux operating system allows us to do just that: compile from source! ([/s](https://www.reddit.com/r/OutOfTheLoop/comments/1zo2l4/what_does_s_mean/)) Rather than install software through the individual package managers of each node, we can compile it from source and configure it to be installed to a directory in the shared storage. Because the architecture of our nodes is identical, they can all run the software from shared storage.
|
||||||
|
|
||||||
|
This is useful because it means that we only have to maintain a single installation of a piece of software and its configuration. On the downside, compiling from source is a *lot* slower than installing pre-built packages. It’s also more difficult to update. Trade-offs.
|
||||||
|
|
||||||
|
In this section, we’re going to install Python3 from source and use it across our different nodes.
|
||||||
|
|
||||||
|
### 2.0 — Prerequisites
|
||||||
|
|
||||||
|
In order for the Python build to complete successfully, we need to make sure that we have the libraries it requires installed on one of the nodes. We’ll only install these on one node and we’ll make sure to only build Python on that node:
|
||||||
|
|
||||||
|
$ srun --nodelist=node1 bash
|
||||||
|
**node1**$ sudo apt install -y build-essential python-dev python-setuptools python-pip python-smbus libncursesw5-dev libgdbm-dev libc6-dev zlib1g-dev libsqlite3-dev tk-dev libssl-dev openssl libffi-dev
|
||||||
|
|
||||||
|
Hooo boy. That’s a fair number of dependencies. While you can technically build Python itself without running this step, we want to be able to access Pip and a number of other extra tools provided with Python. These tools will only compile if their dependencies are available.
|
||||||
|
|
||||||
|
Note that these dependencies don’t need to be present to *use* our new Python install, just to compile it.
|
||||||
|
|
||||||
|
### 2.1 — Download Python
|
||||||
|
|
||||||
|
Let’s grab a copy of the Python source files so we can build them. We’re going to create a build directory in shared storage and extract the files there. You can find links to the latest version of Python [here](https://www.python.org/downloads/source/), but I’ll be installing 3.7. Note that we want the “Gzipped source tarball” file:
|
||||||
|
|
||||||
|
$ cd /clusterfs && mkdir build && cd build
|
||||||
|
$ wget [https://www.python.org/ftp/python/3.7.3/Python-3.7.3.tgz](https://www.python.org/ftp/python/3.7.3/Python-3.7.3.tgz)
|
||||||
|
$ tar xvzf Python-3.7.3.tgz
|
||||||
|
... tar output ...
|
||||||
|
$ cd Python-3.7.3
|
||||||
|
|
||||||
|
At this point, we should have the Python source extracted to the directory /clusterfs/build/Python-3.7.3.
|
||||||
|
|
||||||
|
### 2.2 — Configure Python
|
||||||
|
|
||||||
|
*For those of you who have installed software from source before, what follows is pretty much a standard configure;make;make install, but we’re going to change the prefix directory.*
|
||||||
|
|
||||||
|
The first step in building Python is configuring the build to our environment. This is done with the ./configure command. Running this by itself will configure Python to install to the default directory. However, we don’t want this, so we’re going to pass it a custom flag. This will tell Python to install to a folder on the shared storage. Buckle up, because this may take a while:
|
||||||
|
|
||||||
|
$ mkdir /clusterfs/usr # directory Python will install to
|
||||||
|
$ cd /clusterfs/build/Python-3.7.3
|
||||||
|
$ srun --nodelist=node1 bash # configure will be run on node1
|
||||||
|
node1$ ./configure \
|
||||||
|
--enable-optimizations \
|
||||||
|
--prefix=/clusterfs/usr \
|
||||||
|
--with-ensurepip=install
|
||||||
|
...configure output...
|
||||||
|
|
||||||
|
### 2.3 — Build Python
|
||||||
|
|
||||||
|
Now that we’ve configured Python to our environment, we need to actually compile the binaries and get them ready to run. We will do this with the make command. However, because Python is a fairly large program, and the RPi isn’t exactly the biggest workhorse in the world, it will take a little while to compile.
|
||||||
|
|
||||||
|
So, rather than leave a terminal open the whole time Python compiles, we’re going to use our shiny new scheduler! We can submit a job that will compile it and we can just wait for the job to finish. To do this, create a submission script in the Python source folder:
|
||||||
|
|
||||||
|
#!/bin/bash
|
||||||
|
#SBATCH --nodes=1
|
||||||
|
#SBATCH --ntasks-per-node=4
|
||||||
|
#SBATCH --nodelist=node1
|
||||||
|
|
||||||
|
cd $SLURM_SUBMIT_DIR
|
||||||
|
|
||||||
|
make -j4
|
||||||
|
|
||||||
|
This script will request 4cores on node1 and will run the make command on those cores. Make is the software tool that will compile Python for us. Now, just submit the job from the login node:
|
||||||
|
|
||||||
|
$ cd /clusterfs/build/Python-3.7.3
|
||||||
|
$ sbatch sub_build_python.sh
|
||||||
|
Submitted batch job 1212
|
||||||
|
|
||||||
|
Now, we just wait for the job to finish running. It took about an hour for me on an RPi 3B+. You can view its progress using the squeue command, and by looking in the SLURM output file:
|
||||||
|
|
||||||
|
$ tail -f slurm-1212.out # replace "1212" with the job ID
|
||||||
|
|
||||||
|
### 2.4 — Install Python
|
||||||
|
|
||||||
|
Lastly, we will install Python to the /clusterfs/usr directory we created. This will also take a while, though not as long as compiling. We can use the scheduler for this task. Create a submission script in the source directory:
|
||||||
|
|
||||||
|
#!/bin/bash
|
||||||
|
#SBATCH --nodes=1
|
||||||
|
#SBATCH --ntasks-per-node=1
|
||||||
|
#SBATCH --nodelist=node1
|
||||||
|
|
||||||
|
cd $SLURM_SUBMIT_DIR
|
||||||
|
|
||||||
|
make install
|
||||||
|
|
||||||
|
However, we don’t want just any old program to be able to modify or delete the Python install files. So, just like with any normal program, we’re going to install Python as root so it cannot be modified by normal users. To do this, we’ll submit the install job as a root user:
|
||||||
|
|
||||||
|
$ sudo su -
|
||||||
|
# cd /clusterfs/build/Python-3.7.3
|
||||||
|
# sbatch sub_install_python.sh
|
||||||
|
Submitted batch job 1213
|
||||||
|
|
||||||
|
Again, you can monitor the status of the job. When it completes, we should have a functional Python install!
|
||||||
|
|
||||||
|
### 2.5 — Test it out.
|
||||||
|
|
||||||
|
We should now be able to use our Python install from any of the nodes. As a basic first test, we can run a command on all of the nodes:
|
||||||
|
|
||||||
|
$ srun --nodes=3 /clusterfs/usr/bin/python3 -c "print('Hello')"
|
||||||
|
Hello
|
||||||
|
Hello
|
||||||
|
Hello
|
||||||
|
|
||||||
|
We should also have access to pip:
|
||||||
|
|
||||||
|
$ srun --nodes=1 /clusterfs/usr/bin/pip3 --version
|
||||||
|
pip 19.0.3 from /clusterfs/usr/lib/python3.7/site-packages/pip (python 3.7)
|
||||||
|
|
||||||
|
The exact same Python installation should now be accessible from all the nodes. This is useful because, if you want to use some library for a job, you can install it once on this install, and all the nodes can make use of it. It’s cleaner to maintain.
|
||||||
|
|
||||||
|
## Part 3: A Python MPI Hello-World
|
||||||
|
|
||||||
|
Finally, to test out our new OpenMPI and Python installations, we’re going to throw together a quick Python job that uses OpenMPI. To interface with OpenMPI in Python, we’re going to be using a fantastic library called [mpi4py](https://github.com/erdc/mpi4py/).
|
||||||
|
|
||||||
|
For our demo, we’re going to use one of the demo programs in the mpi4py repo. We’re going to calculate the value of pi (the number) in parallel.
|
||||||
|
|
||||||
|
### 3.0 — Prerequisites
|
||||||
|
|
||||||
|
Before we can write our script, we need to install a few libraries. Namely, we will install the mpi4py library, and numpy. [NumPy](https://www.numpy.org/) is a package that contains many useful structures and operations used for scientific computing in Python. We can install these libraries through pip, using a batch job. Create the file /clusterfs/calc-pi/sub_install_pip.sh:
|
||||||
|
|
||||||
|
#!/bin/bash
|
||||||
|
#SBATCH --nodes=1
|
||||||
|
#SBATCH --ntasks-per-node=1
|
||||||
|
|
||||||
|
/clusterfs/usr/bin/pip3 install numpy mpi4py
|
||||||
|
|
||||||
|
Then, submit the job. We have to do this as root because it will be modifying our Python install:
|
||||||
|
|
||||||
|
$ cd /clusterfs/calc-pi
|
||||||
|
$ sudo su
|
||||||
|
# sbatch sub_install_pip.sh
|
||||||
|
Submitted batch job 1214
|
||||||
|
|
||||||
|
Now, we just wait for the job to complete. When it does, we should be able to use the mpi4py and numpy libraries:
|
||||||
|
|
||||||
|
$ srun bash
|
||||||
|
node1$ /clusterfs/usr/bin/python3
|
||||||
|
Python 3.7.3 (default, Mar 27 2019, 13:41:07)
|
||||||
|
[GCC 8.3.1 20190223 (Red Hat 8.3.1-2)] on linux
|
||||||
|
Type "help", "copyright", "credits" or "license" for more information.
|
||||||
|
>>> import numpy
|
||||||
|
>>> from mpi4py import MPI
|
||||||
|
|
||||||
|
### 3.1 — Create the Python program.
|
||||||
|
|
||||||
|
As mentioned above, we’re going to use one of the demo programs provided in the [mpi4py repo](https://github.com/erdc/mpi4py/blob/master/demo/compute-pi/cpi-cco.py). However, because we’ll be running it through the scheduler, we need to modify it to not require any user input. Create the file /clusterfs/calc-pi/calculate.py:
|
||||||
|
|
||||||
|
<iframe src="https://medium.com/media/b166678ead25f2cbee5ea524ac4b5d22" frameborder=0></iframe>
|
||||||
|
|
||||||
|
This program will split the work of computing our approximation of pi out to however many processes we provide it. Then, it will print the computed value of pi, as well as the error from the stored value of pi.
|
||||||
|
|
||||||
|
### 3.2 — Create and submit the job.
|
||||||
|
|
||||||
|
We can run our job using the scheduler. We will request some number of cores from the cluster, and SLURM will pre-configure the MPI environment with those cores. Then, we just run our Python program using OpenMPI. Let’s create the submission file /clusterfs/calc-pi/sub_calc_pi.sh:
|
||||||
|
|
||||||
|
#!/bin/bash
|
||||||
|
#SBATCH --ntasks=6
|
||||||
|
|
||||||
|
cd $SLURM_SUBMIT_DIR
|
||||||
|
|
||||||
|
mpiexec -n 6 /clusterfs/usr/bin/python3 calculate.py
|
||||||
|
|
||||||
|
Here, we use the --ntasks flag. Where the --ntasks-per-node flag requests some number of cores for each node, the --ntasks flag requests a specific number of cores *total*. Because we are using MPI, we can have cores across machines. Therefore, we can just request the number of cores that we want. In this case, we ask for 6 cores.
|
||||||
|
|
||||||
|
To run the actual program, we use mpiexec and tell it we have 6 cores. We tell OpenMPI to execute our Python program using the version of Python we installed.
|
||||||
|
> Note that you can adjust the number of cores to be higher/lower as you want. Just make sure you change the mpiexec -n ## flag to match.
|
||||||
|
|
||||||
|
Finally, we can run the job:
|
||||||
|
|
||||||
|
$ cd /clusterfs/calc-pi
|
||||||
|
$ sbatch sub_calc_pi.sh
|
||||||
|
Submitted batch job 1215
|
||||||
|
|
||||||
|
### 3.3 — Success!
|
||||||
|
|
||||||
|
The calculation should only take a couple seconds on the cluster. When the job completes (remember — you can monitor it with squeue), we should see some output in the slurm-####.out file:
|
||||||
|
|
||||||
|
$ cd /clusterfs/calc-pi
|
||||||
|
$ cat slurm-1215.out
|
||||||
|
pi is approximately 3.1418009868930934, error is 0.0002083333033003
|
||||||
|
|
||||||
|
You can tweak the program to calculate a more accurate value of pi by increasing the number of intervals on which the calculation is run. Do this by modifying the calculate.py file:
|
||||||
|
|
||||||
|
if myrank == 0:
|
||||||
|
_n = 20 # change this number to control the intervals
|
||||||
|
n.fill(_n)
|
||||||
|
|
||||||
|
For example, here’s the calculation run on 500 intervals:
|
||||||
|
|
||||||
|
pi is approximately 3.1415929869231265, error is 0.0000003333333334
|
||||||
|
|
||||||
|
## Conclusion
|
||||||
|
|
||||||
|
We now have a basically complete cluster. We can run jobs using the SLURM scheduler; we discussed how to install software the lazy way and the better way; we installed OpenMPI; and we ran some example programs that use it.
|
||||||
|
|
||||||
|
Hopefully, your cluster is functional enough that you can add software and components to it to suit your projects. In the fourth and final installment of this series, we’ll discuss a few maintenance niceties that are more related to managing installed software and users than the actual functionality of the cluster.
|
||||||
|
|
||||||
|
Happy Computing!
|
||||||
|
|
||||||
|
—[ Garrett Mills](https://glmdev.tech/)
|
||||||
70
src/blog/posts/2019-11-15-new-platform.md
Normal file
70
src/blog/posts/2019-11-15-new-platform.md
Normal file
@@ -0,0 +1,70 @@
|
|||||||
|
---
|
||||||
|
layout: blog_post
|
||||||
|
tags: blog
|
||||||
|
title: A New Platform - My Relentless Pursuit of Privacy
|
||||||
|
slug: A-New-Platform
|
||||||
|
permalink: /blog/2019/11/15/A-New-Platform/
|
||||||
|
date: 2019-11-15 13:05:00
|
||||||
|
blogtags:
|
||||||
|
- hexo
|
||||||
|
- meta
|
||||||
|
- medium
|
||||||
|
---
|
||||||
|
|
||||||
|
I have decided to try out a new format for my blog. The site that this article was originally published on can be found at the new home of my blog, [here](https://garrettmills.dev/blog/). I thought I might take this opportunity to discuss the platform that runs this blog, as well as my motivation for moving the primary source away from Medium.
|
||||||
|
|
||||||
|
## Enter Hexo
|
||||||
|
For this site, I'm using a static blog generator called [Hexo](https://hexo.io/). Hexo has been around for a few years now, and is fairly mature. More importantly, it has a pretty solid user-base. I tried out several different self-hosted blogging platforms during this process, including (but not limited to):
|
||||||
|
* Postleaf - this one was my initial choice, but it has a much smaller community, and doesn't appear to be actively developed anymore.
|
||||||
|
* Ghost - Ghost is a powerful CMS platform with a massive commnunity. However, it has a much more corporate feel, and I'm not wild about running an app vs. a statically generated site. Additionally, it requires a login to their central service and has many features behind a paywall.
|
||||||
|
* Wordpress - I've used Wordpress in the past. While it works well as a holistic website solution for many people, I generally prefer something lighter that I can modify easily.
|
||||||
|
|
||||||
|
### Content
|
||||||
|
So, how does Hexo work? Well, it's pretty straightforward, actually. Pages, data, and posts are defined in markdown files in a source directory within the app's files. This means that the "CMS" in this case is my favorite text editor and Git.
|
||||||
|
|
||||||
|
### Themes
|
||||||
|
Various theme options can be installed by cloning them into the themes folder of the application. I settled on the Cactus theme for Hexo because it has rich plugin support, and appears to still be maintained. Plus, it was easy to adapt the existing dark theme to match the color scheme on my main website.
|
||||||
|
|
||||||
|
### Plugins
|
||||||
|
Because the Cactus theme supports a wide range of plugins, it was really simple for me to add the functionality to this site that I would expect from a semi-modern blog. For example, you can subscribe to this page with Atom/RSS, full-text search the posts using a statically-generated search index, and leave comments below courtesy of Disqus.
|
||||||
|
|
||||||
|
> Large technology companies like the ones that run the so-called free services that run our lives make their money by selling our data to advertisers.
|
||||||
|
|
||||||
|
## Okay, but why?
|
||||||
|
<img src="https://static.garrettmills.dev/assets/blog-images/medium_1.png" alt="My Medium view/read stats for October/November 2019">
|
||||||
|
<center><small>My Medium view/read stats for October/November 2019.</small></center>
|
||||||
|
|
||||||
|
Over the last couple years, I've written fewer articles and tutorials than I would have liked, but the ones I did write have done fairly well. I have a pretty consistent 25-30k views per month across several of my stories, including my multipart Raspberry Pi Cluster series. So why would I want to move away from Medium as my primary publishing source? Well to answer that question we need to look at a deeper trend.
|
||||||
|
|
||||||
|
### Technological Behemoths and the Internet ~~Consumer~~ Product
|
||||||
|
[Nearly one fifth](https://www.ibtimes.com/facebook-one-out-every-five-people-earth-have-active-account-1801240) of all humans on earth have a Facebook account. So, one might be tempted to say that Facebook has ~1.3 billion consumers. But, this is not the case. In fact, very few of those people are actually consumers of Facebook. Instead, they are the product. Massive technology companies like Facebook and Google stay in business because the users of their platforms are not the consumers, but instead are the product. Generating ever-more valuable data for analytics, clicks, shares, and the king of it all **advertising.**
|
||||||
|
|
||||||
|
Large technology companies like the ones that run the so-called free services that run our lives make their money by selling our data to advertisers. In turn, we are bombarded with increasingly strategic ads that try to steal our attention. This is troubling to me.
|
||||||
|
|
||||||
|
That, combined with the fact that I am deeply uncomfortable relying on sometimes ephemeral companies to provide me the services I need to use day-to-day. Especially if, in turn, the data I entrust to these services is being analyzed to sell me on AI-selected products.
|
||||||
|
|
||||||
|
### Public Cloud
|
||||||
|
So, over the last year and a half, I've embarked upon a journey to become less reliant on the likes of Google and Microsoft by transitioning services I traditionally relied upon to private instances hosted on a VPS.
|
||||||
|
|
||||||
|
I know that a VPS still implies a level of trust of my data with a corporate entity. However, the access that entity has to my data is severely limited. Besides, I'm a college student. Where am I supposed to put a rack of servers. Not that I wouldn't enjoy that...
|
||||||
|
|
||||||
|
So far, this effort has included, among other things:
|
||||||
|
* Replacing Google Contacts, Calendar, Drive with NextCloud equivalents
|
||||||
|
* Transitioning from Google Docs to LibreOffice on my laptop and a private OnlyOffice instance online
|
||||||
|
* Relocating my code from Github to my private [Gitea instance](https://code.garrettmills.dev/)
|
||||||
|
* Swapping Google for [DuckDuckGo](https://duckduckgo.com), a privacy-first search engine
|
||||||
|
* Moving my personal site from Github Pages to a VPS
|
||||||
|
|
||||||
|
### A Medium Corporation
|
||||||
|
Medium is a very large, very popular, very corporate blogging platform that makes a portion of its revenue from a user-subscription model. This means that Medium is much less dependent on privacy-hostile streams like advertising. However, having Medium as the sole home of my content is problematic because at some point, I no longer control that content. If Medium were to decide tomorrow that I had violated their terms of service, they could remove all of my content irrevocably, and because they're a private entity they have every right to do so.
|
||||||
|
|
||||||
|
So, in keeping with my theme for the year, I wanted to find a more data-safe medium (heh) for my content. Hence, this site was born.
|
||||||
|
|
||||||
|
## What does this mean?
|
||||||
|
Going forward, I'd like this site to be the primary home for my content. I'd love to answer questions and comments on that content here, and interact with users directly. However, I also want to enable as wide a variety of people to discover this work as possible. So, my Medium blog will become a mirror of the posts on this site. That is, any content available here will also be available on Medium.
|
||||||
|
|
||||||
|
I'm excited to get back in the process of creating write-ups for my projects. It helps me document my work and has given me some really awesome opportunities to interact with people who enjoy these projects as well. So, be sure to check back in the future.
|
||||||
|
|
||||||
|
Garrett
|
||||||
|
|
||||||
|
_P.S. - Existing posts from my Medium blog will be made available here as I have time to transition them._
|
||||||
275
src/blog/posts/2019-11-16-pure-js-di.md
Normal file
275
src/blog/posts/2019-11-16-pure-js-di.md
Normal file
@@ -0,0 +1,275 @@
|
|||||||
|
---
|
||||||
|
layout: blog_post
|
||||||
|
title: Dependency Injection in Less Than 100 Lines of Pure JavaScript
|
||||||
|
slug: Dependency-Injection-in-Less-Than-100-Lines-of-Pure-JavaScript
|
||||||
|
date: 2019-11-16 14:33:36
|
||||||
|
created: '11-16-2019'
|
||||||
|
canonicalUrl: 'https://garrettmills.dev/blog/2019/11/16/Dependency-Injection-in-Less-Than-100-Lines-of-Pure-JavaScript/'
|
||||||
|
tags: blog
|
||||||
|
permalink: /blog/2019/11/16/Dependency-Injection-in-Less-Than-100-Lines-of-Pure-JavaScript/
|
||||||
|
blogtags:
|
||||||
|
- javascript
|
||||||
|
- DI
|
||||||
|
- patterns
|
||||||
|
---
|
||||||
|
If you've ever used Angular for any amount of time, you've probably noticed how freaking awesome its dependency injection is. With just the invocation of the [injectable decorator](https://angular.io/api/core/Injectable), you can pull in reusable instances of any service in your application just by referencing the type:
|
||||||
|
|
||||||
|
```typescript
|
||||||
|
import {Injectable} from '@angular/core';
|
||||||
|
import {BackendService} from './backend.service';
|
||||||
|
|
||||||
|
@Injectable()
|
||||||
|
export class AuthService {
|
||||||
|
constructor(
|
||||||
|
private backend: BackendService,
|
||||||
|
) {
|
||||||
|
this.backend.somethingAwesome();
|
||||||
|
}
|
||||||
|
}
|
||||||
|
```
|
||||||
|
Notice that I don't have to instantiate the `BackendService` anywhere because it's already handled for me by Angular. This has the added benefit of ensuring that only one instance of the `BackendService` is created during runtime, which is good for memory!
|
||||||
|
|
||||||
|
## Background - Flitter
|
||||||
|
For the past year or so, I've been creating an Express-backed JavaScript web-app framework called [Flitter](https://flitter.garrettmills.dev/). One of the major philosophies in Flitter is that everything should be a class. So, while Flitter incorporates many traditionally ES5 libraries -- Express, Mongoose, Agenda.js, &c -- Flitter provides a system for defining their resources using ES6+ classes. That's why in Flitter you'll never see, for example, a schema based model definition:
|
||||||
|
|
||||||
|
```javascript
|
||||||
|
// Mongoose - from the getting started guide
|
||||||
|
var kittySchema = new mongoose.Schema({
|
||||||
|
name: String
|
||||||
|
});
|
||||||
|
|
||||||
|
kittySchema.methods.speak = function () {
|
||||||
|
var greeting = this.name
|
||||||
|
? "Meow name is " + this.name
|
||||||
|
: "I don't have a name";
|
||||||
|
console.log(greeting);
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
Instead, we define the appropriate class:
|
||||||
|
```javascript
|
||||||
|
// Using Flitter classes
|
||||||
|
const Model = require('libflitter/database/Model')
|
||||||
|
class Kitty extends Model {
|
||||||
|
static get __context() {
|
||||||
|
return {
|
||||||
|
name: String
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
speak() {
|
||||||
|
const greeting = this.name
|
||||||
|
? `Meow name is ${this.name}` : `I don't have a name`
|
||||||
|
console.log(greeting)
|
||||||
|
}
|
||||||
|
}
|
||||||
|
```
|
||||||
|
Having all our resources defined in standard classes is, subjectively, much easier to maintain and reason around than a multitude of different schema formats and function calls. Plus, it has the added benefit of enabling inheritance for all our resources out-of-the-box. But, it raises an interesting issue.
|
||||||
|
|
||||||
|
## The Problem With Classier Services
|
||||||
|
If everything is a class, how do we access reusable methods from our application? If we were using objects, this would be easy:
|
||||||
|
```javascript
|
||||||
|
// logHelpers.js
|
||||||
|
module.exports = exports = {
|
||||||
|
loggingLevel: 2,
|
||||||
|
out(what, level) {
|
||||||
|
if ( !Array.isArray(what) ) what = [what]
|
||||||
|
if ( level >= this.loggingLevel ) console.log(...what)
|
||||||
|
},
|
||||||
|
error(what, level = 0) { this.out(what, level) },
|
||||||
|
warn(what, level = 1) { this.out(what, level) },
|
||||||
|
info(what, level = 2) { this.out(what, level) },
|
||||||
|
debug(what, level = 3) { this.out(what, level) },
|
||||||
|
}
|
||||||
|
```
|
||||||
|
Seemingly, this is really easy to use. We just import the module and we're good to go:
|
||||||
|
```javascript
|
||||||
|
const logging = require('./logHelpers')
|
||||||
|
const someFunction = () => {
|
||||||
|
logging.info('someFunction has executed!')
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
But what happens if we want to create a different helper "class" that will send e-mails if an error is logged? Well, we _could_ just write the whole thing from scratch again, but that's not very [DRY](https://en.wikipedia.org/wiki/Don%27t_repeat_yourself). So instead, we override specific properties from the original helper:
|
||||||
|
```javascript
|
||||||
|
// emailLogHelpers.js
|
||||||
|
const logHelpers = require('./logHelpers')
|
||||||
|
module.exports = exports = Object.assign(logHelpers, {
|
||||||
|
emailOut(what, level) {
|
||||||
|
sendAnImaginaryEmailSomewhere(what);
|
||||||
|
this.out(what, level);
|
||||||
|
},
|
||||||
|
error(what, level = 0) { this.emailOut(what, level) },
|
||||||
|
})
|
||||||
|
```
|
||||||
|
But, this introduces ambiguity. What does `this` refer to in `error()`? What about in `emailOut()`? Can you spot the error? It feels correct from an OOP standpoint. However, if we call `error()` on the email helpers object, we will get the following error:
|
||||||
|
|
||||||
|
```
|
||||||
|
ReferenceError: out is not defined
|
||||||
|
at Object.emailLogHelpers (emailLogHelpers.js:6:4)
|
||||||
|
```
|
||||||
|
|
||||||
|
Why? Because `this` in the `emailOut` function doesn't actually refer to the combined object, but the original object at the time of creation. That is, the right-side of the `Object.assign` call.
|
||||||
|
|
||||||
|
This could easily be resolved by defining a `LogHelper` class and creating a child class `EmailLogHelper`. Then, in the `EmailLogHelper` class, `this` would unambiguously refer to the instance itself, which already has all the `LogHelper` methods. For example:
|
||||||
|
|
||||||
|
```javascript
|
||||||
|
// EmailLogHelper.js
|
||||||
|
const LogHelper = require('./LogHelper')
|
||||||
|
class EmailLogHelper extends LogHelper {
|
||||||
|
out(what, level) {
|
||||||
|
sendAnImaginaryEmailSomewhere(what);
|
||||||
|
super.out(what, level);
|
||||||
|
}
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
But, this leaves us with the root issue of class-based services:
|
||||||
|
> Service classes must be instantiated before they can be used.
|
||||||
|
|
||||||
|
Why is this a problem? Well, what if there's some config service that `LogHelper` relies on (or depends on...) to get the logging level? Well, then to use the service anywhere, we'd also have to instantiate the config service and pass that in to the log helper. But, then we have 20 nearly-identical instances of the same class doing the same thing. So what's the solution?
|
||||||
|
|
||||||
|
## Dependency Injection in ES6: Easier than you think!
|
||||||
|
The solution to all the problems above is to have some dependency injector manager class create instances of all the relevant services when the application starts. Then, whenever a class needs access to a service, it fetches the shared instance from the DI. This saves memory, and prevents the manual dependency-chaining problem above.
|
||||||
|
|
||||||
|
It turns out that, because of the niceness of the ES6 class syntax, it's pretty easy to implement a basic DI in vanilla JavaScript! We're going to approach this in multiple parts.
|
||||||
|
|
||||||
|
### The Service Class
|
||||||
|
A service (for our basic purposes) is just a class that should be instantiated once the first time it is needed, then re-used for subsequent calls. So, the service class can be entirely bare for now:
|
||||||
|
```javascript
|
||||||
|
class Service {
|
||||||
|
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
Eventually, you can make this system more advanced by doing fancy things like tracking service state or even making services themselves injectable! Perhaps in a future post we'll explore this.
|
||||||
|
|
||||||
|
### The Injectable Class
|
||||||
|
This class will be the parent class of every class that can make use of automatic DI. In our Angular analogy, this is akin to the Injectable decorator. It should do 2 things: specify the services we want access to, and provide a mechanism for accessing them. Here's an example based on [Flitter's Injectable class](https://code.garrettmills.dev/Flitter/di/src/branch/master/src/Injectable.js):
|
||||||
|
|
||||||
|
```javascript
|
||||||
|
// Injectable.js
|
||||||
|
class Injectable {
|
||||||
|
static services = []
|
||||||
|
static __inject(container) {
|
||||||
|
this.services.forEach(serviceName => {
|
||||||
|
this.prototype[serviceName] = container.getService(serviceName)
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
Obviously, this is missing some niceties and type-checking, but the basic functionality is there. Statically, we define an array of service names for the instance to access, then, at some point before the class is instantiated, the `__inject` method is called. This method injects the services instances into the class' `prototype`, which is the under-the-hood function that is copied for each instance of the class. It gets these service instances from some magical `container` which we'll cover shortly.
|
||||||
|
|
||||||
|
This makes it really easy for classes to access services. For example:
|
||||||
|
```javascript
|
||||||
|
// DarkSideHelpers.js
|
||||||
|
const Injectable = require('./Injectable')
|
||||||
|
class DarkSideHelpers extends Injectable {
|
||||||
|
static services = ['logging']
|
||||||
|
doItAnakin() {
|
||||||
|
try {
|
||||||
|
somethingDangerous()
|
||||||
|
} catch (error) {
|
||||||
|
this.logging.error('It\'s not the Jedi way!')
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
```
|
||||||
|
No instantiation of the `LogHelper` class required! Isn't that nifty?
|
||||||
|
|
||||||
|
### The Service Container
|
||||||
|
But, fancy static will do us nothing if there's no services to inject. So, we need to create a place for them to live. Because we want to reuse instances as much as possible, we need a container to create and manage those instances for us. This container should: contain a mapping of service names to service classes, instantiate requested services if they don't exist yet, and return these instances on request. Let's try one:
|
||||||
|
|
||||||
|
```javascript
|
||||||
|
// ServiceContainer.js
|
||||||
|
const LogHelper = require('./LogHelper')
|
||||||
|
const EmailLogHelper = require('./EmailLogHelper')
|
||||||
|
|
||||||
|
class ServiceContainer {
|
||||||
|
constructor() {
|
||||||
|
// We define the service classes here, but we won't
|
||||||
|
// instantiate them until they're needed.
|
||||||
|
this.definitions = {
|
||||||
|
logging: LogHelper,
|
||||||
|
emailLogging: EmailLogHelper,
|
||||||
|
}
|
||||||
|
|
||||||
|
// This is where the container will store service instances
|
||||||
|
// so they can be reused when requested.
|
||||||
|
this.instances = {}
|
||||||
|
}
|
||||||
|
|
||||||
|
getService(serviceName) {
|
||||||
|
// Create a service instance if one doesn't already exist.
|
||||||
|
if ( !this.instances[serviceName] ) {
|
||||||
|
const ServiceClass = this.definitions[serviceName]
|
||||||
|
this.instances[serviceName] = new ServiceClass()
|
||||||
|
}
|
||||||
|
return this.instances[serviceName]
|
||||||
|
}
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
Our bare-bones service container contains a list of service definitions, and a method for retrieving service instances. It satisfies our requirements because it won't instantiate a service until it's needed, but will reuse existing instances. So, we have the container for our services, but now we the final piece to make all three parts work together.
|
||||||
|
|
||||||
|
### The Dependency Injector Host
|
||||||
|
The DI host is the boss of the whole operation. It's responsible for creating an instance of the container (or even multiple different instances) and keeping track of them. It is also responsible for calling the magic `__inject` method on classes before they're instantiated. There are several different strategies for how this can be done. Each has its own merit based on the situation, but we'll look at one that works well for standalone applications:
|
||||||
|
|
||||||
|
```javascript
|
||||||
|
// DependencyInjector.js
|
||||||
|
const ServiceContainer = require('./ServiceContainer.js')
|
||||||
|
class DependencyInjector {
|
||||||
|
constructor() {
|
||||||
|
this.container = new ServiceContainer()
|
||||||
|
}
|
||||||
|
|
||||||
|
// Injects the dependencies into an uninstantiated class
|
||||||
|
make(Class) {
|
||||||
|
return Class.__inject(this.container)
|
||||||
|
}
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
Like the rest of our classes, this one is pretty straightforward. When constructed, it creates a new service container. Then, we can pass in classes to the `make` method and it will inject dependencies from the container into the class.
|
||||||
|
|
||||||
|
The DI instance should be shared across your entire application. This will help re-use service instances as much as possible. Here's a silly example:
|
||||||
|
|
||||||
|
## A Spam-Generating Example App
|
||||||
|
As an example of how to use this system, let's create a very basic application. This application should, on run, repeatedly send spam email to its owners. We're going to use our fancy dependency injector for this.
|
||||||
|
|
||||||
|
```javascript
|
||||||
|
// App.js
|
||||||
|
const Injectable = require('./Injectable')
|
||||||
|
class App extends Injectable {
|
||||||
|
static services = ['emailLogging']
|
||||||
|
run() {
|
||||||
|
setInterval(() => {
|
||||||
|
this.emailLogging.error('Haha made ya\' look!')
|
||||||
|
}, 5000)
|
||||||
|
}
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
Now, we'll tie it all together by using our DI to run the app:
|
||||||
|
```javascript
|
||||||
|
// index.js
|
||||||
|
// Create the dependency injector instance for the application
|
||||||
|
const DI = require('./DependencyInjector')
|
||||||
|
const di = new DI()
|
||||||
|
|
||||||
|
// Now, create the instance of our application using the DI to inject services
|
||||||
|
const App = di.make(require('./App'))
|
||||||
|
const app = new App() // Has access to the emailLogging service
|
||||||
|
|
||||||
|
app.run();
|
||||||
|
```
|
||||||
|
|
||||||
|
## Conclusion
|
||||||
|
> Dependency injection is a powerful tool ... for reducing code complexity and properly sub-dividing your code into pure, maintainable bits.
|
||||||
|
|
||||||
|
We have built a basic application with injectable dependencies in vanilla ES6. Obviously, there are a lot of enhancements and improvements that could be made here. For example, type checking for services and containers, making the services themselves injectable, moving the `Injectable` base class to an [ES7 decorator](https://www.martin-brennan.com/es7-decorators/) so it can be applied to classes with other parents, &c. Perhaps I'll do a follow-up in the future. But, I hope this article was a good illustration of the power of DI in making code nicer. Dependency injection is a powerful tool not just for reducing memory load, but also for reducing code complexity and properly sub-dividing your code into pure, maintainable bits. Thanks for making it this far, and if you have any questions, be sure to comment below.
|
||||||
|
|
||||||
|
Garrett
|
||||||
|
|
||||||
|
_P.S. - You can find the code used in this example [here](https://code.garrettmills.dev/garrettmills/es6-di)._
|
||||||
305
src/blog/posts/2020-03-06-gitea.md
Normal file
305
src/blog/posts/2020-03-06-gitea.md
Normal file
@@ -0,0 +1,305 @@
|
|||||||
|
---
|
||||||
|
layout: blog_post
|
||||||
|
title: Code Freedom with Gitea & Drone - Part I
|
||||||
|
slug: Code-Freedom-with-Gitea-and-Drone-Part-I
|
||||||
|
date: 2020-03-06 00:01:00
|
||||||
|
tags: blog
|
||||||
|
permalink: /blog/2020/03/06/Code-Freedom-with-Gitea-and-Drone-Part-I/
|
||||||
|
blogtags:
|
||||||
|
- devops
|
||||||
|
- tutorial
|
||||||
|
- hosting
|
||||||
|
---
|
||||||
|
## Setting Up a Kickass, Self-Hosted, GitHub Alternative with Continuous Integration
|
||||||
|
|
||||||
|
> This is part I, wherein we set up the web-based GitHub alternative, Gitea. Stay tuned for part II, where we will setup the Docker-based continuous-integration solution, Drone, with plugins for Gitea.
|
||||||
|
|
||||||
|
As I have chronicled before, over the last few years I have been on a journey to move to using 100% self-hosted services. The basics were fairly easy (cloud, calendar, contacts, website, &c.), but I ran into a bit of a pain point when it came to moving away from GitHub.
|
||||||
|
|
||||||
|
I write a pretty large amount of code in a week, and I rely on unit/integration tests to help make sure everything is running smoothly. So, for this solution a good continuous-integration platform was absolutely necessary. As a bonus, I wanted it to integrate nicely with whatever web-based Git hosting server I was using.
|
||||||
|
|
||||||
|
Eventually I settled on a stack of [Gitea](https://gitea.io/en-us/) for the web-based repository management, and [Drone](https://drone.io/) as my continuous-integration platform.
|
||||||
|
|
||||||
|
### Why not GitLab?
|
||||||
|
|
||||||
|
At past jobs, I've used [GitLab](https://about.gitlab.com/). GitLab is a self-hostable web-based git repo manager with *built-in* continuous-integration support. For the most part, it worked pretty well, but I always had the nagging feeling that I wasn't making full use of its features.
|
||||||
|
|
||||||
|
For my purposes, GitLab is just too heavy and does too much. For enterprise teams, this [expansive feature-set](https://about.gitlab.com/stages-devops-lifecycle/) is probably useful, but for my simple use case, I found it to be slower and more resource-intensive than necessary.
|
||||||
|
|
||||||
|
### Enter: Gitea...
|
||||||
|
|
||||||
|
<center>
|
||||||
|
<img src="https://static.garrettmills.dev/gist/blog-gitea-1.png">
|
||||||
|
<br>
|
||||||
|
<small>An example of the Gitea interface (<a href="https://code.garrettmills.dev/flitter/di">flitter-di</a>).</small>
|
||||||
|
</center>
|
||||||
|
|
||||||
|
|
||||||
|
Gitea is a self-hosted Git platform that is very similar to GitHub. It provides web-based repositories that can be shared with different levels of collaboration, wiki, issues, pull-requests, releases, multiple auth sources, and support for many different CI platforms.
|
||||||
|
|
||||||
|
Gitea spars with GitHub feature-for-feature, for the most part. I didn't make extensive use of GitHub's more advanced features (and don't do so with Gitea either), but in my day-to-day use I've yet to run into a situation where I found Gitea lacking.
|
||||||
|
|
||||||
|
It also ships in a single binary executable file that is less than 80 MB, practically sips system resources while running, and is pretty configurable if you care to dig in.
|
||||||
|
|
||||||
|
#### ...and Drone.
|
||||||
|
|
||||||
|
<center>
|
||||||
|
<img src="https://static.garrettmills.dev/gist/blog-gitea-2.png">
|
||||||
|
<br>
|
||||||
|
<small>An example of the Drone CI interface.</small>
|
||||||
|
</center>
|
||||||
|
|
||||||
|
|
||||||
|
For continuous-integration, I decided to branch out and go with Drone. Drone is a stupid-simple continuous-integration platform based on Docker containers. It has a few particular benefits that I care about:
|
||||||
|
|
||||||
|
- Excellent integration with Gitea for commits, pull-requests, and authentication
|
||||||
|
- Everything's containerized, so concurrent builds are fine
|
||||||
|
- Pipelines are defined in YAML files in the repositories themselves
|
||||||
|
- Lots of pre-built containers, but you can also use *any* Docker container as a build-step
|
||||||
|
|
||||||
|
Drone uses a core server, which runs in Docker, and any number of runners, which also run in Docker and spawn containers to run the individual steps in the pipeline built repositories.
|
||||||
|
|
||||||
|
## Step 0 - Prerequisites
|
||||||
|
|
||||||
|
For this project, you need a server or VPS instance that is capable of running docker containers, and is accessible from either the Internet, or whatever network you are setting this up on.
|
||||||
|
|
||||||
|
I am using a physical server for this, but you can just as easily spin up a Docker-capable VPS from a company like [DigitalOcean](https://www.digitalocean.com/pricing/#Compute).
|
||||||
|
|
||||||
|
I'm using Ubuntu 18.04 in this tutorial, but you can pretty easily generalize this to whatever your OS of preference is.
|
||||||
|
|
||||||
|
### Software Requirements
|
||||||
|
|
||||||
|
- Git (some recent version, please)
|
||||||
|
- Docker (setting this up is outside the scope of this post. [Here's](https://www.digitalocean.com/community/tutorials/how-to-install-and-use-docker-on-ubuntu-18-04) a guide.)
|
||||||
|
|
||||||
|
## Step 1 - Reverse Proxy
|
||||||
|
|
||||||
|
While both Gitea and Drone have support for [serving](https://docs.drone.io/server/reference/drone-tls-cert/) over [TLS](https://docs.gitea.io/en-us/https-setup/), we're going to use a more scalable approach and access them through a reverse proxy. A reverse proxy is simply a web-server (in our case, Apache2, but you can also use NGINX) that accepts TLS connections on a public port and, based on the incoming domain, proxies those requests to the appropriate backend service.
|
||||||
|
|
||||||
|
As mentioned, we're going to set up Apache2 for this case, but that's not a hard requirement:
|
||||||
|
|
||||||
|
```shell
|
||||||
|
~# apt install -y apache2 # install the server
|
||||||
|
~# a2enmod proxy # enable the proxy module
|
||||||
|
~# a2enmod proxy_http # enable the HTTP proxy
|
||||||
|
~# a2enmod proxy_wstunnel # enable the WebSocket proxy
|
||||||
|
~# systemctl enable apache2 # make apache2 start on boot
|
||||||
|
~# systemctl restart apache2 # restart apache2
|
||||||
|
```
|
||||||
|
|
||||||
|
These commands install the Apache2 server and enables the proxy modules we need for this setup.
|
||||||
|
|
||||||
|
## Step 2 - Install Gitea
|
||||||
|
|
||||||
|
You can find the links to download the latest version of Gitea [here](https://dl.gitea.io/gitea/), but at the time of writing, the latest stable version is 1.11.1, so I'll be using that for this guide.
|
||||||
|
|
||||||
|
> Note: this is meant as a quick walk-through only, where I highlight the specifics of my configuration. For setup instructions and more in-depth info, see the excellent [Gitea docs](https://docs.gitea.io/en-us/install-from-binary/).
|
||||||
|
|
||||||
|
Download the binary:
|
||||||
|
|
||||||
|
```shell
|
||||||
|
wget https://dl.gitea.io/gitea/1.11.1/gitea-1.11.1-linux-amd64
|
||||||
|
mv gitea-1.11.1-linux-amd64 gitea
|
||||||
|
```
|
||||||
|
|
||||||
|
This has created a `gitea` binary in the current directory. This is the single binary necessary to run the Gitea server.
|
||||||
|
|
||||||
|
### Create the git user
|
||||||
|
|
||||||
|
We don't want to run Gitea directly as root, or some actual user, so we're going to create a user, `git`, that Gitea will use to run the server and manage files:
|
||||||
|
|
||||||
|
```shell
|
||||||
|
~# adduser --system --shell /bin/bash --group git --disabled-password --home /home/git git
|
||||||
|
```
|
||||||
|
|
||||||
|
You *definitely* need a separate user for Gitea, particularly because we're going to be enabling SSH repository access. So, segmenting security here is an absolute must. Don't be tempted to run this as root. Ever.
|
||||||
|
|
||||||
|
### Initial Setup
|
||||||
|
|
||||||
|
Generally, follow the instructions in the Gitea Docs to create the default directories and install the binary. Then, you need to create a SystemD service file to start Gitea as a daemon in the background. Here's an example of the file I use, placed in `/etc/systemd/system/gitea.service`:
|
||||||
|
|
||||||
|
```ini
|
||||||
|
[Unit]
|
||||||
|
Description=Gitea
|
||||||
|
After=syslog.target
|
||||||
|
After=network.target
|
||||||
|
|
||||||
|
[Service]
|
||||||
|
RestartSec=2s
|
||||||
|
Type=simple
|
||||||
|
User=git
|
||||||
|
Group=git
|
||||||
|
WorkingDirectory=/var/lib/gitea/
|
||||||
|
ExecStart=/usr/local/bin/gitea web -c /etc/gitea/app.ini
|
||||||
|
Restart=always
|
||||||
|
Environment=USER=git HOME=/home/git GITEA_WORK_DIR=/var/lib/gitea
|
||||||
|
|
||||||
|
[Install]
|
||||||
|
WantedBy=multi-user.target
|
||||||
|
```
|
||||||
|
|
||||||
|
This service will restart 2 seconds after the process fails, should that happen. After creating this service file, we need to do three things: (1) create the `git` user's home directory, (2) reload the SystemD daemon, and (3) start the Gitea service:
|
||||||
|
|
||||||
|
```shell
|
||||||
|
~# mkdir /home/git
|
||||||
|
~# chown -R git:git /home/git
|
||||||
|
~# systemctl daemon-reload
|
||||||
|
~# systemctl start gitea
|
||||||
|
```
|
||||||
|
|
||||||
|
Now, if everything has gone well, you should be able to navigate to port `3000` of the server and see the Gitea interface. (Don't worry, we'll be locking that down later on.) Clicking "Login" for the first time, you should be presented with the Initial Configuration form:
|
||||||
|
|
||||||
|
<center>
|
||||||
|
<img src="https://static.garrettmills.dev/gist/blog-gitea-3.png">
|
||||||
|
<br>
|
||||||
|
<small>The Gitea Initial Configuration wizard sets up the database backend and creates a basic <code>/etc/gitea/app.ini</code> config file.</small>
|
||||||
|
</center>
|
||||||
|
|
||||||
|
If you have an existing MySQL or Postgres server, you can configure those credentials here. If you don't, you can use the built-in SQLite3 driver to use a filesystem-backed database.
|
||||||
|
|
||||||
|
> Note: it's really recommended to use a proper SQL backend as opposed to SQLite3. Particularly for larger deployments, SQLite3 can become resource intensive, less performant, and harder to manage and maintain compared to something like PostgreSQL.
|
||||||
|
|
||||||
|
Most of the settings here you can leave at the defaults, or customize to suit your fancy, but of particular note are the following:
|
||||||
|
|
||||||
|
- **SSH Server Domain:** change this to be the external domain that will be used to access the server. (e.g. rather than "localhost", perhaps it should be "git.yourdomain.com".)
|
||||||
|
- We're going to set up a non-standard SSH config wherein the main SSH server used to access your server for day-to-day admin stuff runs on a different port than 22. Then, we'll enable Gitea's built-in SSH server to allow SSH access ONLY to Git repositories on port 22.
|
||||||
|
- Running your main SSH server on a non-standard port, while not impenetrable, is a good basic security measure for reducing, somewhat, the ease with which SSH scanners target your server. More info [here](https://serverfault.com/a/749323/495374).
|
||||||
|
- **Gitea HTTP Listen Port**: leave this at the default, or some non-standard port. We're going to be using the reverse proxy on the standard ports 80 and 443 to internally proxy requests to this port.
|
||||||
|
- **Gitea Base URL:** because we're going to be using reverse proxy, the actual URL users will use to access the instance is different than the port the native server runs on. So, this should be the address users will navigate to to use the reverse proxy version. (e.g. "https://git.yourdomain.com/")
|
||||||
|
|
||||||
|
After changing the appropriate settings, click "Install Gitea." This will setup the initial config file, and redirect you back to the homepage.
|
||||||
|
|
||||||
|
Unless you specified it during the setup wizard, the first user to register on your instance will become the site administrator, so it's a good idea to go ahead and create that account at this point.
|
||||||
|
|
||||||
|
## Step 3: SSH Server Tweaks
|
||||||
|
|
||||||
|
As mentioned above, we're going to tweak the port of the native SSH server and use Gitea's built-in SSH server on port 22. To do this, we will first change the native SSH port. Let's do that now.
|
||||||
|
|
||||||
|
Most Linux distros use an implementation of SSHD which stores its daemon configuration file at `/etc/ssh/sshd_config`. Let's edit that file to change the default listening port.
|
||||||
|
|
||||||
|
First, choose a new port for the SSH server to listen on. Ideally this would be something above the `1050`s, as these are largely unreserved and are meant for misc applications.
|
||||||
|
|
||||||
|
After choosing a port, modify the SSHD config file to include the following line:
|
||||||
|
|
||||||
|
```ini
|
||||||
|
Port 4458
|
||||||
|
```
|
||||||
|
|
||||||
|
(Where `4458` is replaced with the port number you chose.) Make sure that, if there is an un-commented like specifying `Port 22`, you comment it out or remove it.
|
||||||
|
|
||||||
|
Technically, that's the only change required to change the SSH port. However, there's one big hole here that I have fallen in many times:
|
||||||
|
|
||||||
|
**Make sure you open the new port in the firewall so you don't lose remote access to the system!**
|
||||||
|
|
||||||
|
Most system firewalls open port 22 by default, but we need to open the new port we've chosen. Restarting the SSH server now, we would lose access to the system. You need to open the appropriate port in your system's firewall. It's probably best for you to look up what firewall type your system is running, but here are two common ones, `UFW` and `iptables`:
|
||||||
|
|
||||||
|
```shell
|
||||||
|
~# ufw allow 4458 # for UFW systems
|
||||||
|
~# iptables -I INPUT -p tcp -m tcp --dport 4458 -j ACCEPT # for iptables systems
|
||||||
|
~# iptables-save > /etc/iptables/rules.v4
|
||||||
|
```
|
||||||
|
|
||||||
|
Now that we've opened the port, we can restart the SSH server, and it should start listening on the new port:
|
||||||
|
|
||||||
|
```shell
|
||||||
|
~# systemctl restart sshd
|
||||||
|
```
|
||||||
|
|
||||||
|
This will disconnect you from the SSH connection. To open a new connection, specify the `-p` flag with the new port number for most `ssh` clients:
|
||||||
|
|
||||||
|
```shell
|
||||||
|
~$ ssh -p 4458 root@git.yourdomain.com
|
||||||
|
```
|
||||||
|
|
||||||
|
### Setting up Gitea's SSH server
|
||||||
|
|
||||||
|
Now that we've cleared port 22, we will configure Gitea to start its internal SSH server on that port. To do this, we need to edit the `/etc/gitea/app.ini` file that was created during the initial configuration.
|
||||||
|
|
||||||
|
Under the `[server]` config block, ensure that the following values are set:
|
||||||
|
|
||||||
|
```ini
|
||||||
|
[server]
|
||||||
|
START_SSH_SERVER = true
|
||||||
|
SSH_PORT = 22
|
||||||
|
```
|
||||||
|
|
||||||
|
This will tell Gitea to start its internal SSH server on port 22. However, if we were to restart the Gitea server right now, we would run into an error. That's because, since we have configured our Gitea server to run as the non-root user `git`, it doesn't have permission to bind to port 22. To solve that, we can specifically grant permission:
|
||||||
|
|
||||||
|
```shell
|
||||||
|
~# setcap CAP_NET_BIND_SERVICE=+eip /usr/local/bin/gitea
|
||||||
|
```
|
||||||
|
|
||||||
|
This will give the Gitea binary permission to bind to ports under `1000`. Now, we can restart the Gitea server:
|
||||||
|
|
||||||
|
```shell
|
||||||
|
~# systemctl restart gitea
|
||||||
|
```
|
||||||
|
|
||||||
|
When you create repositories with your account, you should now see the option to clone the repo using SSH:
|
||||||
|
|
||||||
|
<center>
|
||||||
|
<img src="https://static.garrettmills.dev/gist/blog-gitea-4.png">
|
||||||
|
<br>
|
||||||
|
<small>You will need to add your public key to your account in User > Profile > Keys before you can clone the repositories.</small>
|
||||||
|
</center>
|
||||||
|
|
||||||
|
## Step 4: Reverse Proxy (reprise)
|
||||||
|
|
||||||
|
Now that we have our Gitea server up and running, we need to set up the reverse proxy to allow users to connect to our server from the outside world. This is done by creating a virtual host on your web-server of choice (again, I'm using Apache2 for this guide) that listens for requests from a particular domain name and forwards them to the internal server for Gitea.
|
||||||
|
|
||||||
|
This is pretty straightforward. First, make sure that the domain you specified in the Gitea initial configuration wizard points to the server running the reverse proxy (e.g. an `A` record for git.yourdomain.com).
|
||||||
|
|
||||||
|
Next, create the virtual host file in your web-server's configuration. Here's an example of the one I use for Apache2. Add this site to `/etc/apache2/sites-available/git.conf`:
|
||||||
|
|
||||||
|
```xml
|
||||||
|
<VirtualHost *:80>
|
||||||
|
ServerName git.yourdomain.com
|
||||||
|
Redirect / https://git.yourdomain.com/
|
||||||
|
</VirtualHost>
|
||||||
|
<VirtualHost *:443>
|
||||||
|
ServerName git.yourdomain.com
|
||||||
|
SSLEngine on
|
||||||
|
SSLCertificateFile /path/to/your/cert.crt
|
||||||
|
SSLCertificateKeyFile /path/to/your/cert.key
|
||||||
|
SSLCertificateChainFile /path/to/your/ca.crt
|
||||||
|
|
||||||
|
SetEnv proxy-sendcl
|
||||||
|
LimitRequestBody 102400000
|
||||||
|
ProxyPreserveHost On
|
||||||
|
ProxyPass / http://127.0.0.1:3000/
|
||||||
|
ProxyPassReverse / http://127.0.0.1:3000/
|
||||||
|
</VirtualHost>
|
||||||
|
```
|
||||||
|
|
||||||
|
Essentially, this virtual host defines a listener for the `git.yourdomain.com` address on port `80` and redirects it to use TLS on the default port. *This is considered best practice. You should not allow insecure connections to your Gitea instance, particularly because it will transmit sensitive user data like passwords, SSH keys, and other info.*
|
||||||
|
|
||||||
|
Then, we define a virtual host listener for the same domain on port `443` and configure it to use the TLS certificates. The generation and maintenance of these certificates is well beyond the scope of this walk-through, but suffice it to say that, if you're a beginner to TLS, you can generate **free** certificates that renew automatically using the [Let's Encrypt CertBot plugin for Apache2](https://www.digitalocean.com/community/tutorials/how-to-secure-apache-with-let-s-encrypt-on-ubuntu-18-04). This is a great solution here.
|
||||||
|
|
||||||
|
The latter half of the `443` virtual host does two things:
|
||||||
|
|
||||||
|
- Raise the size limit on the request body to around 100MB. This helps prevent errors for larger repositories or repositories with large files. It's a good idea not to set this *too* high, as it exposes your server to additional vulnerabilities.
|
||||||
|
- Reverse proxy all requests to this virtual host along to the internal server running on port `3000`, while preserving the original host in the process.
|
||||||
|
- This is the magic that makes the reverse proxy work. Notice that, while the virtual host is requiring users to connect via a secure format, the internal reverse proxy is using unencrypted HTTP. This is one of the most powerful things about reverse proxies: they have the ability to generally secure unencrypted web-apps.
|
||||||
|
- Even though Gitea supports running a TLS server, using an Apache2 reverse proxy enables us to (1) run the Drone CI from the same machine on a different virtual host, and (2) use a generic and well-supported means of managing sites and certificates, rather than modifying it for each individual application we run.
|
||||||
|
|
||||||
|
After creating the virtual host, we will enable it and reload Apache2:
|
||||||
|
|
||||||
|
```shell
|
||||||
|
~# a2ensite git
|
||||||
|
~# systemctl reload apache2
|
||||||
|
```
|
||||||
|
|
||||||
|
Now, you should be able to navigate to `https://git.yourdomain.com` and see the Gitea server.
|
||||||
|
|
||||||
|
> At this point, it's a good idea to entirely remove access to the unsecured port 3000 externally. This usually means ensuring that your firewall is properly configured to only whitelist the appropriate ports for the two SSH servers, and the HTTP/S servers (as well as anything else you have running).
|
||||||
|
|
||||||
|
## Part I Conclusion
|
||||||
|
|
||||||
|
That's where we'll stop for part I. At this point, you should have a fully--functional, self-hosted Git server that spars feature-for-feature with GitHub, but with complete privacy and control of your data.
|
||||||
|
|
||||||
|
In part II (coming soon), we'll look at setting up the Docker-based Drone CI and integrating it with Gitea for a seamless, efficient, joyful development/DevOps experience.
|
||||||
|
|
||||||
|
Thanks!
|
||||||
|
Garrett
|
||||||
|
|
||||||
|
> P.S. - As always, if you have questions, feel free to reach out. You can get in touch with me using the information [here](https://garrettmills.dev/#contact).
|
||||||
167
src/blog/posts/2020-07-23-code-from-home.md
Normal file
167
src/blog/posts/2020-07-23-code-from-home.md
Normal file
@@ -0,0 +1,167 @@
|
|||||||
|
---
|
||||||
|
layout: blog_post
|
||||||
|
title: How to Code From Home Like a Boss
|
||||||
|
date: 2020-07-23 00:01:00
|
||||||
|
slug: How-to-Code-From-Home-Like-a-Boss
|
||||||
|
tags: blog
|
||||||
|
permalink: /blog/2020/07/23/How-to-Code-From-Home-Like-a-Boss/
|
||||||
|
blogtags:
|
||||||
|
- tutorial
|
||||||
|
- webdev
|
||||||
|
- devops
|
||||||
|
---
|
||||||
|
|
||||||
|
## Tips, tricks, and downright hacks to make working as a remote developer just a little nicer
|
||||||
|
|
||||||
|
Given everything that's happening right now (c. 2020-07-23), many software developers have been fortunate to be able to work from home. However, there are some challenges I encountered with my office's particular brand of development workflow. Over the last couple months, I've fleshed out a pretty good stack of tools for working around them. In this writeup, I want to go over some of them.
|
||||||
|
|
||||||
|
### "Remote" vs. Remote
|
||||||
|
|
||||||
|
There are really two different paradigms for coding remotely. The first, and most obvious, is to simply clone the code repositories to your local machine at home and work from there.
|
||||||
|
|
||||||
|
However, part of the reason the transition to a remote workflow was so challenging for me, anyway, was because my office uses a centralized server for development. Our applications have a complex architecture, job queues, and a large database containing a full-restore of test data from production. We host our development workspaces on a central few servers, and NFS/SMB mount those directories to our local machines. Then, we edit files in those mounts in our workstations.
|
||||||
|
|
||||||
|
This is much harder to do remotely, because we can't simply clone the code repos and be up and running. We need all the supporting development tools, software dependencies, NGINX/PHP configuration, and, lest we forget, the database.
|
||||||
|
|
||||||
|
This meant that, in the early days, my "remote" development setup looked like this:
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
<img src="https://static.garrettmills.dev/gist/remote1.png"/>
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
That, my friends, is Sublime Text 3 running through a compressed Chrome Remote Desktop session. Yep.
|
||||||
|
|
||||||
|
As you can imagine, that was a less than desirable experience.
|
||||||
|
|
||||||
|
### Trick 0: VPN
|
||||||
|
|
||||||
|
This is basically requisite for most corporate networks these days, but for me to have any hope at all of getting a good experience, I needed to ditch the remote relays like Chrome Remote Desktop/TeamViewer. All of the remote tools I'm about to talk about rely on good-ole-fashioned SSH and remote network access.
|
||||||
|
|
||||||
|
So, in order to do that securely, you need VPN access to the office. This is something I helped stand-up in the weeks after this all started, so we're good to go there. If your shop doesn't have an existing solution, I've had good experience with [Pritunl](https://pritunl.com/). Pritunl is a VPN-server-manager that provides a web UI for managing users and VPN servers. It uses [OpenVPN](https://openvpn.net/) under the hood, so it's compatible with basically everything.
|
||||||
|
|
||||||
|
This project has the side requirement that we want to avoid joining our main development server to the VPN directly for security/control reasons, so our tools will need to work around that. However, I do have access to the Linux workstation at my desk.
|
||||||
|
|
||||||
|
### Trick 1: the IDE
|
||||||
|
|
||||||
|
So, I'm normally a JetBrains guy. Given the choice, I use WebStorm/PHPStorm for my projects. However, for work lately I've been using Visual Studio Code. Why? One reason: remote workspaces.
|
||||||
|
|
||||||
|
VS Code is built using web technologies, which means that it's _really_ good at running over a network connection. In fact, several [online IDEs](https://www.eclipse.org/che/) are build using VS Code for this reason. This feature also enabled another tool to exist: [sshcode](https://github.com/cdr/sshcode). sshcode is a wonderful little CLI tool that automates the process of SSH-ing into a remote computer and installing/starting VS Code's web server.
|
||||||
|
|
||||||
|
Then, it tunnels the VS Code server port over SSH and launches Chromium in app-mode on your local machine. That entire process results in what looks like native VS Code running on my local machine:
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
<img src="https://static.garrettmills.dev/gist/remote2.png"/>
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
The benefits of this over remote desktop are _many_, but here are a few:
|
||||||
|
|
||||||
|
- Because the front-end of the editor is running in Chromium on your local machine, there is zero extra latency when actually coding in the files. The only things that are slightly slower are file-operations like searching/saving/opening files.
|
||||||
|
- Extensions even work! If you use the `--b` flag on the sshcode command, it will 2-way sync the extensions from your local machine, so any extensions you install will be saved and restored.
|
||||||
|
- You can have multiple windows of this open across multiple displays, unlike remote desktop which is usually limited to a single display.
|
||||||
|
- Because the VS Code server is actually running on my workstation at the office, I can open the NFS shares that I normally work on, without the extra overhead of having to mount the NFS shares to my local machine over the VPN.
|
||||||
|
|
||||||
|
Probably the biggest quality-of-life improvement for me, though, was the latency editing files. As someone who relies on quick keyboard shortcuts and tricks to navigate/edit code quickly, editing over remote desktop was a _nightmare_. It may not sound like much, but the extra 100-200ms of latency adds up quick.
|
||||||
|
|
||||||
|
### Trick 2: SSH
|
||||||
|
|
||||||
|
Okay, okay, this isn't particularly ground-breaking, but I felt I should include it for the sake of completeness. When I'm working, I use [Guake](https://github.com/Guake/guake) as an overhead shell, and I have no fewer than 6 tabs open SSH-ed into my remote machine. This means that, at any time, if I need to jump into the shell for something, I don't have to wait for SSH to start up. This goes a long way to making it more immersive.
|
||||||
|
|
||||||
|
Plus, having a lot of shells at the ready allows me to do long-running commands like sshcode, or the Angular development server, or [HTOP](https://hisham.hm/htop/), &c. without having to worry about running out of space.
|
||||||
|
|
||||||
|
And, because I'm using VS Code to edit the files that exist on my remote development workspace at the office, all the CLI tool's we have in-house, or that I've added personally still work.
|
||||||
|
|
||||||
|
### Trick 3: the Database
|
||||||
|
|
||||||
|
Because our applications are complex, we have rather large databases with lots of data that we work with and modify throughout the development workflow. So, having a database browser that can keep up with it is a must.
|
||||||
|
|
||||||
|
While, for simpler projects, just using MySQL/MariaDB/PostgreSQL from the CLI when you need to check things in the table is probably fine, when you get to the realm of hundreds of tables and millions of records, this becomes impractical.
|
||||||
|
|
||||||
|
On my office machine I use [DBeaver](https://dbeaver.io/) for this. DBeaver is an _awesome_ cross-platform database tool, and I've gotten pretty quick navigating its interface.
|
||||||
|
|
||||||
|
I had been using DBeaver over remote desktop, but again the latency was driving me nuts. Luckily, DBeaver (and most database browsers) have a feature that allows you to tunnel the database connection through SSH:
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
<img src="https://static.garrettmills.dev/gist/remote3.png">
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
This means that I can configure the connection as though I'm sitting at my office PC, then configure DBeaver to tunnel the connection using the "Agent" authentication method, and it will connect as if I'm on my work PC.
|
||||||
|
|
||||||
|
This is awesome because it means that I can access and work with the databases using the software I'm familiar with, but running on my local machine.
|
||||||
|
|
||||||
|
This has many of the same benefits as VS Code server. The interface is dramatically less latent, however there is a bit of a longer delay when connecting to/fetching data from the databases, because it has to tunnel through SSH. However, I've found the slight loss in loading times to be well worth the improvements in UI latency.
|
||||||
|
|
||||||
|
> Side note:
|
||||||
|
>
|
||||||
|
> For personal projects, and because I'm a JetBrains shill, I prefer DataGrip as my DB browser, which also supports similar SSH tunneling, and will even store the schema introspection information locally to make searching through and jumping between databases/tables faster.
|
||||||
|
|
||||||
|
### Trick 4: Web Development
|
||||||
|
|
||||||
|
In case it wasn't clear, I work on a lot of web applications. This means that they need to be tested through a web browser. Because our development is hosted on central servers in the office, the way we do this is to navigate to our user-specific domain on the server, and NGINX connects us with our development workspace.
|
||||||
|
|
||||||
|
Something like `http://my-username.my-project.some-server/`. In the office, this works really well, because it removes the load of running the code and databases from our local workstations to the much more powerful server. However, because we wanted to avoid joining the main development server to the VPN for security/control reasons, this means that I can't directly navigate to my project URL on the server from my local machine.
|
||||||
|
|
||||||
|
So, for a long time I was (you guessed it!) doing it through remote desktop. Again, again, latency was terrible, and having to cram the browser's devtools onto the same screen as everything else made debugging difficult. (I usually spread them across 2 screens, but remote desktop doesn't support that.)
|
||||||
|
|
||||||
|
After a few weeks of this, I got fed up enough that I spent a couple hours of searching for a solution. I finally landed on something pretty nice: Squid.
|
||||||
|
|
||||||
|
For background, I usually use Firefox Developer Edition at work. This is nice because 1) I'm a Firefox person anyway, and 2) it lets me keep my work profile separate from my personal profile in normal Firefox.
|
||||||
|
|
||||||
|
Firefox has an interesting feature that I haven't been able to replicate in Chromium that proved useful: browser-level proxy support. See, Chromium will use a proxy, but only if it's configured at the system level. However, Firefox will happily let you configure a proxy in its settings, and it will use it to browse the web. This is important, because I don't want to run my entire local machine through a proxy.
|
||||||
|
|
||||||
|
So, I set up a very basic [Squid](http://www.squid-cache.org/) proxy on my office workstation. This is, perhaps, the oldest trick of the bunch. If you've never heard of Squid, it's an open-source web proxy that's been around forever whose main goal is caching resources to make browsing more efficient. However, it has the powerful ability to act as a general HTTP/S proxy.
|
||||||
|
|
||||||
|
After setting this up on my work machine, I was able to configure Firefox Developer Edition on my _local_ machine to use the Squid proxy through the VPN. This essentially allows me to browse the web as though I were using my office workstation, but locally:
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
<img src="https://static.garrettmills.dev/gist/remote5.png">
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
Helpfully, Firefox lets you whitelist domains that don't need to run through the proxy. So, things like DuckDuckGo, Google, and DevDocs can use my local Internet connection, making them a bit snappier.
|
||||||
|
|
||||||
|
Setting up the proxy allows me to navigate to my development URL at work, and Firefox will proxy all the requests through my work PC, so the development server doesn't need to be on the VPN at all, and I can still use my devtools natively.
|
||||||
|
|
||||||
|
HTTP/S proxies are very common in large corporate environments that need to provide remote users with access to internal services, like Intranets. This is a much smaller scale version of that. In fact, this setup allows me to access other internal tools like our Git repositories, [Hound](https://github.com/hound-search/hound) instance, and deployment tools, which is a nice bonus.
|
||||||
|
|
||||||
|
### Trick 5: Remote Desktop
|
||||||
|
|
||||||
|
I know, I know. I've been railing against Remote Desktop and the latency involved for like 1600 works now. While the above tools mean that all the stuff I do on a regular basis can be done directly from my local machine, there are still one-off things that I need to remote in to my workstation to do.
|
||||||
|
|
||||||
|
For example, our time clock in the office only works if you access it from w/in the local network. So, to clock in/out, I need to remote into my workstation. Tasks like this aren't so frequent that they would actually benefit from a more over-engineered solution.
|
||||||
|
|
||||||
|
However, tools like Chrome Remote Desktop and TeamViewer have issues. For one, they open your corporate network up to the control of a 3rd party. Even if the company like Google or TeamViewer has a pretty good security track record, it's still a third party service that you're relying on to exist for the forseeable future.
|
||||||
|
|
||||||
|
The other issue is that tools like TeamViewer can be [exorbitantly expensive](https://www.teamviewer.com/en/buy-now/). Like $50 a seat, expensive. For a large company, this might be worth it. But, for a smaller shop, the extra cost per developer per month is non-trivial.
|
||||||
|
|
||||||
|
But, there are a _ton_ of really good remote desktop tools for _LANs_, and we just so happen to have a VPN set up that gives us virtual network access to our machine. So, there are two possible solutions here:
|
||||||
|
|
||||||
|
#### Windows
|
||||||
|
|
||||||
|
If you use Windows, or are willing to slum it, Windows Remote Desktop is a pretty good tool, and it will work over the VPN. This will give you secure access to your remote machine.
|
||||||
|
|
||||||
|
#### Linux
|
||||||
|
|
||||||
|
VNC! I use [TightVNC Server](https://tightvnc.com/). VNC is a great tool, because the desktop session runs on a different display screen than the physical session. So, you don't have to worry about running your physical monitors at work. I've set up a profile in [Remmina](https://remmina.org/) on my local machine so any time I need to access my work PC, I can just click an icon in my GNOME tray:
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
<img src="https://static.garrettmills.dev/gist/remote6.png">
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
### Conclusion
|
||||||
|
|
||||||
|
I hope someone else might find these tools useful in their transition. The more complex parts, like the VPN and HTTP/S proxy, might seem difficult to set up, but with some patience, you can get them up and running. The nice thing about the VPN/proxy setup is it can be shared by several developers.
|
||||||
|
|
||||||
|
In fact, if you have multiple people working remotely, you can (and should) set up the VPN and proxy on a shared server, so that it only has to be set up once. Then, everyone can use those tools.
|
||||||
|
|
||||||
|
For any job, the transition to remote work can be difficult. Particularly as developers, we sometimes rely on network resources and specialized software to make our workflows possible. However, through a process of trial and error, these are the tools I use to make my remote work much nicer.
|
||||||
|
|
||||||
|
In fact, between the HTTP/S proxy, remote VS Code, DBeaver's SSH tunnel, and plenty of SSH tabs, I rarely have to remote into my work machine directly. While there are still some drawbacks, the experience is not _much_ different than if I were sitting at my office machine developing directly, and that's pretty great.
|
||||||
302
src/blog/posts/2020-12-01-ionic-pwa.md
Normal file
302
src/blog/posts/2020-12-01-ionic-pwa.md
Normal file
@@ -0,0 +1,302 @@
|
|||||||
|
---
|
||||||
|
layout: blog_post
|
||||||
|
title: Converting an Ionic/Angular Site into a Progressive Web App
|
||||||
|
slug: Converting-Ionic-Angular-Site-into-PWA
|
||||||
|
date: 2020-12-01 00:01:00
|
||||||
|
permalink: /blog/2020/12/01/Converting-Ionic-Angular-Site-into-PWA/
|
||||||
|
tags: blog
|
||||||
|
blogtags:
|
||||||
|
- javascript
|
||||||
|
- webdev
|
||||||
|
- tutorial
|
||||||
|
---
|
||||||
|
|
||||||
|
For the past year, I've been working on a web application called [Noded](https://code.garrettmills.dev/Noded). Noded is built in Angular on the Ionic framework and provides tools for building a personal tree of information. (If you're curious, you can try it out [here](https://noded.garrettmills.dev/).)
|
||||||
|
|
||||||
|
<center>
|
||||||
|
<img src="https://static.garrettmills.dev/assets/blog-images/pwa-1.png">
|
||||||
|
<small>A screenshot from Noded.</small>
|
||||||
|
</center>
|
||||||
|
|
||||||
|
Because Noded is meant to replace whatever note-taking application a person uses, it's important that it be available offline (on your phone, for instance). So, one of the goals for Noded was to make it work as a progressive web app so it could be loaded even when the client doesn't have Internet access.
|
||||||
|
|
||||||
|
For the uninitiated, a progressive web app (or PWA) is a type of web app that can make use of native-integration features like push notifications, storage, &c. On mobile platforms, this also enables [the "Add to Home Screen" functionality](https://developer.mozilla.org/en-US/docs/Web/Progressive_web_apps/Add_to_home_screen) which enables users to "install" a PWA to their device so it appears as a native application and opens in full-screen mode, rather than in a browser.
|
||||||
|
|
||||||
|
<center>
|
||||||
|
<img src="https://static.garrettmills.dev/assets/blog-images/pwa-2.png" style="max-height: 300px">
|
||||||
|
<br>
|
||||||
|
<small>Noded, running as a PWA on my phone.</small>
|
||||||
|
</center>
|
||||||
|
|
||||||
|
## Service Workers
|
||||||
|
|
||||||
|
In order for a web app to become a PWA, it needs two things. First, it needs a [web manifest](https://developer.mozilla.org/en-US/docs/Web/Manifest), which tells the browser the location of all resources used by the web app, and other information like the icon and background color. Second, it needs to have a service worker registered. [Service workers](https://developer.mozilla.org/en-US/docs/Web/API/Service_Worker_API) are event-based JavaScript programs that run in the background on a user's browser.
|
||||||
|
|
||||||
|
These background programs can run even when the app itself isn't open and enable things like offline mode and push notifications. Ever wonder how applications like Google Docs can still load even when the browser is offline? This is enabled by the service worker API.
|
||||||
|
|
||||||
|
Your application's service worker sits like a layer between your application and its back-end server. When your app makes a request to the server, it is intercepted by the service worker which decides whether it will be forwarded to the back-end, or retrieved from the local cache.
|
||||||
|
|
||||||
|
PWAs work offline by having the service worker cache all of their app resources offline automatically. Then, when the back-end server is unreachable, the resources are served from the service worker transparently to the application. Even when your app is online, service workers can dramatically speed up load times for people with slow or latent connections (especially those in developing areas).
|
||||||
|
|
||||||
|
## Angular Service Worker
|
||||||
|
|
||||||
|
Because of their structured nature, Angular apps can make use of the [Angular Service Worker](https://angular.io/guide/service-worker-intro) which can automatically integrate with Angular apps to cache the built modules offline. This can be much easier to configure than writing a service-worker from scratch.
|
||||||
|
|
||||||
|
We'll start by adding the `@angular/pwa` package to our app, which will automatically bootstrap the manifest and service worker config:
|
||||||
|
|
||||||
|
```shell
|
||||||
|
ng add @angular/pwa --project app
|
||||||
|
```
|
||||||
|
|
||||||
|
(Where `app` is the name of your Angular project in `angular.json`.) This will create the `ngsw-config.json` config file, as well as the manifest in `src/manifest.webmanifest`.
|
||||||
|
|
||||||
|
### `ngsw-config.json`
|
||||||
|
|
||||||
|
The Angular service worker can be configured through the `ngsw-config.json` file. By modifying this file, we can tell the service-worker for our app to automatically pre-fetch all assets for the application. That way, when the app goes offline, it can still load the front-end resources.
|
||||||
|
|
||||||
|
**Note** that the service-worker will cache other XHR headers with the proper cache headers, but if your application relies on API requests to start, you should account for that in the app's code using things like [IndexedDB](https://developer.mozilla.org/en-US/docs/Web/API/IndexedDB_API) or [localStorage](https://developer.mozilla.org/en-US/docs/Web/API/Window/localStorage).
|
||||||
|
|
||||||
|
```json
|
||||||
|
{
|
||||||
|
"$schema": "./node_modules/@angular/service-worker/config/schema.json",
|
||||||
|
"index": "/index.html",
|
||||||
|
"assetGroups": [
|
||||||
|
{
|
||||||
|
"name": "app",
|
||||||
|
"installMode": "prefetch",
|
||||||
|
"resources": {
|
||||||
|
"files": [
|
||||||
|
"/favicon.ico",
|
||||||
|
"/index.html",
|
||||||
|
"/manifest.webmanifest",
|
||||||
|
"/*.css",
|
||||||
|
"/*.js"
|
||||||
|
]
|
||||||
|
}
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"name": "assets",
|
||||||
|
"installMode": "prefetch",
|
||||||
|
"updateMode": "prefetch",
|
||||||
|
"resources": {
|
||||||
|
"files": [
|
||||||
|
"/assets/**",
|
||||||
|
"/*.(eot|svg|cur|jpg|png|webp|gif|otf|ttf|woff|woff2|ani)"
|
||||||
|
]
|
||||||
|
}
|
||||||
|
}
|
||||||
|
]
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
Here's a sample config file. The `index` key specifies the entry-point to your application. For most Angular apps, this will be `index.html` since that's the file first loaded.
|
||||||
|
|
||||||
|
Then, the front-end assets are split into two groups. The `app` group matches any _built_ files that are necessary to boot the Angular app. The `assets` group matches any additional assets like images, fonts, and external files.
|
||||||
|
|
||||||
|
In this example, I've set both groups to `prefetch`, which means that the service-worker will try to cache them in the background the first time the app is loaded. This ensures that they are always available offline, as long as they had time to load once. However, it can be more taxing for the first load.
|
||||||
|
|
||||||
|
To avoid this, you can set an asset group to `installMode: lazy`. This will cache the resources offline only once the front-end tries to load them.
|
||||||
|
|
||||||
|
### Web Manifest
|
||||||
|
|
||||||
|
The `@angular/pwa` package will also generate a web manifest for your application in `src/manifest.webmanifest`. Here, you can customize things like your application's name, background colors, and icons:
|
||||||
|
|
||||||
|
```json
|
||||||
|
{
|
||||||
|
"name": "Noded",
|
||||||
|
"short_name": "Noded",
|
||||||
|
"theme_color": "#3A86FF",
|
||||||
|
"background_color": "#fafafa",
|
||||||
|
"display": "standalone",
|
||||||
|
"scope": "./",
|
||||||
|
"start_url": "./index.html",
|
||||||
|
"icons": [
|
||||||
|
{
|
||||||
|
"src": "assets/icons/icon-72x72.png",
|
||||||
|
"sizes": "72x72",
|
||||||
|
"type": "image/png",
|
||||||
|
"purpose": "maskable any"
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"src": "assets/icons/icon-96x96.png",
|
||||||
|
"sizes": "96x96",
|
||||||
|
"type": "image/png",
|
||||||
|
"purpose": "maskable any"
|
||||||
|
},
|
||||||
|
...
|
||||||
|
```
|
||||||
|
|
||||||
|
Angular will auto-generate PWA icons in the `assets/icons/` directory, so you'll want to customize those to match your app. These icons will become the home-screen icon for you app when a user installs it.
|
||||||
|
|
||||||
|
<center>
|
||||||
|
<img src="https://static.garrettmills.dev/assets/blog-images/pwa-3.png">
|
||||||
|
<br>
|
||||||
|
<small>Noded's PWA icon when added to my home screen.</small>
|
||||||
|
</center>
|
||||||
|
|
||||||
|
A few other notes about the web manifest:
|
||||||
|
|
||||||
|
- The `scope` property defines the scope of pages in the web app that can be navigated to in the "app mode." If your app tries to load a route that's outside of the scope, the client will revert to a web-browser rather than immersive mode.
|
||||||
|
- This property is relative to the entry point of the application. So, if the entry point is `/index.html`, then the scope `./*` matches all routes `/**`.
|
||||||
|
- The `start_url` is the route that is loaded when the user launches the PWA. Usually, this should match the entry point in the `ngsw-config.json` file as `index.html`.
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
### Building your application
|
||||||
|
|
||||||
|
Now that we've set up the Angular service-worker, you should be able to build your app and have it appear as a PWA in the browser. You can do this as you normally would. Since [Noded](https://code.garrettmills.dev/Noded/frontend/src/branch/master/.drone.yml#L21) is an Ionic app, I'll use:
|
||||||
|
|
||||||
|
```shell
|
||||||
|
./node_modules/.bin/ionic build --prod
|
||||||
|
```
|
||||||
|
|
||||||
|
Using the `ngsw-config.json`, this will generate a few new files. If you look at `www/ngsw.json`, you can see the compiled config for the service-worker telling it the locations of all generated files for your app:
|
||||||
|
|
||||||
|
```json
|
||||||
|
{
|
||||||
|
"configVersion": 1,
|
||||||
|
"timestamp": 1606842506052,
|
||||||
|
"index": "/index.html",
|
||||||
|
"assetGroups": [
|
||||||
|
{
|
||||||
|
"name": "app",
|
||||||
|
"installMode": "prefetch",
|
||||||
|
"updateMode": "prefetch",
|
||||||
|
"cacheQueryOptions": {
|
||||||
|
"ignoreVary": true
|
||||||
|
},
|
||||||
|
"urls": [
|
||||||
|
"/10-es2015.8900b72b6fdc6cff9bda.js",
|
||||||
|
"/10-es5.8900b72b6fdc6cff9bda.js",
|
||||||
|
"/11-es2015.82443d43d1a7c061f365.js",
|
||||||
|
"/11-es5.82443d43d1a7c061f365.js",
|
||||||
|
"/12-es2015.617954d1af39ce4dad1f.js",
|
||||||
|
"/12-es5.617954d1af39ce4dad1f.js",
|
||||||
|
"/13-es2015.eb9fce554868e6bda6be.js",
|
||||||
|
...
|
||||||
|
```
|
||||||
|
|
||||||
|
This is how the service-worker knows what to fetch and cache when running your application. It also writes the `ngsw-worker.js` file, which is the actual service worker code that gets run by the browser in the background. The web manifest is also included in the build.
|
||||||
|
|
||||||
|
Once you deploy your app and load it in the browser, it should now appear to have both a web manifest and a service worker:
|
||||||
|
|
||||||
|
<center>
|
||||||
|
<img src="https://static.garrettmills.dev/assets/blog-images/pwa-4.png">
|
||||||
|
<br>
|
||||||
|
<small>You can view this on the "Application" tab of your browser's dev-tools.</small>
|
||||||
|
<br><br>
|
||||||
|
<img src="https://static.garrettmills.dev/assets/blog-images/pwa-5.png">
|
||||||
|
</center>
|
||||||
|
|
||||||
|
**Note** that the service worker will only register and run if it is configured properly _and_ your application is served over HTTPS.
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
### Running in a sub-route (`/app`, &c.)
|
||||||
|
|
||||||
|
You may have noticed in the screen-shot above that the service-worker for Noded is registered for `noded.garrettmills.dev/i`. This is because the Angular app for Noded runs in the `/i` sub-route of the domain. This requires special consideration for the service-worker.
|
||||||
|
|
||||||
|
Recall that the manifest has a `scope` and `start_url`, and the `ngsw.json` has an `index` key. These are relative to the root of the domain, not the application. So, in order to serve our Angular app from a sub-route, we need to modify the PWA configs. Luckily, the Angular service-worker has a CLI tool that makes this easy for us. After we build our application, we can use the `ngsw-config` command to re-generate the config to use a sub-route:
|
||||||
|
|
||||||
|
```shell
|
||||||
|
./node_modules/.bin/ngsw-config ./www/ ./ngsw-config.json /i
|
||||||
|
```
|
||||||
|
|
||||||
|
The last argument is the sub-route where your application lives. In my case, that's `/i`. This command will modify the service-worker config to use the sub-route for all resources:
|
||||||
|
|
||||||
|
```json
|
||||||
|
{
|
||||||
|
"configVersion": 1,
|
||||||
|
"timestamp": 1606843244002,
|
||||||
|
"index": "/i/index.html",
|
||||||
|
"assetGroups": [
|
||||||
|
{
|
||||||
|
"name": "app",
|
||||||
|
"installMode": "prefetch",
|
||||||
|
"updateMode": "prefetch",
|
||||||
|
"cacheQueryOptions": {
|
||||||
|
"ignoreVary": true
|
||||||
|
},
|
||||||
|
"urls": [
|
||||||
|
"/i/10-es2015.8900b72b6fdc6cff9bda.js",
|
||||||
|
"/i/10-es5.8900b72b6fdc6cff9bda.js",
|
||||||
|
"/i/11-es2015.82443d43d1a7c061f365.js",
|
||||||
|
"/i/11-es5.82443d43d1a7c061f365.js",
|
||||||
|
"/i/12-es2015.617954d1af39ce4dad1f.js",
|
||||||
|
"/i/12-es5.617954d1af39ce4dad1f.js",
|
||||||
|
...
|
||||||
|
```
|
||||||
|
|
||||||
|
This ensures that your service worker caches the correct files. (**Note** that this doesn't actually need to modify the web manifest.)
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
## Debugging
|
||||||
|
|
||||||
|
Once you've deployed your built app, it should start caching assets through the service-worker. However, if this doesn't happen, here are a few things to consider.
|
||||||
|
|
||||||
|
### Don't modify the compiled Angular code
|
||||||
|
|
||||||
|
Once your app has been compiled to the `www/` directory, _never_ modify these files. If you need to make changes, use substitutions in the `angular.json`, or just change the original source files.
|
||||||
|
|
||||||
|
```json
|
||||||
|
"hashTable": {
|
||||||
|
"/i/10-es2015.8900b72b6fdc6cff9bda.js": "d3cf604bab1f99df8bcf86d7a142a3a047c66dd2",
|
||||||
|
"/i/10-es5.8900b72b6fdc6cff9bda.js": "8fcf65ea8740ae0364cd7371dd478e05eadb8b35",
|
||||||
|
"/i/11-es2015.82443d43d1a7c061f365.js": "bc50afb2730b9662fc37a51ae665fd30a9b0637c",
|
||||||
|
"/i/11-es5.82443d43d1a7c061f365.js": "300d5e62ec8ed5a744ac0dc1c2d627d6208499d7",
|
||||||
|
"/i/12-es2015.617954d1af39ce4dad1f.js": "465dd6ae6336dee028f3c2127358eea1d914879d",
|
||||||
|
"/i/12-es5.617954d1af39ce4dad1f.js": "5549d758aea47ab6d81a45d932993a6da9f5289c",
|
||||||
|
"/i/13-es2015.eb9fce554868e6bda6be.js": "2ca9cc161ae45c0a978b8bebce3f6dd7597bba07",
|
||||||
|
"/i/13-es5.eb9fce554868e6bda6be.js": "1dadc7f0083a1d499ea80f9c56d9ad62de96c4f3",
|
||||||
|
...
|
||||||
|
```
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
The reason for this is because the Angular service-worker generates hashes of the generated files and checks them on download. This is how it knows whether it has cached the latest version of the file or not. If you manually modify the compiled file, the hash won't match, and the service-worker will invalidate its entire cache.
|
||||||
|
|
||||||
|
### Bypass the service-worker
|
||||||
|
|
||||||
|
As mentioned above, the service-worker will attempt to cache other outbound requests, provided that the server responds with appropriate cache headers. However, there may be instances where you want to prevent this behavior (for example, when checking if the app is online and can access the server). To do this, you can add the `?ngsw-bypass` query parameter to the URLs of your requests.
|
||||||
|
|
||||||
|
Example: `/api/v1/stat?ngsw-bypass`.
|
||||||
|
|
||||||
|
### View service-worker logs
|
||||||
|
|
||||||
|
If you are having issues with the service worker's cache, it can be difficult to narrow them down without logs. You can view debugging output from the Angular service-worker by navigating to the `/ngsw/state` route in your app. In my case, that's `https://noded.garrettmills.dev/i/ngsw/state`.
|
||||||
|
|
||||||
|
```
|
||||||
|
NGSW Debug Info:
|
||||||
|
|
||||||
|
Driver state: NORMAL ((nominal))
|
||||||
|
Latest manifest hash: none
|
||||||
|
Last update check: never
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
=== Idle Task Queue ===
|
||||||
|
Last update tick: never
|
||||||
|
Last update run: never
|
||||||
|
Task queue:
|
||||||
|
|
||||||
|
|
||||||
|
Debug log:
|
||||||
|
```
|
||||||
|
|
||||||
|
If you are having issues, the `Debug log` section can provide more info on cache invalidation and other issues.
|
||||||
|
|
||||||
|
### View cached files
|
||||||
|
|
||||||
|
You can view the status of cached files in the "Storage" section of your browser's dev tools. This can help you see if the service worker was unable to find files (invalid route configurations), or was invalidating cached files.
|
||||||
|
|
||||||
|
<center>
|
||||||
|
<img src="https://static.garrettmills.dev/assets/blog-images/pwa-6.png">
|
||||||
|
<br><small>Files cached locally by Noded's service worker.</small>
|
||||||
|
</center>
|
||||||
|
|
||||||
|
## Conclusion
|
||||||
|
|
||||||
|
This was a cursory look at getting your Angular/Ionic app set up as a PWA and caching assets offline using Angular service-workers. If your app relies on back-end resources (like an API), you'll still need to account for that when adding offline support using tools like IndexedDB and localStorage.
|
||||||
|
|
||||||
|
For example, Noded has an [API service](https://code.garrettmills.dev/Noded/frontend/src/branch/master/src/app/service/api.service.ts) that sits between the app and the server and caches API resources locally in the IndexedDB. Perhaps we'll look into this more in a future post.
|
||||||
398
src/blog/posts/2021-03-30-di-typescript.md
Normal file
398
src/blog/posts/2021-03-30-di-typescript.md
Normal file
@@ -0,0 +1,398 @@
|
|||||||
|
---
|
||||||
|
layout: blog_post
|
||||||
|
title: Rethinking Dependency-Injection in TypeScript
|
||||||
|
slug: Rethinking-Dependency-Injection-in-TypeScript
|
||||||
|
date: 2021-03-30 00:01:00
|
||||||
|
tags: blog
|
||||||
|
permalink: /blog/2021/03/30/Rethinking-Dependency-Injection-in-TypeScript/
|
||||||
|
blogtags:
|
||||||
|
- DI
|
||||||
|
- javascript
|
||||||
|
- flitter
|
||||||
|
- extollo
|
||||||
|
---
|
||||||
|
|
||||||
|
<center>
|
||||||
|
<img src="https://static.garrettmills.dev/assets/blog-images/ts_di_header.png">
|
||||||
|
<br><small>A snippet from @extollo/di's Inject decorator.</small>
|
||||||
|
</center>
|
||||||
|
|
||||||
|
Anyone who has read this blog before knows that I have a particular interest in dependency injection and inversion-of-control paradigms.
|
||||||
|
|
||||||
|
Over the last few years, I've implemented DI in JavaScript for various projects, and I'm currently in the process of rewriting my framework and its DI implementation, so I wanted to share some observations about different JavaScript/TypeScript DI strategies.
|
||||||
|
|
||||||
|
In particular, we'll explore named-injection, constructor-injection, and property-injection.
|
||||||
|
|
||||||
|
## Named Injection
|
||||||
|
|
||||||
|
My [first foray into DI in JavaScript](/blog/2019/11/16/Dependency-Injection-in-Less-Than-100-Lines-of-Pure-JavaScript/) relied on purely-runtime code and allowed injecting services from a container by name:
|
||||||
|
|
||||||
|
```javascript
|
||||||
|
const Injectable = require('./Injectable')
|
||||||
|
|
||||||
|
class SomeInjectableClass extends Injectable {
|
||||||
|
static services = ['logging']
|
||||||
|
|
||||||
|
myMethod() {
|
||||||
|
this.logging.info('myMethod called!')
|
||||||
|
}
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
This was a fairly efficient and scalable paradigm, and defining the services as a property on the class itself made it easy to account for the services required by parent classes:
|
||||||
|
|
||||||
|
```javascript
|
||||||
|
// ...
|
||||||
|
class AnotherInjectableClass extends SomeInjectableClass {
|
||||||
|
static get services() {
|
||||||
|
return [...super.services, 'another_service']
|
||||||
|
}
|
||||||
|
|
||||||
|
myMethod() {
|
||||||
|
this.another_service.something()
|
||||||
|
super.myMethod()
|
||||||
|
}
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
In fact, this mechanism was reliable enough that it became the basis of the injector used in my [Flitter framework](https://code.garrettmills.dev/Flitter/di).
|
||||||
|
|
||||||
|
### Drawbacks
|
||||||
|
|
||||||
|
This method is not without its downsides, however. For one, all classes must extend a common `Injectable` base class. If your class extends from, say, a base class from a library, then it can't be injected directly.
|
||||||
|
|
||||||
|
Likewise, relying on service names makes it hard to know exactly what's being injected into your class. Especially as I am transitioning more projects and my framework over to TypeScript, relying on named-injection just wasn't going to cut it. This would require referencing properties with the `any` type annotation:
|
||||||
|
|
||||||
|
```typescript
|
||||||
|
class SomeInjectableClass extends Injectable {
|
||||||
|
static get services(): string[] {
|
||||||
|
return [...super.services, 'another_service']
|
||||||
|
}
|
||||||
|
|
||||||
|
myMethod(): void {
|
||||||
|
(this as any).another_service.something() // NOT type safe
|
||||||
|
}
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
Relying on named services also makes the injectable classes inflexible, as the services have to be injected into properties with the same name. Say, for example, I have a service called `models`, and a class that uses it. If that class wants to keep an array called `models`, it will conflict with the injected service:
|
||||||
|
|
||||||
|
```typescript
|
||||||
|
class SomethingThatUsesModels extends Injectable {
|
||||||
|
static get services() {
|
||||||
|
return [...super.services, 'models']
|
||||||
|
}
|
||||||
|
|
||||||
|
// CONFLICT with the injected 'models' service
|
||||||
|
protected models: Model[] = []
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
Because a named-injector would have to bypass type-safety, this could lead to a situation where the TypeScript compiler types `models` as `Model[]`, but the injector overrides it to be the injected `models` service, which would cause runtime errors.
|
||||||
|
|
||||||
|
## Constructor Injection
|
||||||
|
|
||||||
|
Since we're working in TypeScript, we want to do away with named-injection entirely. The TypeScript compiler has a flag which, when enabled, emits the type metadata for classes and properties, making it available via the Reflection API.
|
||||||
|
|
||||||
|
This is useful because it effectively enables "naming" a dependency based on its type, rather than an arbitrary string. So, when defining typed injectable classes, each property contains _two_ pieces of information, rather than just one.
|
||||||
|
|
||||||
|
Likewise, we can enable the experimental "decorators" functionality, which can allow us inject any arbitrary class rather than requiring it to extend a base `Injectable` class. For example:
|
||||||
|
|
||||||
|
```typescript
|
||||||
|
@Injectable()
|
||||||
|
class SomethingThatUsesModels {
|
||||||
|
protected models: Model[] = []
|
||||||
|
|
||||||
|
constructor(
|
||||||
|
protected readonly modelsService: ModelsService,
|
||||||
|
) { }
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
Anyone who has used the Angular framework is familiar with this format. The Angular DI historically worked this way, using type reflection to handle injection. Nowadays, it uses its custom compiler to handle injection at compile time, but that's beyond the scope of this writeup.
|
||||||
|
|
||||||
|
### How does this work?
|
||||||
|
|
||||||
|
Okay, so we have a decorator and some type annotations. But, how do we actually do the injection from that?
|
||||||
|
|
||||||
|
The key is that `Injectable` decorator. In essence, this decorator is a function that accepts the class it decorates. Then, this function uses the `reflect-metadata` package to get a list of type annotations for the constructor's parameters, then stores that information as additional metadata.
|
||||||
|
|
||||||
|
Here's a (simplified) example from the [Extollo DI](https://code.garrettmills.dev/extollo/lib/src/branch/master/src/di/decorator/injection.ts) (Flitter's TypeScript successor):
|
||||||
|
|
||||||
|
```typescript
|
||||||
|
/**
|
||||||
|
* Get a collection of dependency requirements for the given target object.
|
||||||
|
* @param {Object} target
|
||||||
|
* @return Collection<DependencyRequirement>
|
||||||
|
*/
|
||||||
|
function initDependencyMetadata(target: Object): Collection<DependencyRequirement> {
|
||||||
|
const paramTypes = Reflect.getMetadata('design:paramtypes', target)
|
||||||
|
return collect<DependencyKey>(paramTypes).map<DependencyRequirement>((type, idx) => {
|
||||||
|
return {
|
||||||
|
paramIndex: idx,
|
||||||
|
key: type,
|
||||||
|
overridden: false,
|
||||||
|
}
|
||||||
|
})
|
||||||
|
}
|
||||||
|
|
||||||
|
/**
|
||||||
|
* Class decorator that marks a class as injectable. When this is applied, dependency
|
||||||
|
* metadata for the constructors params is resolved and stored in metadata.
|
||||||
|
* @constructor
|
||||||
|
*/
|
||||||
|
export const Injectable = (): ClassDecorator => {
|
||||||
|
return (target) => {
|
||||||
|
const meta = initDependencyMetadata(target)
|
||||||
|
Reflect.defineMetadata(DEPENDENCY_KEYS_METADATA_KEY, meta, target)
|
||||||
|
}
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
In essence, all this decorator does is read the type annotations from the class' meta-data and store them in a nicer format in its own meta-data key (`DEPENDENCY_KEYS_METADATA_KEY`).
|
||||||
|
|
||||||
|
#### Instantiating the Class
|
||||||
|
|
||||||
|
Okay, so we have the type annotations stored in meta-data, but how do we actually inject them into the class? This is where the container comes in.
|
||||||
|
|
||||||
|
In our old paradigm, the container was a class that mapped service names (`another_service`) to factories that created the service with that name. (e.g. `another_service` to `instanceof AnotherService`). In the type-based system, the container is a class that maps _types_ to factories that create the service with that type.
|
||||||
|
|
||||||
|
This result is very strong as it enables type-safe injection. In the example above, the "token", `ModelsService` is mapped to an instance of the `ModelsService` by the container.
|
||||||
|
|
||||||
|
So, when we ask the container to inject and create an instance of our `SomethingThatUsesModels` class, the container goes through all the items in the `DEPENDENCY_KEYS_METADATA_KEY` meta-data key and resolves them. Then, it passes those instances into the new class to instantiate it. For a (simplified) example:
|
||||||
|
|
||||||
|
```typescript
|
||||||
|
class Container {
|
||||||
|
resolveAndCreate<T>(token: Instantiable<T>): T {
|
||||||
|
const dependencies = Reflect.getMetadata(DEPENDENCY_KEYS_METADATA_KEY)
|
||||||
|
const params = dependencies.orderByAsc('paramIndex')
|
||||||
|
.map(dependency => this.resolveAndCreate(dependency.key))
|
||||||
|
|
||||||
|
return new token(...params)
|
||||||
|
}
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
So, we can instantiate our `SomethingThatUsesModels` class like so:
|
||||||
|
|
||||||
|
```typescript
|
||||||
|
const inst = <SomethingThatUsesModels> container.resolveAndCreate(SomethingThatUsesModels)
|
||||||
|
```
|
||||||
|
|
||||||
|
### Drawbacks
|
||||||
|
|
||||||
|
The constructor-injection paradigm works well and addresses many of the features we cared about between named-injection. In particular:
|
||||||
|
|
||||||
|
- Provides type-hinted injection
|
||||||
|
- Separates class property names from injection tokens
|
||||||
|
|
||||||
|
However, one way this falls behind named-injection is in the sense that the child classes must know and provide the dependencies of their parents.
|
||||||
|
|
||||||
|
For example, assume I have a class:
|
||||||
|
|
||||||
|
```typescript
|
||||||
|
@Injectable()
|
||||||
|
class ParentClass {
|
||||||
|
constructor(
|
||||||
|
protected logging: LoggingService
|
||||||
|
) { }
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
Now, I want to define a child of this class that has its own dependencies:
|
||||||
|
|
||||||
|
```typescript
|
||||||
|
@Injectable()
|
||||||
|
class ChildClass extends ParentClass {
|
||||||
|
constructor(
|
||||||
|
protected another: AnotherService,
|
||||||
|
) { super() } // ERROR!
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
This will immediately fail to compile, since the `ChildClass` doesn't pass the required dependencies into the parent. In reality, the child class must *also* specify the dependencies of the parent as parameters in its constructor:
|
||||||
|
|
||||||
|
```typescript
|
||||||
|
@Injectable()
|
||||||
|
class ChildClass extends ParentClass {
|
||||||
|
constructor(
|
||||||
|
protected another: AnotherService,
|
||||||
|
logging: LoggingService,
|
||||||
|
) { super(logging) }
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
The issue with this becomes immediately obvious. All of the dependencies and imports of the parent must also be specified in *all* of the children. As the classes become larger and the inheritance chain becomes longer, you can quickly run into ridiculously long constructor signatures:
|
||||||
|
|
||||||
|
```typescript
|
||||||
|
@Injectable()
|
||||||
|
class LargerControllerClass extends ParentControllerClass {
|
||||||
|
constructor(
|
||||||
|
protected logging: LoggingService,
|
||||||
|
protected config: ConfigService,
|
||||||
|
protected models: ModelsService,
|
||||||
|
socket: SocketService,
|
||||||
|
renderer: ViewRenderer,
|
||||||
|
other: OtherService,
|
||||||
|
another: AnotherService,
|
||||||
|
more: MoreService,
|
||||||
|
) { super(socket, renderer, other, another, more) }
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
Here, not only does the child need to be aware of the dependencies of the parent, it needs to take into account the order of the constructor parameters, which might be irrelevant in practice, but could break between versions.
|
||||||
|
|
||||||
|
## Property Injection
|
||||||
|
|
||||||
|
To improve upon this, we want to divorce the injected dependencies from the constructor while still maintaining the type-hinted and property-name benefits we gained from constructor-injection
|
||||||
|
|
||||||
|
This has the additional benefit of keeping the constructor signatures smaller, and keeping the non-injected constructor parameters distinct from the injected ones.
|
||||||
|
|
||||||
|
Luckily, in TypeScript, properties of a class also emit type annotations, and can be decorated. So, we can change our
|
||||||
|
|
||||||
|
`ParentClass` and `ChildClass` definitions to look as follows:
|
||||||
|
|
||||||
|
```typescript
|
||||||
|
@Injectable()
|
||||||
|
class ParentClass {
|
||||||
|
@Inject()
|
||||||
|
protected readonly logging!: LoggingService
|
||||||
|
}
|
||||||
|
|
||||||
|
@Injectable()
|
||||||
|
class ChildClass extends ParentClass {
|
||||||
|
@Inject()
|
||||||
|
protected readonly another!: AnotherService
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
### How does this work?
|
||||||
|
|
||||||
|
The "magic" bit here is the `@Inject()` decorator, which looks at the type annotation of the property it decorates and stores that property and its token value as meta-data on the class. Here's a simplified example of Extollo's [implementation](https://code.garrettmills.dev/extollo/lib/src/branch/master/src/di/decorator/injection.ts#L69):
|
||||||
|
|
||||||
|
```typescript
|
||||||
|
/**
|
||||||
|
* Mark the given class property to be injected by the container.
|
||||||
|
* @constructor
|
||||||
|
*/
|
||||||
|
export const Inject = (): PropertyDecorator => {
|
||||||
|
return (target, property) => {
|
||||||
|
const propertyMetadata = new Collection<PropertyDependency>()
|
||||||
|
Reflect.defineMetadata(DEPENDENCY_KEYS_PROPERTY_METADATA_KEY, propertyMetadata, target)
|
||||||
|
|
||||||
|
const type = Reflect.getMetadata('design:type', target, property)
|
||||||
|
if ( type ) {
|
||||||
|
const existing = propertyMetadata.firstWhere('property', '=', property)
|
||||||
|
if ( existing ) {
|
||||||
|
existing.key = key
|
||||||
|
} else {
|
||||||
|
propertyMetadata.push({ property, key })
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
Reflect.defineMetadata(DEPENDENCY_KEYS_PROPERTY_METADATA_KEY, propertyMetadata, target)
|
||||||
|
}
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
Now, when the container creates an instance of a class, instead of passing in the dependencies as parameters to the constructor, it instantiates the class, then sets the properties on the class that have `@Inject()` decorators. For example:
|
||||||
|
|
||||||
|
```typescript
|
||||||
|
class Container {
|
||||||
|
resolveAndCreate<T>(token: Instantiable<T>): T {
|
||||||
|
const inst = new token()
|
||||||
|
const dependencies = Reflect.getMetadata(DEPENDENCY_KEYS_PROPERTY_METADATA_KEY, token)
|
||||||
|
const instances = dependencies.map(x => {
|
||||||
|
inst[x.property] = this.resolveAndCreate(x.key)
|
||||||
|
})
|
||||||
|
|
||||||
|
return inst
|
||||||
|
}
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
There's a problem here, though. Say we were to `resolveAndCreate<ChildClass>(ChildClass)`. Because of the way JavaScript works, the instance returned by this call would ONLY have the properties defined in the child class, not the parent (i.e. `another`, but not `logging`).
|
||||||
|
|
||||||
|
To understand why, we need a bit of background.
|
||||||
|
|
||||||
|
#### The Prototype Chain
|
||||||
|
|
||||||
|
In JavaScript, inheritance is prototypical. Say we have the following:
|
||||||
|
|
||||||
|
```typescript
|
||||||
|
const parent = new ParentClass(...)
|
||||||
|
const child = new ChildClass(...)
|
||||||
|
```
|
||||||
|
|
||||||
|
The object created as `parent` has a "chain" of prototypes that comprise it. So, if I try to access a method or property on `parent`, JavaScript will first check if the property exists on `parent` itself. If not, it will check if the property exists on `ParentClass.prototype`, then `ParentClass.prototype.prototype`, and so on.
|
||||||
|
|
||||||
|
If you follow the prototype chain long enough, every item in JavaScript eventually extends from `Object.prototype` or `Function.prototype`. (For classes, it's the latter.) From any of these prototypes, we can access the constructor they are associated with using `Class.prototype.constructor`.
|
||||||
|
|
||||||
|
So, to get the `ParentClass` constructor from its prototype, we could do `ParentClass.prototype.constructor`.
|
||||||
|
|
||||||
|
#### The Issue
|
||||||
|
|
||||||
|
When our `@Inject()` decorator saves the meta-data about the property type annotations, it does so by defining a new meta-data property on the prototype of the class where the property was defined.
|
||||||
|
|
||||||
|
Since the `logging` property was first defined and decorated in the `ParentClass`, the meta-data property with the information we need is actually defined on `ParentClass.prototype`.
|
||||||
|
|
||||||
|
However, when `@Inject()` is called for the `another` property in the `ChildClass`, it *defines* a new meta-data key with `ChildClass`'s defined properties on the `ChildClass.prototype`.
|
||||||
|
|
||||||
|
Thus, in order to get all the properties we need to inject, we must check the meta-data defined for *all* prototypes in the inheritance chain of the constructor being instantiated. So, the container implementation might look something like:
|
||||||
|
|
||||||
|
```typescript
|
||||||
|
class Container {
|
||||||
|
resolveAndCreate<T>(token: Instantiable<T>): T {
|
||||||
|
const inst = new token()
|
||||||
|
const meta = new Collection<PropertyDependency>()
|
||||||
|
let currentToken = token
|
||||||
|
|
||||||
|
do {
|
||||||
|
const loadedMeta = Reflect.getMetadata(DEPENDENCY_KEYS_PROPERTY_METADATA_KEY, currentToken)
|
||||||
|
if ( loadedMeta ) meta.concat(loadedMeta)
|
||||||
|
currentToken = Object.getPrototypeOf(currentToken)
|
||||||
|
} while (
|
||||||
|
Object.getPrototypeOf(currentToken) !== Function.prototype
|
||||||
|
&& Object.getPrototypeOf(currentToken) !== Object.prototype
|
||||||
|
)
|
||||||
|
|
||||||
|
meta.map(x => {
|
||||||
|
inst[x.property] = this.resolveAndCreate(x.key)
|
||||||
|
})
|
||||||
|
|
||||||
|
return inst
|
||||||
|
}
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
Now, `inst` will have all properties defined as injected for all parent classes in the inheritance chain.
|
||||||
|
|
||||||
|
### Best of Both Worlds
|
||||||
|
|
||||||
|
This approach combines the benefits of named-injection with the type-safety of constructor-injection:
|
||||||
|
|
||||||
|
- Child classes don't need to account for the dependencies of their parents
|
||||||
|
- Injected dependencies can be type-hinted
|
||||||
|
- Property names of dependencies are independent of their types
|
||||||
|
- Parent dependencies are automatically accounted for
|
||||||
|
|
||||||
|
After using it for a while, I really like this paradigm. It provides a type-safe way to do dependency injection reliably, while still keeping the class definitions clean and parent-agnostic.
|
||||||
|
|
||||||
|
### Drawbacks
|
||||||
|
|
||||||
|
While its still my preferred solution, property-injection in TypeScript still isn't without its drawbacks. Namely, it requires use of the [non-null assertion operator](https://www.typescriptlang.org/docs/handbook/release-notes/typescript-2-0.html#non-null-assertion-operator) since the properties are being filled in by the container.
|
||||||
|
|
||||||
|
Because of this, if you were to instantiate a class manually outside the container and not fill in all the properties, the compiler wouldn't catch it. Accessing properties on that instance would lead to runtime errors. However, assuming you always instantiate `Injectable` classes with the container, this problem is largely mute.
|
||||||
|
|
||||||
|
Another downside that I didn't explore much in this article is the container code. Generalizing the container (for either constructor- or property-injection) requires use of the `any` operator _at some point_ since factories are matched by key. At least in my implementation. I'd be interested to see alternatives.
|
||||||
|
|
||||||
|
## Conclusion
|
||||||
|
|
||||||
|
There will, undoubtedly, be another iteration of this article wherein I discover a new paradigm I want to try. But for the foreseeable future, I'll be implementing and running with property-injection in my projects. As I mentioned in the article, constructor-injection and property-injection support form the basis of the dependency injector for the [Extollo framework](https://extollo.garrettmills.dev), my new project.
|
||||||
|
|
||||||
|
I tried not to dive too deep into the actual code required to implement the various strategies in this article, so if you're interested in seeing how I've implemented them for my projects, here are some links:
|
||||||
|
|
||||||
|
- [The Flitter DI](https://code.garrettmills.dev/flitter/di) (named-injection)
|
||||||
|
- [The Extollo DI](https://code.garrettmills.dev/extollo/lib/src/branch/master/src/di) (constructor- and property-injection, WIP)
|
||||||
|
|
||||||
|
As always, I'd love to hear any other strategies or ways people have implemented this, so feel free to leave a comment or [get in touch](https://garrettmills.dev/#contact).
|
||||||
27
src/blog/posts/2021-08-25-self-portrait.md
Normal file
27
src/blog/posts/2021-08-25-self-portrait.md
Normal file
@@ -0,0 +1,27 @@
|
|||||||
|
---
|
||||||
|
layout: blog_post
|
||||||
|
title: "Photo Challenge 01: Self Portrait"
|
||||||
|
slug: Photo-Challenge-01-Self-Portrait
|
||||||
|
date: 2021-08-25 00:01:00
|
||||||
|
tags: blog
|
||||||
|
permalink: /blog/2021/08/25/Photo-Challenge-01-Self-Portrait/
|
||||||
|
blogtags:
|
||||||
|
- photo-challenge
|
||||||
|
- photography
|
||||||
|
---
|
||||||
|
|
||||||
|
I've decided to take up photography again as a creative outlet from my more... technical endeavors. This is something I've experimented with the past, and I really enjoyed it. If you're curious, some of my old photos are available [here](https://static.garrettmills.dev/assets/photos/).
|
||||||
|
|
||||||
|
As a starting point for inspiration, I'm going to be following this [30-day photography challenge](https://expertphotography.com/30-day-photography-challenge/), though I'm just going to be doing the challenges as I have time, rather than one-a-day.
|
||||||
|
|
||||||
|
The first challenge is to capture a self-portrait. This one was interesting because I wanted to find a shot that not only captured a literal self-portrait, but also captured something about myself (a metaphorical self-portrait, if you will).
|
||||||
|
|
||||||
|
I was a bit stumped on what to do for this, until I was sitting at my desk and noticed the annoying glare my reflection made in my monitor thanks to the light from the window. So, I decided to run with that, and I'm fairly pleased with the result:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
I had to play a bit with the color balance in editing. Getting my reflection to be defined enough to stand out strikingly on the monitor was a challenge. To help, I added a couple artificial lights off the right side of the frame to supplement the light coming from the window.
|
||||||
|
|
||||||
|
To get my reflection in focus, I had to resurrect the optics knowledge echoing from a physics class years ago. Recall that, in a perfect reflection, the angles of the light rays stay the same relative to each other through the mirror. In effect, the mirror can be modeled as a pane of glass with the image behind it. (That is, if a subject is 2 feet in front of the mirror, it can be modeled as if the subject were sitting 2 feet behind a pane of glass.)
|
||||||
|
|
||||||
|
So, to focus on my reflection, I rolled the focus out to focus a few feet _beyond_ the surface of the monitor.
|
||||||
229
src/blog/posts/2022-01-14-ts-runtime.md
Normal file
229
src/blog/posts/2022-01-14-ts-runtime.md
Normal file
@@ -0,0 +1,229 @@
|
|||||||
|
---
|
||||||
|
layout: blog_post
|
||||||
|
title: Runtime Data Validation from TypeScript Interfaces
|
||||||
|
slug: Runtime-Data-Validation-from-TypeScript-Interfaces
|
||||||
|
date: 2022-01-14 00:01:00
|
||||||
|
tags: blog
|
||||||
|
permalink: /blog/2022/01/14/Runtime-Data-Validation-from-TypeScript-Interfaces/
|
||||||
|
blogtags:
|
||||||
|
- javascript
|
||||||
|
- typscript
|
||||||
|
- extollo
|
||||||
|
---
|
||||||
|
|
||||||
|
For the last year or so, I've been (slowly) building a TypeScript-based Node.js framework called [Extollo](https://extollo.garrettmills.dev/). One of the design goals with Extollo is to only expose the user (i.e. the developer) to ES/TypeScript native concepts, in order to reduce the amount of special knowledge required to get up and running with the framework.
|
||||||
|
|
||||||
|
# Runtime schemata: a plague of DSLs
|
||||||
|
|
||||||
|
One of my biggest pet-peeves with the current Node.js framework scene is that nearly every ecosystem has to re-invent the wheel when it comes to schema definitions. Because JavaScript doesn't have a native runtime type-specification system (at least, not a good one), if you want to encode details about how a data structure should look at runtime, you need to design a system for passing that information along at runtime.
|
||||||
|
|
||||||
|
For example, a prolific MongoDB ODM for Node.js, Mongoose, gives users the ability to specify the schema of the records in the collection when the user defines a model. Here's a sample schema definition from the [Mongoose docs](https://mongoosejs.com/docs/guide.html#definition):
|
||||||
|
|
||||||
|
```js
|
||||||
|
import mongoose from 'mongoose';
|
||||||
|
const { Schema } = mongoose;
|
||||||
|
|
||||||
|
const blogSchema = new Schema({
|
||||||
|
title: String, // String is shorthand for {type: String}
|
||||||
|
author: String,
|
||||||
|
body: String,
|
||||||
|
comments: [{ body: String, date: Date }],
|
||||||
|
date: { type: Date, default: Date.now },
|
||||||
|
hidden: Boolean,
|
||||||
|
meta: {
|
||||||
|
votes: Number,
|
||||||
|
favs: Number
|
||||||
|
}
|
||||||
|
});
|
||||||
|
```
|
||||||
|
|
||||||
|
I'm currently building the request validation system for Extollo. Because it has to process web requests with dynamic input, the validator interfaces need to be specified at runtime so the data can be checked against the schema. To do this, I'm using the fantastic [Zod schema validator library](https://github.com/colinhacks/zod) written by Colin McDonnell.
|
||||||
|
|
||||||
|
However, Zod falls victim to the same fundamental problem with runtime schemata in JavaScript as Mongoose. Because its schemata need to be available at runtime, you have to use Zod's custom schema builder to define your interfaces. Here's an example of a schema for some data that might come from a login page:
|
||||||
|
|
||||||
|
```ts
|
||||||
|
import { z } from 'zod'
|
||||||
|
|
||||||
|
export const LoginAttemptSchema = z.object({
|
||||||
|
username: z.string().nonempty(),
|
||||||
|
password: z.string().nonempty(),
|
||||||
|
rememberMe: z.boolean().optional(),
|
||||||
|
})
|
||||||
|
```
|
||||||
|
|
||||||
|
That's not too bad, but it does require the developer to learn Zod's specific schema definition language. I find this especially annoying since TypeScript already _has_ an interface definition language! This is a situation where I'd like to avoid making the developer learn an equivalent system if they already know the one built into the language.
|
||||||
|
|
||||||
|
Let's rewrite this schema in TypeScript for a start:
|
||||||
|
|
||||||
|
```ts
|
||||||
|
export interface LoginAttempt {
|
||||||
|
/** @minLength 1 */
|
||||||
|
username: string
|
||||||
|
|
||||||
|
/** @minLength 1 */
|
||||||
|
password: string
|
||||||
|
|
||||||
|
rememberMe?: boolean
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
Okay, that's an improvement! We can use TypeScript's native type syntax to define the interface, and augment it with JSDoc comments for any properties that can't be natively expressed. So, to use this with Zod, we need to convert it from the TypeScript syntax to the Zod syntax. Luckily, Fabien Bernard has spearheaded the excellent [ts-to-zod project](https://github.com/fabien0102/ts-to-zod), which looks through interfaces defined in a file and outputs the equivalent Zod schemata for them.
|
||||||
|
|
||||||
|
Hmm.. so now the user can write their schema definitions in (mostly) native TypeScript syntax, and, with a bit of helper tooling, we can convert them to the Zod format so we can use them at runtime. Perfect! Well, almost...
|
||||||
|
|
||||||
|
We have a subtle problem that arises when we want to actually _use_ a schema at runtime. Let's look at an example:
|
||||||
|
|
||||||
|
```ts
|
||||||
|
import { Validator } from '@extollo/lib'
|
||||||
|
import { LoginAttempt } from '../types/LoginAttempt.ts'
|
||||||
|
|
||||||
|
class LoginController {
|
||||||
|
public function getValidator() {
|
||||||
|
return new Validator<LoginAttempt>()
|
||||||
|
}
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
This class has a method which returns a new Validator instance with the LoginAttempt schema as its type-parameter. Intuitively, this should produce a validator which, at runtime, validates data against the LoginAttempt schema. Let's look at the compiled JavaScript:
|
||||||
|
|
||||||
|
```js
|
||||||
|
"use strict";
|
||||||
|
Object.defineProperty(exports, "__esModule", { value: true });
|
||||||
|
const Validator_1 = require("@extollo/lib").Validator;
|
||||||
|
class LoginController {
|
||||||
|
getValidator() {
|
||||||
|
return new Validator_1.Validator();
|
||||||
|
}
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
Uh, oh. Ignoring the boilerplate noise, we see that our nice, type-parameterized Validator instance has been stripped of its type information. Why? TypeScript is a [transpiler](https://devopedia.org/transpiler). So, it takes TypeScript code and outputs the _equivalent_ JavaScript code. Because JavaScript has no concept of types at runtime, the transpiler (in this case, tsc) strips them out.
|
||||||
|
|
||||||
|
So now we have a problem. We've improved our user-interface by only requiring the developer to specify the TypeScript types, but now we can't _use_ them at runtime, because the TypeScript types get stripped away. 'What about the Zod schema we just generated?' you ask, wisely. Well, unfortunately, there's no mapping between the interface and the Zod schema it induced, and there's no easy way to create such a mapping, because it has to be done at compile-time.
|
||||||
|
|
||||||
|
# A very deep rabbit-hole
|
||||||
|
|
||||||
|
Ordinarily, this is where the story ends. You need some kind of mapping between the interface and the Zod schema (which, remember, the developer has no idea exists thanks to our ts-to-zod magic) to make the Validator work. In a generic TypeScript project, you'd have to have some kind of naming convention, or expose the schema to the user somehow to create the mapping.
|
||||||
|
|
||||||
|
However, Extollo has a unique advantage that I suspected could be used to solve this problem transparently: [excc](https://code.garrettmills.dev/extollo/cc). Extollo projects are primarily TypeScript projects, but they also contain other files like views, assets, &c. that need to be included in the built-out bundle. To standardize all of this, Extollo uses its own project-compiler called `excc` for builds. `excc` is primarily [a wrapper around tsc](https://code.garrettmills.dev/Extollo/cc/src/branch/master/src/phases/CompilePhase.ts#L20) that does some additional pre- and post-processing to handle the cases above.
|
||||||
|
|
||||||
|
Because Extollo projects are all using `excc`, this means that we can do arbitrary processing at compile time. I suspected that there would be a way to create a mapping between the interfaces and the schemata we generate for runtime.
|
||||||
|
|
||||||
|
## Zod-ifying the Interfaces
|
||||||
|
|
||||||
|
The first step was converting the TypeScript interfaces to Zod schemata using ts-to-zod. In `excc`, this is implemented as [a pre-processing step](https://code.garrettmills.dev/Extollo/cc/src/branch/master/src/phases/ZodifyPhase.ts#L30) that appends the Zod schema to the .ts file that contains the interface. So, the processed LoginAttempt.ts might look something like:
|
||||||
|
|
||||||
|
```ts
|
||||||
|
import { z } from "zod";
|
||||||
|
|
||||||
|
export interface LoginAttempt {
|
||||||
|
/** @minLength 1 */
|
||||||
|
username: string
|
||||||
|
|
||||||
|
/** @minLength 1 */
|
||||||
|
password: string
|
||||||
|
|
||||||
|
rememberMe?: boolean
|
||||||
|
}
|
||||||
|
|
||||||
|
export const exZodifiedSchema = z.object({
|
||||||
|
username: z.string().nonempty(),
|
||||||
|
password: z.string().nonempty(),
|
||||||
|
rememberMe: z.boolean().optional(),
|
||||||
|
});
|
||||||
|
```
|
||||||
|
|
||||||
|
This has some drawbacks. Namely, it assumes that only one interface is defined per-file. However, Extollo enforces this convention for other concepts like models, middleware, controllers, and config files, so it's fine to make that assumption here.
|
||||||
|
|
||||||
|
This gets us closer, but it still doesn't do the mapping for the runtime schema. The first step to this is going to be devising some way of referencing a schema so that we can easily modify the TypeScript code that uses its related interface.
|
||||||
|
|
||||||
|
I don't love the initial system I have for this, but what `excc` does now is generate a unique ID number for each interface it Zod-ifies. Then, when it is writing the Zod schema into the interface's file, it adds code to register it with [a global service](https://code.garrettmills.dev/extollo/lib/src/branch/master/src/validation/ZodifyRegistrar.ts) that maps the ID number to the Zod schema at runtime. So, the above file would actually look something like:
|
||||||
|
|
||||||
|
```ts
|
||||||
|
import { z } from "zod";
|
||||||
|
import { registerZodifiedSchema } from "@extollo/lib";
|
||||||
|
|
||||||
|
export interface LoginAttempt {
|
||||||
|
/** @minLength 1 */
|
||||||
|
username: string
|
||||||
|
|
||||||
|
/** @minLength 1 */
|
||||||
|
password: string
|
||||||
|
|
||||||
|
rememberMe?: boolean
|
||||||
|
}
|
||||||
|
|
||||||
|
/** @ex-zod-id 11@ */
|
||||||
|
export const exZodifiedSchema = z.object({
|
||||||
|
username: z.string().nonempty(),
|
||||||
|
password: z.string().nonempty(),
|
||||||
|
rememberMe: z.boolean().optional(),
|
||||||
|
});
|
||||||
|
registerZodifiedSchema(11, exZodifiedSchema);
|
||||||
|
```
|
||||||
|
|
||||||
|
This may not seem like much, but this is a _huge_ step toward our goal. We now have, at compile time, a mapping of interfaces to IDs and, at runtime, a mapping of IDs to schemata. So, we can use the compile-time map to modify all the places that reference the interface to set a runtime parameter with the ID of the schema for that interface. Then, at runtime, we can look up the schema using the ID. Bingo! No, how do we actually do that...
|
||||||
|
|
||||||
|
## Wrangling the AST
|
||||||
|
|
||||||
|
Now that we have our mapping, we need to make sure that a look-up is done whenever the type is referenced in code. That is, anywhere where we create a Validator\<LoginAttempt>, we should set the ID of the Zod schema for LoginAttempt on that Validator instance.
|
||||||
|
|
||||||
|
To accomplish this, I wrote a couple of transformer plugins for TypeScript. Now, tsc doesn't support plugins by default. (You may have seen plugins in the tsconfig.json for a project, but they are [plugins for the editor's language server](https://www.typescriptlang.org/tsconfig#plugins), not the compiler.) Luckily for us, again, there exists a fantastic open-source package to solve this problem. Ron S. maintains a package called [ts-patch](https://github.com/nonara/ts-patch) which, aptly, patches the tsc installation for a project to allow the project to specify compiler-plugins.
|
||||||
|
|
||||||
|
These plugins operate on the abstract syntax-tree of the TypeScript program. If you're not familiar with ASTs, they're basically the compiler's [internal representation of the program](https://en.wikipedia.org/wiki/Abstract_syntax_tree) you're compiling. They are data structures which can be manipulated and optimized. When you install a plugin, it is called repeatedly with the AST for each source file in the TypeScript project you're compiling. Importantly, the plugin can replace any of the nodes in the AST, or return a completely different one, in the file, and tsc will output the modified version instead of the original.
|
||||||
|
|
||||||
|
### First, Identify
|
||||||
|
|
||||||
|
The first plugin operates on the entire AST for each file in the project. Its job is to walk through each file's AST and [look for interface declarations](https://code.garrettmills.dev/Extollo/cc/src/branch/master/src/transformer.ts#L92) that we generated Zod schema for. When it finds one, it parses out the ID number we wrote into the file earlier and stores a mapping between that ID number and the symbol TypeScript uses to identify the interface internally.
|
||||||
|
|
||||||
|
Because we were the ones that wrote the Zod schema into the file, we can know that it -- and the call to register it with the global service -- are the last statements in the file. So, we can quickly look them up and parse out the ID from the registration call.
|
||||||
|
|
||||||
|
The TypeScript AST for the augmented file, at this point, looks something like this:
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
(As an aside, I used the ts-ast-viewer web app to generate this hierarchy. ts-ast-viewer is [a project started by David Sherret](https://github.com/dsherret/ts-ast-viewer) that allows you to visualize and explore the AST for any TypeScript program. It was invaluable in helping me figure out the structures for this project.)
|
||||||
|
|
||||||
|
By recursively walking the AST, we can look for the InterfaceDeclaration nodes. If we find one in a file, we can check the root of the file to see if an Identifier called exZodifiedSchema is defined. If so, we grab the last statement in the file (an ExpressionStatement containing the call to registerZodifiedSchema) and pull out its first argument, the ID number.
|
||||||
|
|
||||||
|
Once this transformer finishes, we've identified all of the interfaces for which we generated Zod schemata and created a mapping from the interface to the ID number we need at runtime.
|
||||||
|
|
||||||
|
### Then, Modify
|
||||||
|
|
||||||
|
The second plugin runs after the first has finished going through all the files in the project. This plugin's job is to [replace any NewExpression nodes](https://code.garrettmills.dev/Extollo/cc/src/branch/master/src/transformer.ts#L7) where the type parameters contain Zod-ified interfaces with an [IIFE](https://developer.mozilla.org/en-US/docs/Glossary/IIFE) that sets the \_\_exZodifiedSchemata property to an array of the ID numbers used to look up the schemata for those interfaces.
|
||||||
|
|
||||||
|
That is, the plugin transforms this:
|
||||||
|
|
||||||
|
```ts
|
||||||
|
new Validator<LoginAttempt>()
|
||||||
|
```
|
||||||
|
|
||||||
|
into this:
|
||||||
|
|
||||||
|
```ts
|
||||||
|
(() => {
|
||||||
|
const vI = new Validator<LoginAttempt>();
|
||||||
|
vI.__exZodifiedSchemata = [11];
|
||||||
|
return vI;
|
||||||
|
})()
|
||||||
|
```
|
||||||
|
|
||||||
|
And because the NewExpression is an expression just like the CallExpression is, anywhere where we have a NewExpression can instead have this CallExpression that wraps it with additional logic. The transformer is able to look up the ID numbers associated with the interfaces because the Identifier that references the interface in `new Validator<LoginAttempt>()` has the same symbol set on it as the InterfaceDeclaration we identified with the first plugin.
|
||||||
|
|
||||||
|
These symbols are created by something in the TypeScript compiler called the linker, which resolves all the identifier declarations and matches them up with the uses of those identifiers, even if the actual variables have been renamed along the way. So, we can use these symbols to match up uses of the interface with the declarations of the interfaces we care about.
|
||||||
|
|
||||||
|
_This_ is the magic sauce that finally makes it all work. After this plugin runs, the program TypeScript finishes compiling has all of the runtime type mappings linked up to the Validator instances based on which interface was specified when the Validator was instantiated.
|
||||||
|
|
||||||
|
# Conclusion
|
||||||
|
|
||||||
|
This was a long, and kind of hacky journey, but the end result is excellent. From the developer's perspective, they can type this:
|
||||||
|
|
||||||
|
```ts
|
||||||
|
const validator = new Validator<LoginAttempt>();
|
||||||
|
```
|
||||||
|
|
||||||
|
and, at runtime, the validator instance will have a Zod schema and will be able to parse data against the schema. No custom schema definition languages, no validator/schema mapping, nothing. To the developer, it's all just pure TypeScript, which was the goal all along.
|
||||||
|
|
||||||
|
The code for this feature is still very much work-in-progress, and I have to remove a lot of unused code and clean up what I keep, and probably rewrite part of it to be a less... jank. But, at the end of the day, I'm really happy with this "magic" feature that will help keep Extollo projects TypeScript-native, and easy to maintain.
|
||||||
|
|
||||||
|
You can find a minimal working example matching this post [here](https://code.garrettmills.dev/garrettmills/blog-runtime-types).
|
||||||
82
src/blog/posts/2022-01-26-xps-keyboard.md
Normal file
82
src/blog/posts/2022-01-26-xps-keyboard.md
Normal file
@@ -0,0 +1,82 @@
|
|||||||
|
---
|
||||||
|
layout: blog_post
|
||||||
|
title: The Ultimate Guide to Cleaning a Dell XPS 15 Keyboard
|
||||||
|
slug: Ultimate-Guide-to-Cleaning-Dell-XPS-15-Keyboard
|
||||||
|
date: 2022-01-26 00:01:00
|
||||||
|
tags: blog
|
||||||
|
permalink: /blog/2022/01/26/Ultimate-Guide-to-Cleaning-Dell-XPS-15-Keyboard/
|
||||||
|
blogtags:
|
||||||
|
- hardware
|
||||||
|
- dell
|
||||||
|
- keyboard
|
||||||
|
---
|
||||||
|
|
||||||
|
Two years ago, I switched laptops from a mid-range Asus laptop to the then-current Dell XPS 15 9500. A faster CPU/GPU and more RAM were the primary upgrades, but I also liked the keyboard on the XPS quite a lot.
|
||||||
|
|
||||||
|
Since then, I have used this machine as my daily driver for everything. As a student and occasional from-home worker, this laptop has seen a _lot_ of use. It has held up admirably, but one issue has developed in the last 3 or 4 months that has been the bane of my existence.
|
||||||
|
|
||||||
|
I've noticed that the keyboard has a tendency to accumulate dust and small debris over time, and this problem manifested itself in the most annoying possible way: some heavily-used keys started to require multiple presses or lots of force to register the keystroke. Namely, the worst offenders are the W, E, A, and left shift and control keys. This would result in annoying sentences like:
|
||||||
|
|
||||||
|
th quick bron fox jumps ovr th lzy littl puppy dog.
|
||||||
|
|
||||||
|
As a touch-typist, having to stop, backspace, and re-type sentences constantly while hitting the shift key with the force of god himself was getting really, _really_ old. I had tried blowing around the edges of the keys with canned air, but this produced little result.
|
||||||
|
|
||||||
|
I'm not sure if this problem is unique to me, but I wasn't able to find many other people online with the same experience. The few cases I _did_ find of people asking about cleaning the keyboard on this laptop contained unhelpful suggestions like removing the keyboard assembly entirely to clean it. This, while it would probably solve the problem and is well-documented in the service manual, requires basically a complete tear-down of the laptop.
|
||||||
|
|
||||||
|
However, after a bit of trial-and-error and reading the manual, I have found that the best way to clean the keys is to remove the key caps and blow the key wells out with compressed air. This requires a bit of finesse to do without breaking the key switches, so I decided to write-up perhaps the most niche how-to of all time.
|
||||||
|
|
||||||
|
So, with that said, here's the definitive guide on removing the key-caps from your Dell XPS 15 9500 series to clean under them.
|
||||||
|
|
||||||
|
### Step 1: Removing the Normal Key Caps
|
||||||
|
|
||||||
|
I'm going to go into a fair bit of detail here, since understanding the structure of the key caps is key to removing them without irreparably breaking them.
|
||||||
|
|
||||||
|
The normal keys on the laptop are membrane keys with plastic scissor switches. These switches are connected to the key caps with two grasp clips near the top of the key and two slots near the bottom of the key. Here's what I mean:
|
||||||
|
|
||||||
|
<img src="https://static.garrettmills.dev/assets/blog-images/key-cap-back.jpg" alt="Key cap back"/>
|
||||||
|
|
||||||
|
<center><small>The grabber attaches to the scissor switch while the slot slides under the edge of the switch.</small></center>
|
||||||
|
|
||||||
|
Here's the corresponding switch for this key cap. You can see the small bars to which the grabber attaches, and the small plastic flaps the slots slide under. When removing the keys, the biggest challenge is doing so without breaking the small plastic piece the slot slides under. Doing this can make it so that the key doesn't re-attach properly, which will necessitate replacing the entire scissor.
|
||||||
|
|
||||||
|
<img src="https://static.garrettmills.dev/assets/blog-images/key-switch.jpg" alt="Key switch">
|
||||||
|
|
||||||
|
<center><small>The grabber attaches to a small plastic bar on the inner key-switch, and the slot slides under the small plastic flap at the bottom of the switch.</small></center>
|
||||||
|
|
||||||
|
The safest/most reliable way I've found to remove the keys without breaking the plastic flaps on the switches is to use a small flathead screwdriver (the kind meant for electronics, really small). Use the screwdriver to lift one of the side edges of the key. Then, while holding it up, slide the screwdriver under the key cap. The goal here is to position the tip of the flathead between the key cap and the switch as close to the point where the grabber attaches to the plastic bar.
|
||||||
|
|
||||||
|
Then, use your finger to gently apply pressure to the bottom of the key. This will help prevent you from accidentally prying up the bottom of the key. Press down with the screwdriver to pop the plastic bar out of the grabber. You will have to do this once for each grabber on either side of the key cap. Be careful to position the screwdriver right next to the plastic beam each time. After un-clipping the two grabbers, the key cap should lift off with minimal resistance. The most important tip for this step is to NEVER force anything too much. Doing so means you'll likely break some delicate piece of plastic.
|
||||||
|
|
||||||
|
### Step 2: Removing the Special Key Caps
|
||||||
|
|
||||||
|
The modifier keys, by virtue of the keyboard layout, have special key switches and stabilizers under them since the key caps are larger. Removing these is pretty similar to the normal key caps, but with a couple extra considerations. The shift keys are a good example of this. For example:
|
||||||
|
|
||||||
|
<img src="https://static.garrettmills.dev/assets/blog-images/shift-key.jpg" alt="Shift key switch">
|
||||||
|
|
||||||
|
<center><small>Here, see that the shift key's switches are basically identical to the normal keys, there's just two of them. (Yes, I tried this on the right shift-key first. Who uses that anyway?)</small></center>
|
||||||
|
|
||||||
|
The easiest way I've found to clean under these keys is to use the screwdriver to detach the key cap from the top stabilizer bar (this is held on with the same kind of grabbers) then use the tip of the screwdriver to detach the grabbers from the switches, similarly to the normal keys. You don't need to fully remove the bottom stabilizer. If it seems like the key is still stuck on the bottom after un-clipping the top stabilizer and tops of the key switches, try laying the key back down (but don't re-clip it) and sliding it toward the track-pad a bit to un-slot the bottom plastic tabs. It should then turn down like the picture.
|
||||||
|
|
||||||
|
To re-attach the key cap, lay it back down on top of the stabilizer and press down over the three grabbers for the stabilizer. Then, press firmly over the top of each of the key switches to make sure their grabbers are re-attached. The left control key is similar:
|
||||||
|
|
||||||
|
<img src="https://static.garrettmills.dev/assets/blog-images/control-key.jpg" alt="Left control key">
|
||||||
|
|
||||||
|
<center><small>The left control key has stabilizers, but only a single switch, which is like a wider version of the normal switches.</small></center>
|
||||||
|
|
||||||
|
### Step 3: Cleaning
|
||||||
|
|
||||||
|
Once you've got the affected keys removed, you can clean the key wells using one of those cans of compressed air meant for electronics. Since these cans need to be used upright in order to not blast liquid on the device, I found it was useful to turn the laptop on its side to clean the keys.
|
||||||
|
|
||||||
|
When blowing them out, make sure to get around the edges of the key well and, specifically, in the area between the bottom of the key well and the plastic key switch.
|
||||||
|
|
||||||
|
### Step 4: Re-assembly
|
||||||
|
|
||||||
|
This is pretty straightforward. For the stabilized keys, lay the key so the grabbers are lined up with the stabilizer and press firmly over each of them until they re-click onto the stabilizer. Then, press down firmly over the area above each of the switches until all the grabbers are re-attached.
|
||||||
|
|
||||||
|
For the normal keys, simply place the key back on top of its switch, taking care to line up the grabbers, and press firmly on the key until all the connection points click into place.
|
||||||
|
|
||||||
|
### Results
|
||||||
|
|
||||||
|
For the most part, this was a very worthwhile venture. Since doing this, I haven't noticed any issues with the normal keys like W, E, and A, and the left control key has been working perfectly as well. Unfortunately, the left shift key still requires more force than usual to register a key stroke, though noticeably less than before. I'm not sure, but if I had to guess I would say this is because of the actual membrane button wearing out because it is centered on the key, but I almost always hit the key from the right edge while typing. It's subjective, but it feels like less force is required to register a key stroke when I depress the key from the left edge.
|
||||||
|
|
||||||
|
All in all, for the cost of a can of compressed air, this has very nearly solved the key issues I was having that were making the laptop very frustrating to use. I suspect this guide will mostly be used as a future reference for myself, but if there are any other Dell XPS users out there who have noticed this problem, perhaps this can help you out.
|
||||||
219
src/blog/posts/2022-04-18-k3s-on-proxmox.md
Normal file
219
src/blog/posts/2022-04-18-k3s-on-proxmox.md
Normal file
@@ -0,0 +1,219 @@
|
|||||||
|
---
|
||||||
|
layout: blog_post
|
||||||
|
title: "Rancher K3s: Kubernetes on Proxmox Containers"
|
||||||
|
slug: Rancher-K3s-Kubernetes-on-Proxmox-Container
|
||||||
|
date: 2022-04-18 00:01:00
|
||||||
|
tags: blog
|
||||||
|
permalink: /blog/2022/04/18/Rancher-K3s-Kubernetes-on-Proxmox-Container/
|
||||||
|
blogtags:
|
||||||
|
- hosting
|
||||||
|
- linux
|
||||||
|
- tutorial
|
||||||
|
- kubernetes
|
||||||
|
- virtualization
|
||||||
|
---
|
||||||
|
|
||||||
|
For a long time now, I've self-hosted most of my online services like calendar, contacts, e-mail, cloud file storage, my website, &c. The current iteration of my setup relies on a series of Ansible playbooks that install all of the various applications and configure them for use.
|
||||||
|
|
||||||
|
This has been really stable, and has worked pretty well for me. I deploy the applications to a set of LXC containers (read: [lightweight Linux VMs](https://linuxcontainers.org/lxd/)) on [Proxmox](https://www.proxmox.com/en/), a free and open-source hypervisor with an excellent management interface.
|
||||||
|
|
||||||
|
Recently, however, I've been re-learning Docker and the benefits of deploying applications using containers. Some of the big ones are:
|
||||||
|
|
||||||
|
- Guaranteed, reproducible environments. The application ships with its dependencies, ready to run.
|
||||||
|
- Portability. Assuming your environment supports the container runtime, it supports the application.
|
||||||
|
- Infrastructure-as-code. Much like Ansible playbooks, Docker lends itself well to managing the container environment using code, which can be tracked and versioned.
|
||||||
|
|
||||||
|
So, I have decided to embark on the journey of transitioning my bare-Linux Ansible playbooks to a set of Kubernetes deployments.
|
||||||
|
|
||||||
|
However, there are still some things I like about Proxmox that I'm not willing to give up. For one, the ability to virtualize physical machines (like my router or access point management portal) that can't be easily containerized. Having the ability to migrate "physical" OS installs between servers when I need to do maintenance on the hosts is super useful.
|
||||||
|
|
||||||
|
So, I will be installing Kubernetes on Proxmox, and I want to do it on LXC containers.
|
||||||
|
|
||||||
|
## What We're Building & Rationale
|
||||||
|
|
||||||
|
I'm going to deploy a Kubernetes cluster using [Rancher's K3s](https://rancher.com/docs/k3s/latest/en/) distribution on top of LXC containers.
|
||||||
|
|
||||||
|
K3s is a lightweight, production-grade Kubernetes distribution that simplifies the setup process by coming pre-configured with DNS, networking, and other tools out of the box. K3s also makes it fairly painless to join new workers to the cluster. This, combined with the relatively small scale of my deployment, makes it a pretty easy choice.
|
||||||
|
|
||||||
|
LXC containers, on the other hand, might seem a bit of an odd choice. Nearly every other article I found deploying K8s on Proxmox did so using full-fat virtual machines, rather than containers. This is certainly the lower-friction route, since it's procedurally the same as installing it on physical hosts. I went with LXC containers for two main reasons:
|
||||||
|
|
||||||
|
1. **LXC containers are _fast_. Like, almost as fast as bare metal.** Because LXC containers are virtualized at the kernel level, they are much lighter than traditional VMs. As such, they boot nearly instantly, run at nearly the same speed as the host kernel, and are much easier to reconfigure with more RAM/disk space/CPU cores on the fly.
|
||||||
|
2. **LXC containers are smaller.** Because the containers run on the kernel of the host, they need to contain a much smaller set of packages. This makes them require much less disk space out of the box (and, therefore, makes them easier to migrate).
|
||||||
|
|
||||||
|
So, to start out, I'm going to create 2 containers: one control node, and one worker node.
|
||||||
|
|
||||||
|
## Prerequisites
|
||||||
|
|
||||||
|
I'm going to assume that you (1) have a Proxmox server up and running, (2) have a [container template](https://us.lxd.images.canonical.com/images/rockylinux/8/amd64/default/) available on Proxmox, and (3) you have some kind of NFS file server.
|
||||||
|
|
||||||
|
This last one is important since we'll be giving our containers a relatively small amount of disk space. So, any volumes needed by Kubernetes pods can be created as [NFS mounts](https://kubernetes.io/docs/concepts/storage/volumes/#nfs).
|
||||||
|
|
||||||
|
You'll also want to set up `kubectl` and `helm` tools on your local machine.
|
||||||
|
|
||||||
|
## Creating the LXC Containers
|
||||||
|
|
||||||
|
Because our LXC containers need to be able to run Docker containers themselves, we need to do a bit of additional configuration out of the box to give them proper permissions.
|
||||||
|
|
||||||
|
The process for setting up the 2 containers is pretty much identical, so I'm only going to go through it once.
|
||||||
|
|
||||||
|
In the Proxmox UI, click "Create CT." Make sure you check the box to show advanced settings.
|
||||||
|
|
||||||
|
<img src="https://static.garrettmills.dev/assets/blog-images/ct-1.png"/>
|
||||||
|
|
||||||
|
<center><small>Make sure to uncheck "Unprivileged container."</small></center><br>
|
||||||
|
|
||||||
|
|
||||||
|
Fill in the details of the container. Make sure to uncheck the "Unprivileged container" checkbox. On the next screen, select your template of choice. I'm using a [Rocky Linux 8 image](https://us.lxd.images.canonical.com/images/rockylinux/8/amd64/default/).
|
||||||
|
|
||||||
|
<img src="https://static.garrettmills.dev/assets/blog-images/ct-2.png"/>
|
||||||
|
|
||||||
|
I elected to give each container a root disk size of 16 GiB, which is more than enough for the OS and K3s to run, as long as we don't put any volumes on the disk itself.
|
||||||
|
|
||||||
|
The CPU and Memory values are really up to whatever you have available on the host, and the workloads you intend to run on your K8s cluster. For mine, I gave 4 vCPU cores and 4 GiB of RAM per container.
|
||||||
|
|
||||||
|
<img src="https://static.garrettmills.dev/assets/blog-images/ct-3.png"/>
|
||||||
|
|
||||||
|
For the network configuration, be sure to set a static IP address for each node. Additionally, if you use a specific internal DNS server (which I highly recommend!), you should configure that on the next page.
|
||||||
|
|
||||||
|
<img src="https://static.garrettmills.dev/assets/blog-images/ct-4.png"/>
|
||||||
|
|
||||||
|
Finally, on the last page, make sure to uncheck the "Start after created" checkbox and then click finish. Proxmox will create the container.
|
||||||
|
|
||||||
|
### Additional Configuration
|
||||||
|
|
||||||
|
Now, we need to tweak a few things under-the-hood to give our containers proper permissions. You'll need to SSH into your Proxmox host as the `root` user to run these commands.
|
||||||
|
|
||||||
|
In the `/etc/pve/lxc` directory, you'll find files called `XXX.conf`, where `XXX` are the ID numbers of the containers we just created. Using your text editor of choice, edit the files for the containers we created to add the following lines:
|
||||||
|
|
||||||
|
```txt
|
||||||
|
lxc.apparmor.profile: unconfined
|
||||||
|
lxc.cgroup.devices.allow: a
|
||||||
|
lxc.cap.drop:
|
||||||
|
lxc.mount.auto: "proc:rw sys:rw"
|
||||||
|
```
|
||||||
|
|
||||||
|
> Note: It's important that the container is stopped when you try to edit the file, otherwise Proxmox's network filesystem will prevent you from saving it.
|
||||||
|
|
||||||
|
In order, these options (1) disable [AppArmor](https://www.apparmor.net/), (2) allow the container's cgroup to access all devices, (3) prevent dropping any capabilities for the container, and (4) mount `/proc` and `/sys` as read-write in the container.
|
||||||
|
|
||||||
|
Next, we need to publish the kernel boot configuration into the container. Normally, this isn't needed by the container since it runs using the host's kernel, but the Kubelet uses the configuration to determine various settings for the runtime, so we need to copy it into the container. To do this, first start the container using the Proxmox web UI, then run the following command on the Proxmox host:
|
||||||
|
|
||||||
|
```shell
|
||||||
|
pct push <container id> /boot/config-$(uname -r) /boot/config-$(uname -r)
|
||||||
|
```
|
||||||
|
|
||||||
|
Finally, **in each of the containers**, we need to make sure that `/dev/kmsg` exists. Kubelet uses this for some logging functions, and it doesn't exist in the containers by default. For our purposes, we'll just alias it to `/dev/console`. In each container, create the file `/usr/local/bin/conf-kmsg.sh` with the following contents:
|
||||||
|
|
||||||
|
```shell
|
||||||
|
#!/bin/sh -e
|
||||||
|
if [ ! -e /dev/kmsg ]; then
|
||||||
|
ln -s /dev/console /dev/kmsg
|
||||||
|
fi
|
||||||
|
|
||||||
|
mount --make-rshared /
|
||||||
|
```
|
||||||
|
|
||||||
|
This script symlinks `/dev/console` as `/dev/kmsg` if the latter does not exist. Finally, we will configure it to run when the container starts with a SystemD one-shot service. Create the file `/etc/systemd/system/conf-kmsg.service` with the following contents:
|
||||||
|
|
||||||
|
```txt
|
||||||
|
[Unit]
|
||||||
|
Description=Make sure /dev/kmsg exists
|
||||||
|
|
||||||
|
[Service]
|
||||||
|
Type=simple
|
||||||
|
RemainAfterExit=yes
|
||||||
|
ExecStart=/usr/local/bin/conf-kmsg.sh
|
||||||
|
TimeoutStartSec=0
|
||||||
|
|
||||||
|
[Install]
|
||||||
|
WantedBy=default.target
|
||||||
|
```
|
||||||
|
|
||||||
|
Finally, enable the service by running the following:
|
||||||
|
|
||||||
|
```shell
|
||||||
|
chmod +x /usr/local/bin/conf-kmsg.sh
|
||||||
|
systemctl daemon-reload
|
||||||
|
systemctl enable --now conf-kmsg
|
||||||
|
```
|
||||||
|
|
||||||
|
## Setting Up the Container OS & K3s
|
||||||
|
|
||||||
|
Now that we've got the containers up and running, we will set up Rancher K3s on them. Luckily, Rancher intentionally makes this pretty easy.
|
||||||
|
|
||||||
|
### Setup the control node
|
||||||
|
|
||||||
|
**Starting on the control node**, we'll run the following command to setup K3s:
|
||||||
|
|
||||||
|
```shell
|
||||||
|
curl -fsL https://get.k3s.io | sh -s - --disable traefik --node-name control.k8s
|
||||||
|
```
|
||||||
|
|
||||||
|
A few notes here:
|
||||||
|
|
||||||
|
- K3s ships with a [Traefik ingress controller](https://rancher.com/docs/k3s/latest/en/networking/#traefik-ingress-controller) by default. This works fine, but I prefer to use the industry-standard [NGINX ingress controller](https://kubernetes.github.io/ingress-nginx/) instead, so we'll set that up manually.
|
||||||
|
- I've specified the node name manually using the `--node-name` flag. This may not be necessary, but I've had problems in the past with K3s doing a reverse-lookup of the hostname from the IP address, resulting in different node names between cluster restarts. Specifying the name explicitly avoids that issue.
|
||||||
|
|
||||||
|
If all goes well, you should see an output similar to:
|
||||||
|
|
||||||
|
<img src="https://static.garrettmills.dev/assets/blog-images/ct-5.png"/>
|
||||||
|
|
||||||
|
Once this is done, you can copy the `/etc/rancher/k3s/k3s.yaml` as `~/.kube/config` on your local machine and you should be able to see your new (admittedly single node) cluster using `kubectl get nodes`!
|
||||||
|
|
||||||
|
> Note: you may need to adjust the cluster address in the config file from `127.0.0.1` to the actual IP/domain name of your control node.
|
||||||
|
|
||||||
|
<img src="https://static.garrettmills.dev/assets/blog-images/ct-6.png"/>
|
||||||
|
|
||||||
|
### Setup the worker node
|
||||||
|
|
||||||
|
Now, we need to join our worker node to the K3s cluster. This is also pretty straightforward, but you'll need the cluster token in order to join the node.
|
||||||
|
|
||||||
|
You can find this by running the following command **on the control node**:
|
||||||
|
|
||||||
|
```shell
|
||||||
|
cat /var/lib/rancher/k3s/server/node-token
|
||||||
|
```
|
||||||
|
|
||||||
|
Now, **on the worker node** run the following command to set up K3s and join the existing cluster:
|
||||||
|
|
||||||
|
```shell
|
||||||
|
curl -fsL https://get.k3s.io | K3S_URL=https://<control node ip>:6443 K3S_TOKEN=<cluster token> sh -s - --node-name worker-1.k8s
|
||||||
|
```
|
||||||
|
|
||||||
|
Again, note that we specified the node name explicitly. Once this process finishes, you should now see the worker node appear in `kubectl get nodes`:
|
||||||
|
|
||||||
|
<img src="https://static.garrettmills.dev/assets/blog-images/ct-7.png"/>
|
||||||
|
|
||||||
|
You can repeat this process for any additional worker nodes you want to join to the cluster in the future.
|
||||||
|
|
||||||
|
At this point, we have a functional Kubernetes cluster, however because we disabled Traefik, it has no ingress controller. So, let's set that up now.
|
||||||
|
|
||||||
|
## Setting up NGINX Ingress Controller
|
||||||
|
|
||||||
|
I used the `ingress-nginx/ingress-nginx` Helm chart to set up the NGINX ingress controller. To do this, we'll add the repo, load the repo's metadata, then install the chart:
|
||||||
|
|
||||||
|
```shell
|
||||||
|
helm repo add ingress-nginx https://kubernetes.github.io/ingress-nginx
|
||||||
|
helm repo update
|
||||||
|
helm install nginx-ingress ingress-nginx/ingress-nginx --set controller.publishService.enabled=true
|
||||||
|
```
|
||||||
|
|
||||||
|
Here, the `controller.publishService.enabled` setting tells the controller to publish the ingress service IP addresses to the ingress resources.
|
||||||
|
|
||||||
|
After the chart completes, you should see the various resources appear in `kubectl get all` output. (Note that it may take a couple minutes for the controller to come online and assign IP addresses to the load balancer.)
|
||||||
|
|
||||||
|
<img src="https://static.garrettmills.dev/assets/blog-images/ct-8.png"/>
|
||||||
|
|
||||||
|
We can test that the controller is up and running by navigating to any of the node's addresses in a web browser:
|
||||||
|
|
||||||
|
<img src="https://static.garrettmills.dev/assets/blog-images/ct-9.png"/>
|
||||||
|
|
||||||
|
In this case, we expect to see the 404, since we haven't configured any services to ingress through NGINX. The important thing is that we got a page served by NGINX.
|
||||||
|
|
||||||
|
## Conclusion
|
||||||
|
|
||||||
|
Now, we have a fully-functional Rancher K3s Kubernetes cluster, and the NGINX Ingress Controller configured and ready to use.
|
||||||
|
|
||||||
|
I've found this cluster to be really easy to maintain and scale. If you need to add more nodes, just spin up another LXC container (possibly on another physical host, possibly not) and just repeat the section to join the worker to the cluster.
|
||||||
|
|
||||||
|
I'm planning to do a few more write-ups chronicling my journey to learn and transition to Kubernetes, so stay tuned for more like this. The next step in this process is to configure [cert-manager](https://cert-manager.io/) to automatically generate Let's Encrypt SSL certificates and deploy a simple application to our cluster.
|
||||||
71
src/blog/posts/2022-07-12-openvpn-fedora.md
Normal file
71
src/blog/posts/2022-07-12-openvpn-fedora.md
Normal file
@@ -0,0 +1,71 @@
|
|||||||
|
---
|
||||||
|
layout: blog_post
|
||||||
|
title: Importing an OpenVPN Profile on Fedora 36
|
||||||
|
slug: Importing-OpenVPN-Profile-on-Fedora-36
|
||||||
|
date: 2022-07-12 00:01:00
|
||||||
|
tags: blog
|
||||||
|
permalink: /blog/2022/07/12/Importing-OpenVPN-Profile-on-Fedora-36/
|
||||||
|
blogtags:
|
||||||
|
- linux
|
||||||
|
- networking
|
||||||
|
---
|
||||||
|
|
||||||
|
To access my internal network & self-hosted services while I'm out of the house, I connect to an OpenVPN server running on my firewall.
|
||||||
|
|
||||||
|
I recently upgraded to Fedora 36 and discovered (the hard way) that the VPN was _broken_ and I couldn't re-import it. Turns out there are **multiple** bugs in the process that prevent the GUI from "just working" the way it's supposed to.
|
||||||
|
|
||||||
|
So, I read through the various bug reports so you don't have to. Here's how to import your OpenVPN connection file into Fedora 36.
|
||||||
|
|
||||||
|
My god was this ever a massive pain in the ass.
|
||||||
|
|
||||||
|
This assumes you have a `.ovpn` file, a `.key` file and a `.p12` file with your certificates. My VPN is using a "Password with Certificates" login system.
|
||||||
|
|
||||||
|
On Fedora 36+ we need to re-enable legacy crypto providers in OpenSSL. To do this, modify `/etc/ssl/openssl.cnf` and uncomment the lines:
|
||||||
|
|
||||||
|
```txt
|
||||||
|
[openssl_init]
|
||||||
|
providers = provider_sect
|
||||||
|
ssl_conf = ssl_module
|
||||||
|
|
||||||
|
[provider_sect]
|
||||||
|
default = default_sect
|
||||||
|
legacy = legacy_sect
|
||||||
|
|
||||||
|
[default_sect]
|
||||||
|
activate = 1
|
||||||
|
|
||||||
|
[legacy_sect]
|
||||||
|
activate = 1
|
||||||
|
```
|
||||||
|
|
||||||
|
Next, because of a bug with OpenVPN, we need to extract the CA certificate from our `.p12` into a separate file, since OpenVPN doesn't (currently) support reading it:
|
||||||
|
|
||||||
|
```shell
|
||||||
|
openssl pkcs12 -in my_certs.p12 -cacerts -nokeys -out my_ca.crt
|
||||||
|
```
|
||||||
|
|
||||||
|
Then, edit your `.ovpn` file to add the line:
|
||||||
|
|
||||||
|
```txt
|
||||||
|
ca my_ca.crt
|
||||||
|
```
|
||||||
|
|
||||||
|
Because of a bug in the NetworkManager GUI, we have to import the `.ovpn` configuration by hand.
|
||||||
|
|
||||||
|
```shell
|
||||||
|
sudo nmcli connection import type openvpn file my_config.ovpn
|
||||||
|
```
|
||||||
|
|
||||||
|
In the VPN GUI, edit the VPN and set your username and (optionally) the passwords. You may encounter a bug where the "Add" button is greyed out. This is because it wants you to enter _both_ the "Password" and "User key password" fields, but will not let you edit the "User key password" field. Currently, the only workaround is to click the little icon on the "User key password" field and click "Ask every time."
|
||||||
|
|
||||||
|
Yes, this is really annoying.
|
||||||
|
|
||||||
|
Oh, and on SELinux systems, you also need to update the security context of the certificate files to allow NetworkManager to access them. Most systems ship with a `home_cert_t` type that does the trick:
|
||||||
|
|
||||||
|
```
|
||||||
|
chcon -t home_cert_t vpn_millslan_net_glmdev.p12
|
||||||
|
chcon -t home_cert_t vpn_millslan_net_glmdev-tls.key
|
||||||
|
chcon -t home_cert_t ca.crt
|
||||||
|
```
|
||||||
|
|
||||||
|
Now, at long last, the VPN should activate.
|
||||||
290
src/blog/posts/2022-12-09-gcdt.md
Normal file
290
src/blog/posts/2022-12-09-gcdt.md
Normal file
@@ -0,0 +1,290 @@
|
|||||||
|
---
|
||||||
|
layout: blog_post
|
||||||
|
title: Generalized Commutative Data-Types
|
||||||
|
slug: Generalized-Commutative-Data-Types
|
||||||
|
date: 2022-12-09 00:01:00
|
||||||
|
tags: blog
|
||||||
|
permalink: /blog/2022/12/09/Generalized-Commutative-Data-Types/
|
||||||
|
blogtags:
|
||||||
|
- swarm
|
||||||
|
- patterns
|
||||||
|
- languages
|
||||||
|
- theory
|
||||||
|
---
|
||||||
|
|
||||||
|
> Disclaimer: after I started writing about this, I found [this paper from the Hydro project](https://hydro.run/papers/hydroflow-thesis.pdf) which presents a formulation of this idea using lattices & morphisms. What follows is my derivation of a similar technique, albeit significantly less formal. As far as I can tell, the Hydro paper does not separate "pseudo-commutative operations" instead opting to form reactive values which are re-computed as the PC operations are applied.
|
||||||
|
|
||||||
|
A "commutative data type" is one whose value is modified by a set of operations whose execution order is irrelevant. Such data types are useful in distributed & parallel systems which employ accumulator-style execution (i.e. many jobs perform a calculation then merge their result into a single, shared value).
|
||||||
|
|
||||||
|
What follows is a formulation of such a data type along with the structures required to define various operations over it.
|
||||||
|
|
||||||
|
## Naïve Commutative Data Types: A First Draft
|
||||||
|
|
||||||
|
Begin with a base value `v` of some type `T`.
|
||||||
|
|
||||||
|
There are `n` many jobs which act in parallel to perform commutative operations on `v`.
|
||||||
|
|
||||||
|
An operation on `v` is commutative if, for all operations `a` and `b` of type `(T -> T)`, `a (b v) = b (a v)`.
|
||||||
|
|
||||||
|
Each of the jobs produces an operation of the type `(T -> T)` which are collected.
|
||||||
|
|
||||||
|
The result is a value `(v : T)` and a set of commutative operations `(list (T -> T))`.
|
||||||
|
|
||||||
|
The list of operations is applied to the value, chained, producing a final value `v'`.
|
||||||
|
|
||||||
|
For example, if we have the list `((v -> v+1) :: (v -> v+4) :: nil)` and a base value of `0`, resolving the value gives `(v -> v+4) ((v -> v+1) 0) = 5`.
|
||||||
|
|
||||||
|
Importantly, because the order of the operations is irrelevant, we can apply the operations as they are received by the reducer (the piece of software accumulating the result), rather than collecting them all at once.
|
||||||
|
|
||||||
|
This allows for efficient reduction of a shared result variable by many distributed parallel jobs.
|
||||||
|
|
||||||
|
## Pseudo-Commutative Operations
|
||||||
|
|
||||||
|
Some operations, however, are not purely commutative. An example of this is multiplication.
|
||||||
|
|
||||||
|
If we introduce a job which produces a multiply operation into the above example, the list of operations is no longer commutative (herein referred to as asymmetric, or inconsistent).
|
||||||
|
|
||||||
|
However, the operation of multiplication is distributive in the sense that the TFAE:
|
||||||
|
|
||||||
|
`c * (a + b)`
|
||||||
|
`(c * a) + (c * b)`
|
||||||
|
|
||||||
|
Or, perhaps more interestingly for our case, TFAE:
|
||||||
|
|
||||||
|
`d * (a + b + c)`
|
||||||
|
`(d * c) + (d * (a + b))`
|
||||||
|
|
||||||
|
For example, say we receive the following operations in the following order. A `C:` prefix denotes a commutative operation, and a `P:` prefix denotes a pseudo-commutative operation:
|
||||||
|
|
||||||
|
```txt
|
||||||
|
C: (v -> v + 1)
|
||||||
|
C: (v -> v + 2)
|
||||||
|
P: (v -> v * 2)
|
||||||
|
C: (v -> v + 3)
|
||||||
|
```
|
||||||
|
|
||||||
|
If the base value of v is 0, we find that the "consistent" result should be `(0 + 1 + 2 + 3) * 2 = 12`.
|
||||||
|
|
||||||
|
```txt
|
||||||
|
(v -> v + 1) 0 => 1
|
||||||
|
(v -> v + 2) 1 => 3
|
||||||
|
(v -> v * 2) 3 => 6
|
||||||
|
|
||||||
|
(v -> v + 3) 6 => 9 (incorrect)
|
||||||
|
(v -> (v + 3) * 2) 6 => 18 (incorrect)
|
||||||
|
(v -> v + (3 * 2)) 6 => 12 (incorrect)
|
||||||
|
```
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
Because the commutative operation is opaque, there is no way of "pushing" the pseudo-commutative operation into the subsequent commutative operations, resulting in asymmetric results.
|
||||||
|
|
||||||
|
To address this, we re-define our naïve commutative operations like so:
|
||||||
|
|
||||||
|
A commutative operation is pair of the form `(T, T -> T -> T)` where the first element is the right-operand to a commutative binary operation. The second element is a function which takes the current accumulated value and the right operand and returns the new accumulated value.
|
||||||
|
|
||||||
|
This structure removes the opacity of the right operand in the operation, allowing us to push the pseudo-commutative operation into subsequent commutative operations.
|
||||||
|
|
||||||
|
We similarly re-define PC operations to have the form `(T, T -> T -> T)`.
|
||||||
|
|
||||||
|
Now, the same example using the new structure:
|
||||||
|
|
||||||
|
```txt
|
||||||
|
C: (1, l -> r -> l + r)
|
||||||
|
C: (2, l -> r -> l + r)
|
||||||
|
P: (2, l -> r -> l * r)
|
||||||
|
C: (3, l -> r -> l + r)
|
||||||
|
```
|
||||||
|
|
||||||
|
This results in:
|
||||||
|
|
||||||
|
```txt
|
||||||
|
(l -> r -> l + r) 0 1 => 1
|
||||||
|
(l -> r -> l + r) 1 2 => 3
|
||||||
|
(l -> r -> l * r) 3 2 => 6
|
||||||
|
(l -> r -> l + r) 6 ((l -> r -> l * r) 3 2) => 12
|
||||||
|
```
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
This is the fundamental insight of pseudo-commutative operations: if they are folded into the operands of all subsequent operations applied to the accumulator, the ordering of commutative and pseudo-commutative operations is irrelevant (insofar as the correct pseudo-commutative folds are performed).
|
||||||
|
|
||||||
|
Pseudo-commutative operations can even be chained to arrive at similarly-consistent results:
|
||||||
|
|
||||||
|
```txt
|
||||||
|
C: (2, l -> r -> l + r)
|
||||||
|
P: (2, l -> r -> l * r)
|
||||||
|
P: (3, l -> r -> l * r)
|
||||||
|
C: (2, l -> r -> l + r)
|
||||||
|
```
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
The expected result here is `(0 + 2 + 2) * 2 * 3 = 24`, and is computed as:
|
||||||
|
|
||||||
|
```txt
|
||||||
|
(l -> r -> l + r) 0 2 => 2
|
||||||
|
(l -> r -> l * r) 2 2 => 4
|
||||||
|
(l -> r -> l * r) 4 3 => 12
|
||||||
|
(l -> r -> l + r) 12 ((l -> r -> l * r) ((l -> r -> l * r) 2 2) 3) => 24
|
||||||
|
```
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
Another added benefit of this representation is the lack of specialization of the operations. Both commutative and pseudo-commutative operations can be represented as generic functions over two parameters, and those functions reused for each operation.
|
||||||
|
|
||||||
|
|
||||||
|
### Another GCDT: Sets
|
||||||
|
|
||||||
|
We will further formulate a GCDT over sets. A value of type `(set T)` is a collection of distinct, non-ordered values of type `T`.
|
||||||
|
|
||||||
|
A set has a characteristic commutative operation: append (or, more generally, union). Because sets have no order, the order in which unions are applied is irrelevant.
|
||||||
|
|
||||||
|
We use the `∪` operator to represent set union. So, `A ∪ B` is the union of sets `A` and `B`. For unions, the right operand is clear.
|
||||||
|
|
||||||
|
An operation, therefore, may be something like:
|
||||||
|
|
||||||
|
`(B, l -> r -> l ∪ r)`
|
||||||
|
|
||||||
|
Sets also have a clear pseudo-commutative operation: map (or set comprehension, if you prefer). This is the operation of applying a function `(T1 -> T2)` to every element in a set, resulting in a set of type `set T2`.
|
||||||
|
|
||||||
|
We represent set comprehension with the `map` function, which is of the form: `map :: (T1 -> T2) -> set T1 -> set T2`.
|
||||||
|
|
||||||
|
Here's an example, assuming we start with a base value `v = {}` (the empty set):
|
||||||
|
|
||||||
|
```txt
|
||||||
|
C: ({1}, l -> r -> l ∪ R)
|
||||||
|
C: ({1, 2}, l -> r -> l ∪ R)
|
||||||
|
P: ({}, l -> _ -> map (* 2) l)
|
||||||
|
C: ({3, 4}, l -> r -> l ∪ r)
|
||||||
|
```
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
Interestingly, `map` is a pseudo-commutative operation, but it is unary. To fit the structure, we implement it as a binary operation, but ignore the right operand, since it is always the one specified by the PC operation itself.
|
||||||
|
|
||||||
|
The expected result here is map `(* 2) ({1} U {1, 2} U {3, 4}) = {2, 4, 6, 8}`, and is computed as:
|
||||||
|
|
||||||
|
```txt
|
||||||
|
(l -> r -> l ∪ r) {} {1} => {1}
|
||||||
|
(l -> r -> l ∪ r) {1} {1, 2} => {1, 2}
|
||||||
|
(l -> _ -> map (* 2) l) {1, 2} {} => {2, 4}
|
||||||
|
(l -> r -> l ∪ r) {2, 4} ((l -> _ -> map (* 2) l) {3, 4} {}) => {2, 4, 6, 8}
|
||||||
|
```
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
## Pseudo-Commutative Operation Precedence
|
||||||
|
|
||||||
|
Now, let's introduce another pseudo-commutative operation over sets: filter (or set subtraction). Set subtraction removes all elements in the right operand from the left operand. For example, `{1, 2, 3} - {2} = {1, 3}`.
|
||||||
|
|
||||||
|
This can similarly be implemented using a function of type `(T -> bool)` which removes an element from `set T` unless the function returns true.
|
||||||
|
|
||||||
|
Based on the properties defined above, we can apply set subtraction in an example:
|
||||||
|
|
||||||
|
```txt
|
||||||
|
C: ({1, 4, 7}, l -> r -> l ∪ r)
|
||||||
|
P: ({}, l -> _ -> filter (< 5) l)
|
||||||
|
C: ({2, 5, 8}, l -> r -> l ∪ r)
|
||||||
|
```
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
The expected result here is filter `(< 5) ({1, 4, 7} U {2, 5, 8}) = {5, 7, 8}`, and is computed:
|
||||||
|
|
||||||
|
```txt
|
||||||
|
(l -> r -> l ∪ r) {} {1, 4, 7} => {1, 4, 7}
|
||||||
|
(l -> _ -> filter (< 5) l) {1, 4, 7} {} => {7}
|
||||||
|
(l -> r -> l ∪ r) {7} (filter (< 5) {2, 5, 8}) => {5, 7, 8}
|
||||||
|
```
|
||||||
|
|
||||||
|
Something problematic happens when we combine the two pseudo-commutative operators, however:
|
||||||
|
|
||||||
|
```txt
|
||||||
|
C: ({1, 4, 7}, l -> r -> l ∪ r)
|
||||||
|
P: ({}, l -> _ -> filter (< 5) l)
|
||||||
|
P: ({}, l -> _ -> map (* 2) l)
|
||||||
|
C: ({2, 5, 8}, l -> r -> l ∪ r)
|
||||||
|
```
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
Depending on whether we filter then map or map then filter, we arrive at `{10, 14, 16}` or `{8, 10, 14, 16}`, an asymmetric result. Unlike commutative operations, pseudo-commutative operations are not necessarily commutative _with each other_. Thus, the order in which pseudo-commutative operations are applies matters a great deal.
|
||||||
|
|
||||||
|
To resolve this inconsistency, we can require pseudo-commutative operations to be orderable such that, for a set of pseudo-commutative operations `s1`, there exists a list of these operations `s2` such that, `s2` has the form `{ s_i | s_i in s1 and forall j < i, s_i > s_j }`.
|
||||||
|
|
||||||
|
This gives precedence to pseudo-commutative operations, allowing their order to be resolved when they are "pushed" into subsequent commutative operands, but how do we handle the case when a greater PC operation is received _after_ a lesser PC operation is processed?
|
||||||
|
|
||||||
|
One approach to this is to specify the inverse of an operation, allowing it to be efficiently re-ordered.
|
||||||
|
|
||||||
|
For example, say we have an initial value `v0` and a PC operation `({}, pc1, pc1')` (where `pc1'` inverts `pc1`). If a subsequent PC operation with a greater precedence is applied, `({}, pc2, pc2')`, we compute the accumulator like so:
|
||||||
|
|
||||||
|
```txt
|
||||||
|
v = v0
|
||||||
|
v = pc1 v {}
|
||||||
|
v = pc1 (pc2 (pc1' v {}) {}) {}
|
||||||
|
```
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
This approach has a few benefits:
|
||||||
|
|
||||||
|
- First, by inverting and re-applying operations on-the-fly, we avoid the need to re-compute the accumulator all the way from the initial value. Instead, we only need to re-compute the operations which were PC and of a lower priority.
|
||||||
|
|
||||||
|
- Second, because of this rewinding approach, you will never have to rewind a PC operation of equal or greater precedence, as the operations of lesser precedence will always be "closest" to the end of the chain.
|
||||||
|
|
||||||
|
- Finally, commutative operations need not be re-applied during a rewind. Instead, the resultant value is treated as a pre-existing member of the set to be re-computed, since the commuted operation is preserved through the inverse of the PC operations.
|
||||||
|
|
||||||
|
However, there are a few drawbacks:
|
||||||
|
|
||||||
|
- Depending on the order in which the PC operations are received, the reducer may be forced to perform unoptimally-many re-computation.
|
||||||
|
|
||||||
|
- Fundamentally, some PC operations will lack easily computable inverses. For example `map sqrt`.
|
||||||
|
|
||||||
|
This last case is perhaps the most serious drawback to this approach, but it also has a fairly simple solution.
|
||||||
|
|
||||||
|
Because the entire domain of a PC operation is known when the operation is applied, we can trivially define an inversion of the operation by building a map from the range -> domain and storing that after the PC is applied (we call this "auto-inversion").
|
||||||
|
|
||||||
|
> This will require updating the mapping as the PC is applied to subsequent commutative operations, but such updates are considered relatively minor overhead.
|
||||||
|
|
||||||
|
This allows us to auto-invert any PC operation. The trade-off here is between time and space complexity.
|
||||||
|
|
||||||
|
In cases where the domain operand is small, but the inverse operation complex or impossible to define, defining the inverse as a mapping is more efficient.
|
||||||
|
|
||||||
|
However, in cases where the domain operand is large, the resultant auto-inverse may require a large amount of memory. In these cases, if the inverse operation is efficiently computable, defining an inverse function is more efficient.
|
||||||
|
|
||||||
|
|
||||||
|
## Applications
|
||||||
|
|
||||||
|
The motivation for this thought exercise came from [Swarm](https://github.com/swarmlang): a modular & massively-parallel distributed programming language I've been building w/ [Ethan Grantz](https://github.com/ephing) for the past year.
|
||||||
|
|
||||||
|
Swarm provides set-enumeration constructs which are natively parallelized and shared variables whose synchronization is handled by the runtime.
|
||||||
|
|
||||||
|
However, the language still relies on the developer to avoid asymmetric operations. For example:
|
||||||
|
|
||||||
|
```txt
|
||||||
|
enumeration<number> e = [1, 2, 3, 4, 5];
|
||||||
|
shared number acc = 0;
|
||||||
|
|
||||||
|
enumerate e as n {
|
||||||
|
if ( n % 2 == 0 ) {
|
||||||
|
acc += n;
|
||||||
|
} else {
|
||||||
|
acc *= n;
|
||||||
|
}
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
This example is somewhat contrived, but it is easy to see that the order in which the `enumerate` body executes for each element of `e` determines the value of `acc`.
|
||||||
|
|
||||||
|
This example could be made consistent by treating `acc` as the initial value of a GCDT of type `number`, and each execution of the body would submit one of two operations:
|
||||||
|
|
||||||
|
```txt
|
||||||
|
-- If n % 2 == 0:
|
||||||
|
C: (n, l -> r -> l + r)
|
||||||
|
|
||||||
|
-- Else:
|
||||||
|
P: (n, l -> r -> l * r)
|
||||||
|
```
|
||||||
|
|
||||||
|
Then, using the method described above, this result is always consistent, regardless of the order in which the jobs are executed.
|
||||||
157
src/blog/posts/2023-03-20-ai-proofs.md
Normal file
157
src/blog/posts/2023-03-20-ai-proofs.md
Normal file
@@ -0,0 +1,157 @@
|
|||||||
|
---
|
||||||
|
layout: blog_post
|
||||||
|
title: Adventures in AI-assisted proof generation
|
||||||
|
slug: Adventures-in-AI-assisted-proof-generation
|
||||||
|
date: 2023-03-20 00:08:00
|
||||||
|
tags: blog
|
||||||
|
permalink: /blog/2023/03/20/Adventures-in-AI-assisted-proof-generation/
|
||||||
|
blogtags:
|
||||||
|
- chatgpt
|
||||||
|
- languages
|
||||||
|
- theory
|
||||||
|
---
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Look, I know LLMs and ChatGPT are the big industry-consuming buzz-words right now. I'm as skeptical of the "ChatGPT is going to replace `{industry}`" mentality as anyone, but it's clear that _something_ is coming and it's going to change the world, whether we like it or not.
|
||||||
|
|
||||||
|
Believe it or not, until a couple days ago, I had largely ignored the LLM craze. Sure, it's cool, and it's coming, but it's not relevant to what I do day-to-day _yet_. Recently, however, I was reading the excellent [Web Curios blog by Matt Muir](https://webcurios.co.uk/webcurios-17-03-23/), and something he said stood out to me:
|
||||||
|
|
||||||
|
> “But Matt!”, I hear you all cry, “what does this MEAN? Please tell me what I should think about all this breathless, breakneck upheaval and change and…is it…progress?” To which the obvious answer is “lol like I know, I’m just some webmong” (and also “is it normal to hear these voices?”), but to which I might also say “This is the point at which I strongly believe it’s important you start to learn how to use this stuff, because I reckon you’ve got maximum a year in which reasonable competence with this sort of kit makes you look genuinely smart”, but also “GPT4 is literally Wegovy for white collar office workers, insofar as everyone will be using it to give themselves a professional tweakup but people will be a bit cagey about admitting it”
|
||||||
|
|
||||||
|
So, begrudgingly, I fired up OpenAI, handed over my e-mail and phone number, and started playing around with ChatGPT. I tried all the normal things ("generate a Bash script to do X", "write a new cold open for X show in the style of Y"), but I stumbled upon something interesting, rather by accident.
|
||||||
|
|
||||||
|
## ~~The~~ A Problem With Coq
|
||||||
|
|
||||||
|
(If you are familiar with Coq/provers, feel free to skip my basic and somewhat controversial explanation in this section.)
|
||||||
|
|
||||||
|
When I was in school, one of my areas of focus was formal methods, a computing discipline that concerns itself with the rigorous theory of programming languages and programs. One of the major applications of FM is so-called "verified computing" -- computing which has been formally proven correct. Applications of verified computing are legion, including security-sensitive environments -- like embedded devices, drones, and spacecraft -- but have gradually extended to broader applications like secure boot and mainstream languages like TypeScript.
|
||||||
|
|
||||||
|
The FM community has coalesced around a series of tools called interactive theorem provers which provide syntax for modeling theorems, composing them, and constructing proofs over them. The lab I worked with used one of the most popular, the [Coq Proof Assistant](https://coq.inria.fr/). Coq contains a rigid, functional programming language and a less-rigid proof scripting language which operates over it.
|
||||||
|
|
||||||
|
Despite advocates claims that provers are ["going mainstream any year now,"](http://adam.chlipala.net/) these proof assistants struggle in general -- and Coq in particular -- with a lack of automation. Quite extensive knowledge is required to prove even [basic lemmas](https://stackoverflow.com/questions/48416538/writing-proofs-of-simple-arithmetic-in-coq), largely due to the strict nature of the runtime and its unwillingness to make assumptions which may turn out to be logically inconsistent. Undoubtedly, this will improve with time as automations and layers of abstraction are introduced to the system, but it remains the largest barrier to entry for programmers wanting to write provably-correct code.
|
||||||
|
|
||||||
|
## ~~The~~ A Problem with ChatGPT
|
||||||
|
|
||||||
|
Of the many [technical](https://www.forbes.com/sites/bernardmarr/2023/03/03/the-top-10-limitations-of-chatgpt), [societal](https://www.theguardian.com/technology/2023/mar/18/chatgpt-said-i-did-not-exist-how-artists-and-writers-are-fighting-back-against-ai), and [moral](https://www.scu.edu/ethics-spotlight/generative-ai-ethics/a-moral-panic-chatgpt-and-the-gamification-of-education/) quandaries spurred by ChatGPT is its complete willingness to fabricate lies disguised as the truth. Because all the LLM is doing is generating what it deems the statistically most likely response, it may be incorrect. However, its advanced language _syntax_ model enables it to present its incorrect information in an eloquent, tidy, convincing format (the boon of misinformation farms, but I digress...).
|
||||||
|
|
||||||
|
Obviously proving whether or not the output of ChatGPT is correct _generally_ is an insane and likely impossible proposition, there's an interesting rabbit hole to be found on the boundary of AI-generated code snippets and Coq proofs. A wedding between the embodiment of industry buzzwords and something which is decidedly not. You see, it turns out that one of the niche languages that ChatGPT understands reasonably well is Ltac, the proof scripting language built into Coq.
|
||||||
|
|
||||||
|
## Factorial
|
||||||
|
|
||||||
|
A common baby's-second-proof in Coq is the factorial problem. Model the factorial function as a recursive function and an inductive relation, then prove that the two models are equivalent. So, I started by asking ChatGPT:
|
||||||
|
|
||||||
|
> "Show me an implementation of the factorial algorithm in Coq."
|
||||||
|
|
||||||
|
This is what it came up with:
|
||||||
|
|
||||||
|
```text
|
||||||
|
Fixpoint factorial (n : nat) : nat :=
|
||||||
|
match n with
|
||||||
|
| O => 1
|
||||||
|
| S n' => n * factorial n'
|
||||||
|
end.
|
||||||
|
```
|
||||||
|
|
||||||
|
This compiled in Coq and, upon inspection, this appears correct. Impressive. Next, I asked it something a bit more challenging:
|
||||||
|
|
||||||
|
> "Now, show me an implementation of the factorial algorithm in Coq using an inductive relation instead of a recursive function."
|
||||||
|
|
||||||
|
```text
|
||||||
|
Inductive factorial : nat -> nat -> Prop :=
|
||||||
|
| fact_base : factorial O 1
|
||||||
|
| fact_step : forall n m, factorial n m -> factorial (S n) ((S n) * m).
|
||||||
|
```
|
||||||
|
|
||||||
|
This also compiled fine, and I think this is much more impressive. The LLM produced a reasonable model of a factorial system, "inferring" what I meant by "inductive relation." ChatGPT also helpfully provided an example lemma for this relation:
|
||||||
|
|
||||||
|
```text
|
||||||
|
Example factorial_5 : factorial 5 120.
|
||||||
|
Proof.
|
||||||
|
apply (fact_step 4 24).
|
||||||
|
apply (fact_step 3 6).
|
||||||
|
apply (fact_step 2 2).
|
||||||
|
apply (fact_step 1 1).
|
||||||
|
apply fact_base.
|
||||||
|
Qed.
|
||||||
|
```
|
||||||
|
|
||||||
|
This is where things started to get interesting to me. I didn't even ask for an example, but in its quest to explain itself, ChatGPT generated Ltac code demonstrating an example usage of its inductive relation. I was curious, so I chucked it into [Coqtail](https://github.com/whonore/Coqtail) and tried it out:
|
||||||
|
|
||||||
|
```text
|
||||||
|
Unable to unify "factorial 0 1" with "factorial 1 1".
|
||||||
|
```
|
||||||
|
|
||||||
|
Hm. It looks like the ChatGPT proof missed a step between `apply (fact_step 1 1).` and `apply fact_base.` Adding in an `apply (fact_step O 1).` between them pops it out.
|
||||||
|
|
||||||
|
After my initial doubts in ChatGPT's "knowledge" of Coq, I started to get a little more ambitious:
|
||||||
|
|
||||||
|
> "Now, show me a proof that the inductive relation is equivalent to the recursive function definition."
|
||||||
|
|
||||||
|
```text
|
||||||
|
Lemma factorial_equiv : forall n, factorial n (factorial_rec n).
|
||||||
|
Proof.
|
||||||
|
induction n.
|
||||||
|
- apply fact_base.
|
||||||
|
- simpl.
|
||||||
|
apply (fact_step n (factorial_rec n)).
|
||||||
|
apply IHn.
|
||||||
|
Qed.
|
||||||
|
|
||||||
|
Lemma factorial_rec_equiv : forall n, factorial_rec n = factorial n.
|
||||||
|
Proof.
|
||||||
|
intros n.
|
||||||
|
unfold factorial_rec.
|
||||||
|
induction n.
|
||||||
|
- reflexivity.
|
||||||
|
- simpl.
|
||||||
|
rewrite IHn.
|
||||||
|
apply (fact_step n (factorial n)).
|
||||||
|
apply factorial_equiv.
|
||||||
|
Qed.
|
||||||
|
```
|
||||||
|
|
||||||
|
Now, that's something! There are so many interesting things about this response. First of all, it inferred that a "proof of equivalence" would require a lemma in both directions. Second of all, the Ltac it generated has _structure_ and is organized using bullets, not just a large blob of proof commands. Even more, it was able to account for the conflict between the recursive `factorial` function it generated and the inductive `factorial` relation it generated, renaming the recursive function `factorial_rec`.
|
||||||
|
|
||||||
|
To my amazement, the `factorial_equiv` popped out without any modifications, and the bullets structure even made sense. The `factorial_rec_equiv` lemma however... has some problems. For one, neither `factorial_rec` nor `factorial` is single-parameter, so the lemma was missing an entire universal variable. I rewrote the theorem manually, to give the LLM a hint:
|
||||||
|
|
||||||
|
> "Modify the `factorial_req_equiv` lemma to prove: `forall n m, factorial_rec n = m -> factorial n m"`
|
||||||
|
|
||||||
|
```text
|
||||||
|
Lemma factorial_rec_equiv : forall n m, factorial_rec n = m -> factorial n m.
|
||||||
|
Proof.
|
||||||
|
intros n m H.
|
||||||
|
rewrite <- H.
|
||||||
|
clear H.
|
||||||
|
induction n.
|
||||||
|
- apply fact_base.
|
||||||
|
- simpl.
|
||||||
|
apply (fact_step n (factorial_rec n)).
|
||||||
|
apply IHn.
|
||||||
|
reflexivity.
|
||||||
|
Qed.
|
||||||
|
```
|
||||||
|
|
||||||
|
Aside from the fact that the last `reflexivity` is not needed, this theorem popped out perfectly. Now, I not only had an AI-generated factorial relation, but I had an AI-generated proof that that relation was correct (or at least equivalent to the recursive definition I defined as "correct").
|
||||||
|
|
||||||
|
This is absolutely amazing to me, but of course there are caveats to note:
|
||||||
|
|
||||||
|
- First, this is an exceedingly simple example, and as you add libraries, lemmas, and other code it would become difficult to provide ChatGPT enough context for it to generate coherent results.
|
||||||
|
- Second, ChatGPT's generation of these outputs was _slow_. So slow, in fact, that several times when I returned to the tab from something else, it had timed-out and needed to be retried. But, it did finish.
|
||||||
|
- Third, obviously my definition of "proven correctness" assumes logical consistency in the proof engine, but in this line of work that's a fair assumption to make.
|
||||||
|
|
||||||
|
Importantly, however, were I proving this for the first time, it would probably take _more_ time to work my way through the various proof tactics and commands.
|
||||||
|
|
||||||
|
I think this has a few interesting implications: first, for theorem proving. The barrier to entry for theorem provers is largely an issue with how difficult it is to construct proof tactics. If ChatGPT generates a string of proof tactics which pops out a proof goal, then one of two things has happened. Either, (1) it has found a set of tactics which genuinely proves the statement, or (2) it has found a logical inconsistency -- a bug -- in the proof engine.
|
||||||
|
|
||||||
|
The latter is the stuff of nightmares, and is generally not much of an issue in mature tools like Coq. The former, however, is really cool. Imagine a utopic world where you can hand a proof and a universe of statements to your theorem prover and, rather than requiring carefully constructed hints, [the `auto` tactic](https://coq.inria.fr/refman/proofs/automatic-tactics/auto.html) could use an LLM to generate the tactics for the proof. Even if it fails, it provides the user a much closer starting point than writing the proof from scratch.
|
||||||
|
|
||||||
|
There's a much broader and more interesting implication here, though. One problem with ChatGPT-generated code is that it may simply be completely wrong. So, what if we make ChatGPT _prove_ that its code is correct? This, combined with Coq's [excellent extractors](https://coq.inria.fr/refman/addendum/extraction.html), could free up not just FM people, but even normal developers to create verified implementations while spending less time in the weeds with the prover. `auto` on crack.
|
||||||
|
|
||||||
|
## Conclusion?
|
||||||
|
|
||||||
|
I honestly don't know how I feel about ChatGPT in general, or even how it behaves in this particular situation. Maybe it simply does not scale to the complexity necessary to be useful. Maybe a rise in AI-generated Ltac will poison [yet another vibrant FOSS community](https://joemorrison.medium.com/death-of-an-open-source-business-model-62bc227a7e9b). It really feels like there's a social reckoning on the way.
|
||||||
|
|
||||||
|
Regardless, it seems like ChatGPT's usefulness as a programming tool may extend -- just a bit -- to the world of verified programming.
|
||||||
|
|
||||||
|
(I [created a repo](https://code.garrettmills.dev/garrettmills/blog-chatgpt-coq) where you can find the generated Coq code as well as the output from my ChatGPT session.)
|
||||||
88
src/blog/posts/2023-04-28-terminal-emulators.md
Normal file
88
src/blog/posts/2023-04-28-terminal-emulators.md
Normal file
@@ -0,0 +1,88 @@
|
|||||||
|
---
|
||||||
|
layout: blog_post
|
||||||
|
title: Down the Rabbit Hole of Linux Terminal Emulators
|
||||||
|
slug: down-the-rabbit-hole-of-linux-terminal-emulators
|
||||||
|
date: 2023-04-28 00:20:00
|
||||||
|
tags: blog
|
||||||
|
permalink: /blog/2023/04/28/down-the-rabbit-hole-of-linux-terminal-emulators/
|
||||||
|
blogtags:
|
||||||
|
- linux
|
||||||
|
---
|
||||||
|
|
||||||
|
For years now, I've used an excellent drop-down terminal emulator called [Guake](http://guake-project.org/index.html) -- a GNOME port of Quake. It supported every feature I needed: Wayland (mostly), tabs, custom shortcuts, custom shell, transparency, and a toggle command (`guake -t`) that plays nice w/ custom keybinds in GNOME.
|
||||||
|
|
||||||
|
Recently, however, I've found myself wanting something akin to Vim's visual mode in Guake (specifically the ability to copy-paste chunks of output like file names into the command).
|
||||||
|
|
||||||
|
While Guake doesn't support this, the [`screen` command](https://www.gnu.org/software/screen/) does:
|
||||||
|
|
||||||
|
1. Press `C-a [` to enter copy mode.
|
||||||
|
2. Move the cursor to the text you want to copy and press space.
|
||||||
|
3. Highlight the text you want to copy and press space again to copy the selection and return to normal mode.
|
||||||
|
4. Press `C-a ]` to paste at the cursor.
|
||||||
|
|
||||||
|
This is exactly what I wanted. Now, I just need to make `screen fish --login` my default shell in Guake. This presented a couple issues.
|
||||||
|
|
||||||
|
First, because I am using a GUI-based terminal emulator, I want to use its scroll-back functionality. By default, `screen` buffers output and provides its own implementation of scroll-back.
|
||||||
|
|
||||||
|
Luckily, this was easy enough to change with a line in my `~/.screenrc`:
|
||||||
|
|
||||||
|
```text
|
||||||
|
termcapinfo xterm*|xs|rxvt|terminal ti@:te@
|
||||||
|
```
|
||||||
|
|
||||||
|
The next problem was... not so easy to solve.
|
||||||
|
|
||||||
|
<center><br><img src="https://static.garrettmills.dev/assets/blog-images/terminal-1.png"><br>
|
||||||
|
<small>Guake's preferences dialog.</small><br><br></center>
|
||||||
|
|
||||||
|
While Guake allows you to select a custom shell, it does _not_ allow you to specify a custom command. I need to do this because `screen` does not register itself as a shell w/ the system.
|
||||||
|
|
||||||
|
Sooooo using Guake is out of the question if I want to use my new Franken-screen shell setup.
|
||||||
|
|
||||||
|
## GNOME Terminator
|
||||||
|
|
||||||
|
<center><br><img src="https://static.garrettmills.dev/assets/blog-images/terminal-2.png"><br>
|
||||||
|
<small>GNOME Terminator's preferences dialog.</small><br><br></center>
|
||||||
|
|
||||||
|
I tried several other shell emulators, but they all had game-breaking issues or missing functionality for me personally. Most notably, I actually got [GNOME's Terminator](https://gnome-terminator.org/) tiling emulator completely set up to my liking. When I tried to replace my keyboard shortcut for Guake, thought, I discovered that there's no CLI flag to "toggle" the current window to make it behave like a drop-down shell.
|
||||||
|
|
||||||
|
## Tilix
|
||||||
|
|
||||||
|
<center><br><img src="https://static.garrettmills.dev/assets/blog-images/terminal-3.png"><br>
|
||||||
|
<small>Tilix's Quake mode, Wayland edition.</small><br><br></center>
|
||||||
|
|
||||||
|
I also tried [Tilix](https://gnunn1.github.io/tilix-web/), another tiling emulator. Like Terminator, it had preferences for everything I like to customize in Guake -- it even has a Quake mode that makes it behave as a drop-down shell! Unlike Terminator, it has a CLI flag to show/hide the overhead window.
|
||||||
|
|
||||||
|
Unfortunately, Tilix has limited support for Wayland in Quake mode. I was able to get it to work by updating my keyboard shortcut to use the `env GDK_BACKEND=x11` environment.
|
||||||
|
|
||||||
|
<center><br><img src="https://static.garrettmills.dev/assets/blog-images/terminal-4.png"><br>
|
||||||
|
<small>Ah, Wayland, how we love thee.</small><br><br></center>
|
||||||
|
|
||||||
|
This too has its own problem. One feature of Guake that I use a lot is the "Open on monitor with cursor" setting. This lets me quickly move Guake between monitors as I'm working.
|
||||||
|
|
||||||
|
There is a [well-known limitation](https://www.reddit.com/r/linux/comments/qid50x/does_anyone_else_feel_that_wayland_is_taking_away/) of Wayland where Wayland apps are restricted from accessing certain information about the displays and other running applications. This prevents Tilix from being able to determine which monitor the active cursor is on.
|
||||||
|
|
||||||
|
This problem is not unique to Tilix. I use the excellent [Ulauncher](https://ulauncher.io/) tool. On X.org, Ulauncher opens on the monitor where the cursor is. On Wayland, it picks the monitor seemingly at random.
|
||||||
|
|
||||||
|
While searching around for this issue, I stumbled upon [a comment](https://github.com/gnunn1/tilix/issues/2049#issuecomment-1140499490) on an issue in the Tilix GitHub which pointed me to a GNOME extension of all things called DDTerm.
|
||||||
|
|
||||||
|
## DDTerm
|
||||||
|
<center><br><img src="https://static.garrettmills.dev/assets/blog-images/terminal-5.png"><br>
|
||||||
|
<small>DDTerm and its glorious, glorious preference dialog.</small><br><br></center>
|
||||||
|
|
||||||
|
[DDTerm](https://github.com/ddterm/gnome-shell-extension-ddterm) is "Another Drop Down Terminal Extension for GNOME Shell" and has managed to be a perfect drop-in replacement for Guake for me. It supports, among other things:
|
||||||
|
|
||||||
|
- A custom command to use for new sessions (`screen fish --login`)
|
||||||
|
- A DBus command to toggle a single instance (`gdbus call --session --dest org.gnome.Shell --object-path /org/gnome/Shell/Extensions/ddterm --method com.github.amezin.ddterm.Extension.Toggle`)
|
||||||
|
- Transparency
|
||||||
|
- Customizable keyboard shortcuts/color theme/fonts
|
||||||
|
|
||||||
|
Plus, because it's running in GNOME directly, it can access the compositor to correctly determine the monitor where the mouse lives!
|
||||||
|
|
||||||
|
## Conclusion
|
||||||
|
This rabbit hole was probably 2 hours of on-again-off-again tinkering w/ various terminal emulators, but I have landed on:
|
||||||
|
|
||||||
|
- Shell: Fish Shell wrapped in GNU Screen
|
||||||
|
- Emulator: DDTerm
|
||||||
|
- Custom `.screenrc` to enable literal scrollback
|
||||||
|
- Custom GNOME keybinding to toggle DDTerm
|
||||||
125
src/blog/posts/2024-04-22-PHP-CVE-2024-2961.md
Normal file
125
src/blog/posts/2024-04-22-PHP-CVE-2024-2961.md
Normal file
@@ -0,0 +1,125 @@
|
|||||||
|
---
|
||||||
|
layout: blog_post
|
||||||
|
title: "Mitigating the iconv Vulnerability for PHP (CVE-2024-2961)"
|
||||||
|
slug: Mitigating-the-iconv-Vulnerability-for-PHP-CVE-2024-2961
|
||||||
|
date: 2024-04-22 20:54:06
|
||||||
|
tags: blog
|
||||||
|
permalink: /blog/2024/04/22/Mitigating-the-iconv-Vulnerability-for-PHP-CVE-2024-2961/
|
||||||
|
blogtags:
|
||||||
|
- devops
|
||||||
|
- linux
|
||||||
|
- webdev
|
||||||
|
- hosting
|
||||||
|
---
|
||||||
|
|
||||||
|
Recently, [CVE-2024-2961](https://www.openwall.com/lists/oss-security/2024/04/18/4) was released which identifies a buffer overflow vulnerability in GNU libc versions 2.39 and older when converting charsets to certain Chinese Extended encodings.
|
||||||
|
|
||||||
|
This vulnerability affects PHP when `iconv` is used to translate request encodings to/from the affected charsets and has the potential to be wide-ranging (e.g. the latest `wordpress:apache` image has `iconv` with the vulnerable charsets enabled).
|
||||||
|
|
||||||
|
Obviously, the best mitigation is to update to a patched version of `glibc`. However, if you are unable to (or it's not available on your OS yet), you can mitigate this issue by disabling the affected charsets in `gconv`.
|
||||||
|
|
||||||
|
I had a really hard time finding information on how to check for and mitigate this issue at the OS-level (possibly because the researcher who discovered the CVE is presently _teasing_ details about the PHP exploit for his [talk at a conference](https://www.offensivecon.org/speakers/2024/charles-fol.html)... 3 weeks after the CVE was announced. 🙄)
|
||||||
|
|
||||||
|
I've collected my notes here, in case they might be useful for someone else.
|
||||||
|
|
||||||
|
## Check if your OS is vulnerable
|
||||||
|
|
||||||
|
```shell
|
||||||
|
ldd --version
|
||||||
|
```
|
||||||
|
|
||||||
|
The first line of the linker version info should include the version of glibc (either as `GLIBC` or `GNU libc`).
|
||||||
|
|
||||||
|
Example from Debian 12:
|
||||||
|
|
||||||
|
```text
|
||||||
|
ldd (Debian GLIBC 2.36-9+deb12u4) 2.36
|
||||||
|
Copyright (C) 2022 Free Software Foundation, Inc.
|
||||||
|
This is free software; see the source for copying conditions. There is NO
|
||||||
|
warranty; not even for MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE.
|
||||||
|
Written by Roland McGrath and Ulrich Drepper.
|
||||||
|
```
|
||||||
|
|
||||||
|
Example from Rocky Linux 9:
|
||||||
|
|
||||||
|
```text
|
||||||
|
ldd (GNU libc) 2.34
|
||||||
|
Copyright (C) 2021 Free Software Foundation, Inc.
|
||||||
|
This is free software; see the source for copying conditions. There is NO
|
||||||
|
warranty; not even for MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE.
|
||||||
|
Written by Roland McGrath and Ulrich Drepper.
|
||||||
|
```
|
||||||
|
|
||||||
|
> You can also use your package manager to check (for example, `rpm -q glibc`).
|
||||||
|
|
||||||
|
If you are using `glibc` 2.39 or older, then the `ISO-2022-CN-EXT` encodings are vulnerable for your system's `iconv` and `gconv`.
|
||||||
|
|
||||||
|
## Check for bad encodings
|
||||||
|
|
||||||
|
Check if the vulnerable encodings are enabled in `iconv`:
|
||||||
|
|
||||||
|
```shell
|
||||||
|
iconv -l | grep -E 'CN-?EXT'
|
||||||
|
```
|
||||||
|
|
||||||
|
If they are, you will see an output like:
|
||||||
|
|
||||||
|
```
|
||||||
|
ISO-2022-CN-EXT//
|
||||||
|
ISO2022CNEXT//
|
||||||
|
```
|
||||||
|
|
||||||
|
## Disable bad encodings
|
||||||
|
|
||||||
|
We can modify the `gconv-modules` configuration to disable the affected charsets:
|
||||||
|
|
||||||
|
```shell
|
||||||
|
cd /usr/lib/x86_64-linux-gnu/gconv
|
||||||
|
```
|
||||||
|
|
||||||
|
> This might be in slightly different locations for exotic systems. Try `find / -name gconv-modules`.
|
||||||
|
|
||||||
|
Disable the offending encodings in the `gconv-modules` config file. This will either be in `gconv-modules` directly, or in something like `gconv-modules.d/gconv-modules-extra.conf`:
|
||||||
|
|
||||||
|
```shell
|
||||||
|
cd gconv-modules.d
|
||||||
|
cat gconv-modules-extra.conf | grep -v -E 'CN-?EXT' > gconv-modules-extra-patched.conf
|
||||||
|
mv gconv-modules-extra-patched.conf gconv-modules-extra.conf
|
||||||
|
cd ..
|
||||||
|
```
|
||||||
|
|
||||||
|
Remove the cache file if present:
|
||||||
|
|
||||||
|
```shell
|
||||||
|
rm gconv-modules.cache
|
||||||
|
```
|
||||||
|
|
||||||
|
> You can regenerate that cache file using [`iconvconfig(8)`](https://www.man7.org/linux/man-pages/man8/iconvconfig.8.html).
|
||||||
|
|
||||||
|
Then re-check for the vulnerable encodings:
|
||||||
|
|
||||||
|
```shell
|
||||||
|
iconv -l | grep -E 'CN-?EXT'
|
||||||
|
```
|
||||||
|
|
||||||
|
There should be no output from this command.
|
||||||
|
|
||||||
|
### Docker
|
||||||
|
|
||||||
|
For those using Docker images, here's a convenient `Dockerfile` blurb:
|
||||||
|
|
||||||
|
```dockerfile
|
||||||
|
# Disable vulnerable iconv encodings (CVE-2024-2961)
|
||||||
|
RUN cd /usr/lib/x86_64-linux-gnu/gconv/gconv-modules.d \
|
||||||
|
&& cat gconv-modules-extra.conf | grep -v -E 'CN-?EXT' > gconv-modules-extra-patched.conf \
|
||||||
|
&& mv gconv-modules-extra-patched.conf gconv-modules-extra.conf \
|
||||||
|
&& rm -f ../gconv-modules.cache \
|
||||||
|
&& iconvconfig \
|
||||||
|
&& iconv -l | grep -E 'CN-?EXT' && exit 1 || true
|
||||||
|
```
|
||||||
|
|
||||||
|
That last line contains one of my favorite Dockerfile tricks (`check-something && exit 1 || true`) -- your Docker build will fail if the vulnerable charsets are enabled.
|
||||||
|
|
||||||
|
> A previous version of this post kept `gconv-modules-extra-patched.conf`. Thanks to Anonymous for pointing out that a subsequent RPM update could re-introduce the file.
|
||||||
|
|
||||||
|
> A previous version of this post indicated that `glibc` versions < 2.39 were vulnerable. Thanks to Geert for noting that 2.39 is also vulnerable.
|
||||||
23
src/blog/posts/2024-05-15-commencement-photos.md
Normal file
23
src/blog/posts/2024-05-15-commencement-photos.md
Normal file
@@ -0,0 +1,23 @@
|
|||||||
|
---
|
||||||
|
layout: blog_post
|
||||||
|
title: "Miscellaneous Photos from Commencement 2024"
|
||||||
|
slug: Miscellaneous-Photos-from-Commencement-2024
|
||||||
|
date: 2024-05-15 20:54:06
|
||||||
|
tags: blog
|
||||||
|
permalink: /blog/2024/05/15/Miscellaneous-Photos-from-Commencement-2024/
|
||||||
|
blogtags:
|
||||||
|
- photography
|
||||||
|
---
|
||||||
|
|
||||||
|
I'm not particularly skilled or versatile, but I enjoy dabbling in amateur photography occasionally. Last weekend was Commencement at the University of Kansas. My partner and some of our friends graduated, so I got to play paparazzi for the weekend. Here are a couple miscellaneous photos that I particularly enjoyed:
|
||||||
|
|
||||||
|
<img src="https://static.garrettmills.dev/assets/blog-images/IMG_2655.jpg">
|
||||||
|
|
||||||
|
<center><small>A photo of some spring tulips, taken outside the <a href="https://places.ku.edu/fountain/chi-omega-fountain" target="_blank">Chi Omega fountain</a> on campus.</small></center>
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
<img src="https://static.garrettmills.dev/assets/blog-images/IMG_3365.jpg">
|
||||||
|
|
||||||
|
<center><small>My personal favorite from the weekend: a photo of one of the performance planes, taken outside the stadium as the commencement ceremony was starting.</small></center>
|
||||||
|
|
||||||
90
src/blog/posts/2024-08-11-Flight-Log.md
Normal file
90
src/blog/posts/2024-08-11-Flight-Log.md
Normal file
@@ -0,0 +1,90 @@
|
|||||||
|
---
|
||||||
|
layout: blog_post
|
||||||
|
title: An Irrational Flight Log
|
||||||
|
slug: Flight-Log
|
||||||
|
date: 2024-08-11 20:00:00
|
||||||
|
tags: blog
|
||||||
|
permalink: /blog/2024/08/11/Flight-Log/
|
||||||
|
blogtags:
|
||||||
|
- off-topic
|
||||||
|
---
|
||||||
|
|
||||||
|
> <b><small>Disclaimer</small></b><br>
|
||||||
|
> I'm well aware that this is an _extraordinarily_ privileged First-World Problem™ to have. This page is a bit tongue-in-cheek.
|
||||||
|
|
||||||
|
Lately, I've been flying back and forth between Indianapolis and Kansas City about once a month for work. Because I'm picky about _when_ I leave, I've wound up taking the same pair of United flights from Indianapolis to Chicago to Kansas City, then back later in the week.
|
||||||
|
|
||||||
|
It _feels_ like every time I take a trip with United, there's a problem. Is there evidence to support this?
|
||||||
|
|
||||||
|
<img src="https://static.garrettmills.dev/assets/blog-images/united.png">
|
||||||
|
<center>RIP travelers in 2007. Imagine a full 1/3 of flights on an airline arriving late.</center>
|
||||||
|
|
||||||
|
No, not really.[^1] Am I irrationally mad about it anyway? Yes. Driving from Indianapolis to Kansas City takes about 12 hours. So, I'm starting this page mostly to help myself track my time spent on flying and flight-related activities.
|
||||||
|
|
||||||
|
Some nomenclature:
|
||||||
|
|
||||||
|
- IND is the Indianapolis International Airport
|
||||||
|
- ORD is Chicago O'Hare International Airport
|
||||||
|
- MCI is Kansas City International Airport
|
||||||
|
|
||||||
|
<br>
|
||||||
|
|
||||||
|
<table>
|
||||||
|
<tr>
|
||||||
|
<th>Trip Date</th>
|
||||||
|
<th>Flight</th>
|
||||||
|
<th>Notes</th>
|
||||||
|
<th>Okay?</th>
|
||||||
|
</tr>
|
||||||
|
<tr>
|
||||||
|
<td>Aug 9th, 2024</td>
|
||||||
|
<td>ORD to IND</td>
|
||||||
|
<td>(This was the flight that inspired this page. For context, ORD to IND is a 36-minute flight.) Boarding started 15 minutes late because of prep on the plane. Right before push-off, they discovered a hydraulic leak. This took an hour to fix. When we were finally pushed off, it took an additional 30 minutes to taxi and take off because of the line. That's almost 2 additional hours for a 36 minute flight.</td>
|
||||||
|
<td>❌</td>
|
||||||
|
</tr>
|
||||||
|
<tr>
|
||||||
|
<td>Aug 9th, 2024</td>
|
||||||
|
<td>MCI to ORD</td>
|
||||||
|
<td>Flight left on time and landed pretty much on time.</td>
|
||||||
|
<td>✅</td>
|
||||||
|
</tr>
|
||||||
|
<tr>
|
||||||
|
<td>Aug 5th, 2024</td>
|
||||||
|
<td>ORD to MCI</td>
|
||||||
|
<td>Luckily my connection was only 3 gates away (and was already boarding when I got there). This flight pushed off on time but was then delayed for 20 minutes due to lightning (admittedly, this isn't United's fault, so I'll count it).</td>
|
||||||
|
<td>✅</td>
|
||||||
|
</tr>
|
||||||
|
<tr>
|
||||||
|
<td>Aug 5th, 2024</td>
|
||||||
|
<td>IND to ORD</td>
|
||||||
|
<td>Flight left on time, and landed on time at ORD, but because of construction and traffic, we sat on the tarmac for 20 minutes after landing.</td>
|
||||||
|
<td>❌</td>
|
||||||
|
</tr>
|
||||||
|
<tr>
|
||||||
|
<td>July 12th, 2024</td>
|
||||||
|
<td>ORD to IND</td>
|
||||||
|
<td>I was worried I was going to miss this flight because of delays w/ the MCI to ORD flight, but luckily it was delayed by a couple of hours as well. I waited an hour at the gate.</td>
|
||||||
|
<td>❌</td>
|
||||||
|
</tr>
|
||||||
|
<tr>
|
||||||
|
<td>July 12th, 2024</td>
|
||||||
|
<td>MCI to ORD</td>
|
||||||
|
<td>Flight was delayed by an hour and a half because our incoming flight crew was delayed.</td>
|
||||||
|
<td>❌</td>
|
||||||
|
</tr>
|
||||||
|
<tr>
|
||||||
|
<td>July 8th, 2024</td>
|
||||||
|
<td>ORD to MCI</td>
|
||||||
|
<td>I had to sprint from concourse A to concourse C in 15 minutes because of my IND to ORD flight, but no issues other than that.</td>
|
||||||
|
<td>✅</td>
|
||||||
|
</tr>
|
||||||
|
<tr>
|
||||||
|
<td>July 8th, 2024</td>
|
||||||
|
<td>IND to ORD</td>
|
||||||
|
<td>Plane was delayed 40 minutes. We had to change gates at IND because our original 737 MAX had "broken seats." (Side note: I was talking with people boarding the flight who had to stay overnight in a hotel because of issues the prior day.)</td>
|
||||||
|
<td>❌</td>
|
||||||
|
</tr>
|
||||||
|
</table>
|
||||||
|
|
||||||
|
|
||||||
|
[^1]: From the <a href="https://www.bts.gov/topics/airlines-and-airports/annual-airline-time-rankings-2003-2023" target="_blank">Bureau of Transportation Statistics</a>.
|
||||||
99
src/blog/posts/2025-01-07-default-apps-2024.md
Normal file
99
src/blog/posts/2025-01-07-default-apps-2024.md
Normal file
@@ -0,0 +1,99 @@
|
|||||||
|
---
|
||||||
|
layout: blog_post
|
||||||
|
title: Default Apps 2024
|
||||||
|
slug: Default-Apps-2024
|
||||||
|
date: 2025-01-07 20:00:00
|
||||||
|
tags: blog
|
||||||
|
permalink: /blog/2025/01/07/Default-Apps-2024/
|
||||||
|
blogtags:
|
||||||
|
- linux
|
||||||
|
- software
|
||||||
|
---
|
||||||
|
|
||||||
|
> *Copying [Tracy Durnell's](https://tracydurnell.com/) homework by way of [Matt C](https://mattcool.tech/posts/default-apps-2023/), [Chris Coyier](https://chriscoyier.net/2023/11/25/default-apps-2023/), and [drew dot shoes](https://drew.shoes/posts/default-apps-2024/). (Some fantastic RSS subscriptions, btw.)*
|
||||||
|
|
||||||
|
For a few years now, I've been trying to hone my free-as-in-freedom software garden. I really like to properly own my data and make it reside on my server(s), which is a bit of an edge case sometimes. I tweak this list a lot less frequently than I did even a year ago, but it's always fun to share and look back at past years.
|
||||||
|
|
||||||
|
Since a lot of this list is up for fine-tuning, I thought it'd be fun to include how happy I am with each solution:
|
||||||
|
|
||||||
|
* 👍 = pretty much set in stone
|
||||||
|
* ❓ = I have a solution, but it might change
|
||||||
|
* 😕 = I don't have a good solution
|
||||||
|
|
||||||
|
|
||||||
|
**📨** Mail Client - Thunderbird on both desktop and mobile (!!). I've been waiting for a "[Thunderbird on Android](https://blog.thunderbird.net/2022/06/revealed-thunderbird-on-android-plans-k9/)" for a literal decade, and this year a polished version was finally ready. I was already using K-9 Mail, so the switch was seamless. (👍)
|
||||||
|
|
||||||
|
|
||||||
|
**📮** Mail Server - [iRedMail](https://www.iredmail.org/) running on a VPS. Cheap and easy to update. Probably worth its own post at some point. (👍)
|
||||||
|
|
||||||
|
|
||||||
|
**📝** Notes - For the last year or so I've been self-hosting [Outline](https://www.getoutline.com/). It's quite good, and supports a lot of polished features like publishing and real-time collab. Biggest con: No mobile app/offline access (though the web version is good on mobile). (❓)
|
||||||
|
|
||||||
|
|
||||||
|
**✅** To-Do - This year I started tracking my to-dos as normal calendar events, and it's worked really well. I put an item on my calendar the date it's due and set reminder notifications for, say a week before, a day before, and an hour before. (👍)
|
||||||
|
|
||||||
|
|
||||||
|
**📷** Photo Shooting - My Pixel 6a most of the time, sometimes my [Canon EOS Rebel XT](https://garrettmills.dev/blog/2024/05/15/Miscellaneous-Photos-from-Commencement-2024/). (👍)
|
||||||
|
|
||||||
|
|
||||||
|
**🎨** Photo Editing - Very occasionally, I use [darktable](https://www.darktable.org/) for grading and [GIMP](https://www.gimp.org/) for touch-ups. (👍)
|
||||||
|
|
||||||
|
|
||||||
|
**📆** Calendar/Contacts Server - [Radicale](https://radicale.org/). Another absolute champion that's easy to update. Simple, and I've never had any problems with it. (👍)
|
||||||
|
|
||||||
|
|
||||||
|
**📆** Calendar Client - [GNOME Calendar](https://apps.gnome.org/Calendar/) on desktop and Google Calendar on mobile. I use [DAVx5](https://www.davx5.com/) to sync my calendar/contacts on mobile. I'd love to get away from Google Calendar, but the UI is just by far the best option. (Desktop: 👍, Mobile: ❓)
|
||||||
|
|
||||||
|
|
||||||
|
**📁** Cloud File Storage - [Seafile](https://www.seafile.com/). I switched from NextCloud a few years ago and never looked back. It's simple, lightning fast, and reliable. I sync all of my xdg-home folders (Desktop, Documents, Pictures, &c.) no problem. My one gripe is that the mobile app is… okay. Sharing and integration w/ the Android filesystem never seem to work for me, but the core functionality (downloading/uploading files) works great. (👍)
|
||||||
|
|
||||||
|
|
||||||
|
**📖** RSS - [NewsFlash](https://apps.gnome.org/NewsFlash/) on desktop and [Feeder](https://github.com/spacecowboy/Feeder) on mobile. Currently I periodically sync my [OPML file](https://garrettmills.dev/blog/feeds) from my desktop to my phone, but I'd like to find a self-hosted solution to sync my feeds/saves/reads. I've used [CommaFeed](https://github.com/Athou/commafeed) in the past, and might return to it. (❓)
|
||||||
|
|
||||||
|
|
||||||
|
**🌐** Browser - [Firefox](https://www.mozilla.org/en-US/firefox/) on both desktop and mobile. As a professional software engineer, I still legitimately prefer Firefox's developer tools, multi-account containers, and overall UX, despite [Mozilla's best efforts](https://www.jwz.org/blog/2024/10/mozillas-ceo-doubles-down-on-them-being-an-advertising-company-now/). (, though I'm watching [Ladybird](https://ladybird.org))
|
||||||
|
|
||||||
|
|
||||||
|
**💬** Chat - By volume, Android Messages, Rocket.Chat (professionally), and Discord. One of my intentions for 2025 is to start moving to E2EE for everything (hopefully the increasing adoption of RCS will help with that). (❓)
|
||||||
|
|
||||||
|
|
||||||
|
**🔖** Bookmarks - [MarkMark](https://garrettmills.dev/markmark) (shameless plug). I'm in the process of switching over from my Outline note full of random links. (**👍**)
|
||||||
|
|
||||||
|
|
||||||
|
**📑** Read It Later - Currently, the aforementioned Outline note full of random links. One of my intentions for 2025 is to build a Firefox extension to automatically add read-it-later articles to my MarkMark file. (❓)
|
||||||
|
|
||||||
|
|
||||||
|
**📜** Word Processing - Personal: I've been doing most of my drafts in Outline documents, which works pretty well (especially since I can download them as markdown). Professional: Google Docs. (**👍**)
|
||||||
|
|
||||||
|
|
||||||
|
**📈** Spreadsheets - Personal: LibreOffice Calc. Professional: Google Sheets. Both are fine, though the ever-encroaching Gemini features in Sheets are getting a bit old. (❓)
|
||||||
|
|
||||||
|
|
||||||
|
**📊** Presentations - Personal: none. Professional: Google Slides. Exceedingly infrequently. (:thumbs_up:)
|
||||||
|
|
||||||
|
|
||||||
|
**🍴** Meal Planning - A whiteboard on the fridge, and a folder full of saved recipes a text documents. Sometimes it's about knowing when to take it offline. :wink: (👍)
|
||||||
|
|
||||||
|
|
||||||
|
**🛒** Shopping Lists - We keep a running list on the fridge whiteboard, which I transfer to a physical piece of paper when I go to the store. Way easier to use in-situ. (👍)
|
||||||
|
|
||||||
|
|
||||||
|
**💰** Budgeting and Personal Finance - The venerable [GnuCash](https://gnucash.org/). It's not the greatest user experience, but I wanted something FOSS, offline that doesn't require a server, and that I can trust to be around in 5 years. It works. (👍)
|
||||||
|
|
||||||
|
|
||||||
|
📰 News - I get most of my news via RSS. I have a lot of thoughts about it (maybe another blog post at some point). I've been trying to seek out more local news when possible. For example, I read [WFYI Indianapolis](https://www.wfyi.org/) and [NUVO Indianapolis](https://www.nuvo.net/). (👍)
|
||||||
|
|
||||||
|
|
||||||
|
**🎵** Music - Spotify. I rely on Discover Weekly *a lot* to find new music, though I don't love supporting Spotify. I've been thinking about taking another page out of [Tracy Durnell's book](https://tracydurnell.com/2025/01/03/2024-in-music/) in 2025. (❓)
|
||||||
|
|
||||||
|
|
||||||
|
**🎤** Podcasts - Also Spotify :( I know it's not great, but the few times I do listen to podcasts, I want to make use of Android Auto. (😕)
|
||||||
|
|
||||||
|
|
||||||
|
**🔐** Password Management - [Vaultwarden](https://github.com/dani-garcia/vaultwarden). I recommend Bitwarden/Vaultwarden to anyone looking for a good password manager. The browser extensions and mobile apps are first class, fully-encrypted, and keep a local copy (read: backup) of your vault on every device in case the server is unavailable. (👍)
|
||||||
|
|
||||||
|
|
||||||
|
**🧑💻** Code Editor - [IntelliJ IDEA Ultimate](https://www.jetbrains.com/idea/). I've used JetBrains IDEs both personally and professionally for about a decade now. I still think they have the best Intellisense and code navigation of any editor. Lately, I worry JetBrains has a bit of a Mozilla thing going with Fleet, though. I have no interest in a "next-gen" VS Code clone, but I would like remote development (JetBrains Gateway) to have better latency and a file-bar that doesn't freeze every time I go more than 2 layers deep. This is something VS Code excels at. (❓)
|
||||||
|
|
||||||
|
|
||||||
|
**✈️** VPN - [Wireguard](https://www.wireguard.com/). I made the switch last year from OpenVPN and I wish I'd done it sooner. It's *fast*. And, once properly configured, it'll run for ages. For my personal setup, I use [wg-easy](https://github.com/wg-easy/wg-easy) to great effect. (👍)
|
||||||
79
src/blog/posts/2025-01-09-Fun-With-Bookmarks.md
Normal file
79
src/blog/posts/2025-01-09-Fun-With-Bookmarks.md
Normal file
@@ -0,0 +1,79 @@
|
|||||||
|
---
|
||||||
|
layout: blog_post
|
||||||
|
title: Fun With Bookmarks
|
||||||
|
slug: Fun-With-Bookmarks
|
||||||
|
date: 2025-01-09 07:30:00
|
||||||
|
tags: blog
|
||||||
|
permalink: /blog/2025/01/09/Fun-With-Bookmarks/
|
||||||
|
blogtags:
|
||||||
|
- meta
|
||||||
|
- markmark
|
||||||
|
---
|
||||||
|
|
||||||
|
A while back, I started experimenting with a way of storing my bookmarks (read: my random text document full of untitled links) as a Markdown document, which I affectionately dubbed "[MarkMark](https://garrettmills.dev/markmark)" — a standard format for links, descriptive text, tags, and dates. Here's a sample from [my bookmarks](https://garrettmills.dev/links):
|
||||||
|
|
||||||
|
```markdown
|
||||||
|
# Cycling
|
||||||
|
|
||||||
|
- Spencer McCullough's bike trip to 48 national parks (+ an excellent bike camping map)
|
||||||
|
- https://onelongtrip.bike/
|
||||||
|
- https://gobikecamping.com/map
|
||||||
|
- Helmet Wind Straps
|
||||||
|
- https://youtube.com/shorts/8-Ph6CjKopY?si=QGVb7HrKT7FejGZI
|
||||||
|
- A love letter to bicycle maintenance and repair
|
||||||
|
- https://tegowerk.eu/posts/bicycle-repair/
|
||||||
|
```
|
||||||
|
|
||||||
|
I published MarkMark v1.0 back in November 2023 (!!), but I never fully started using it for two reasons:
|
||||||
|
|
||||||
|
|
||||||
|
1. I wanted to be able to organize and syndicate links by date, and
|
||||||
|
2. more importantly, adding a link meant committing a change to my [website code](https://code.garrettmills.dev/garrettmills/www/src/commit/c852fbd628bfd7903ef9814becfb8d8e77dfcb40/src/app/resources/markmark/links.mark.md) and fully re-deploying it every time.
|
||||||
|
|
||||||
|
Since I've been feeling the urge to tinker, I've made some changes to help with both.
|
||||||
|
|
||||||
|
|
||||||
|
## v1.1: It's all about that date
|
||||||
|
|
||||||
|
I love RSS and the indie-web ([see here](https://garrettmills.dev/blog/feeds)) and one of the main ways I discover new parts of it is thanks to fantastic link blogs like [Jason Kottke](https://kottke.org/) and [LinkMachineGo](https://www.timemachinego.com/linkmachinego/).
|
||||||
|
|
||||||
|
While I'm not running a link blog, and I have no delusions of readership, I like the idea of being able to syndicate my bookmarks via RSS.
|
||||||
|
|
||||||
|
This would work if my MarkMark document was organized by date, but, since it's not, an [update to the spec](https://xkcd.com/927/) was required. MarkMark v1.1 introduces a date notation for links:
|
||||||
|
|
||||||
|
```markdown
|
||||||
|
- A fantastic link title goes here (2025-01-09)
|
||||||
|
- https://example.com/home
|
||||||
|
```
|
||||||
|
|
||||||
|
The dates are optional, but give me a way to track when links were added to my bookmarks, which means I can now generate an [RSS feed](https://code.garrettmills.dev/garrettmills/www/src/commit/c852fbd628bfd7903ef9814becfb8d8e77dfcb40/src/app/services/blog/MarkMarkBlog.service.ts#L28).
|
||||||
|
|
||||||
|
My current implementation publishes feed entries for each link in my bookmarks that has a date, along with the title of its section, description, and URL(s).
|
||||||
|
|
||||||
|
|
||||||
|
<center>You can find these feeds in RSS, Atom, and JSON format on the <a href="https://garrettmills.dev/links">links page</a>.</center>
|
||||||
|
|
||||||
|
|
||||||
|
## Reading links from Outline
|
||||||
|
|
||||||
|
The deployment process for my website isn't *difficult*, but it does require a [Docker build](https://code.garrettmills.dev/garrettmills/www/src/branch/master/package.json#L44), which turns out to be too much work every time I just want to save a link.
|
||||||
|
|
||||||
|
As I mentioned in my [Default Apps 2024](https://garrettmills.dev/blog/2025/01/07/Default-Apps-2024/) post, my knowledge base of choice is the self-hosted version of [Outline](https://www.getoutline.com/), which I have found to be quite good. One of the things I like about Outline is that it stores document contents as Markdown internally and has a well-documented REST API (you can probably see where this is going).
|
||||||
|
|
||||||
|
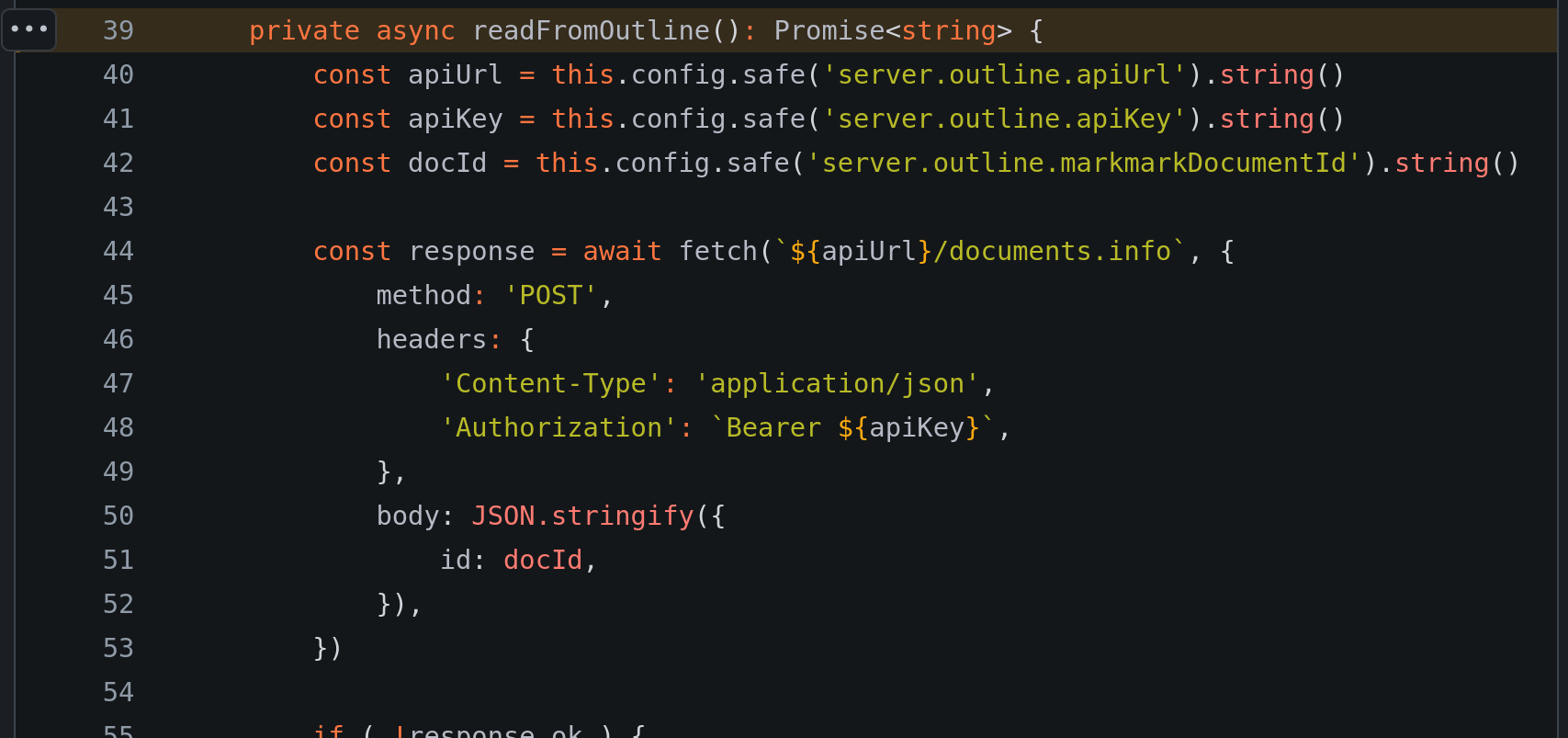
|
||||||
|
|
||||||
|
The `/links` page now, with some caching, reads my MarkMark document directly from my Outline instance rather than a hard-coded file. Since MarkMark is just a subset of the [CommonMark](https://commonmark.org/) syntax, I can make use of Outline's markdown formatting for headers, lists, links, and code:
|
||||||
|
|
||||||
|
|
||||||
|
<center>I did have to add some special logic to undo the escaping Outline adds to the MarkMark preamble (the lines starting with <code>[//]:</code>).</center>
|
||||||
|
|
||||||
|
This is *way* easier to add to/organize day-to-day, and the updates get pulled into my website and RSS feeds automatically.
|
||||||
|
|
||||||
|
|
||||||
|
## Future Work
|
||||||
|
|
||||||
|
I want to build a Firefox extension for saving links to my MarkMark document in Outline — something where I can click the button on a webpage and pre-fill the title, description, and today's date. It'll have to use the Outline API to load the list of categories and tags, then my [MarkMark parser collection](https://code.garrettmills.dev/garrettmills/www/src/branch/master/src/markmark) to add the link and update the Outline document automatically.
|
||||||
|
|
||||||
|
More generally, I like this idea of building semi-dynamic integrations using Outline. I already use it to draft all my blog posts before publishing. It reminds me a lot of the [halcyon days of the old web](https://en.wikipedia.org/wiki/Microsoft_FrontPage). I wonder if there are any other uses.
|
||||||
|
|
||||||
|
One of my themes for 2025 is to work smaller — build smaller projects, write smaller (more frequent) posts, read smaller sources, &c. The MarkMark spec and its small collection of tools feels like a good way to start.
|
||||||
Reference in New Issue
Block a user